
LLMを使った開発をしていると、必ずぶつかる壁がある。
それは「このAIの回答、本当に合っているのか」という品質評価の問題だ。
直感で「なんとなく良い」「なんとなく悪い」と判断していると、評価基準が属人化してしまう。
単なる感覚での評価を続けていると、後からプロンプトを改善したときに、本当に良くなったのかどうかがわからなくなる。
結果として、リリース前に人間がすべての出力を読み直すという地獄の作業が発生するわけだ。
今回は、1人開発者でも明日から実践できる、LLMの出力評価を仕組み化する10の具体的な手法を紹介する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
評価基準の言語化と設計
AIにAIを評価させる前に、まずは人間側で基準を作ることが不可欠だ。
ここをサボると、AIの評価もただの感想になってしまう。
1. 評価軸と成功基準の事前定義
AIに評価を依頼する前に、まず「何をもって良い出力とするか」を明確に言語化するといい。
漠然と「この文章を評価して」と指示しても、AIは適当な基準で点数をつけてしまう。
目的と成功基準を最初に決めることが、すべての評価設計の出発点になる。
たとえば、文章の要約タスクであれば「元の意味を損なっていないか」「文字数制限を守っているか」といった具体的な評価軸が必要だ。
正確性や指示への忠実さなど、タスクごとに譲れないポイントをリストアップするといい。
基準がないまま評価させると、単なる感想文が返ってくるだけなので注意が必要だ。
2. 評価軸の用途に応じた重み付け
複数の評価軸を設定したら、次はプロダクトの用途に合わせて各軸の重要度を決める。
すべての評価軸を均等に扱うのではなく、目的に応じて優先順位をつけることが重要だ。
これが評価設計の核心と言える。
たとえば、カスタマーサポートのAIなら、親しみやすさよりも事実の正確性が圧倒的に重要になる。
逆に、キャッチコピーの生成なら、正確性よりも表現の豊かさを重視すべきだ。
どの項目を重視するかをプロンプト内で明確に指示することで、評価のブレを大幅に減らすことができる。
評価モデルの選定と手法
評価基準が決まったら、次は「どうやってAIに評価させるか」という手法の選択に入る。
ここでやり方を間違えると、AI特有のバイアスに騙されることになる。
3. 自己採点を避けた別モデルによる評価
出力を生成したLLM自身に評価をさせると、採点が甘くなる傾向がある。
これは自己選好バイアスと呼ばれるもので、人間が自分の書いた文章のミスに気づきにくいのと同じ原理だ。
客観的な評価を行うためには、生成モデルとは別のモデルを評価役として採用することが推奨される。
たとえば、GPT系統のモデルで生成した文章を、Claude系統のモデルに評価させるといった工夫が有効だ。
同じモデルに採点させると、評価というよりも単なる「承認」になってしまう。
より厳密な品質管理を求めるなら、別系統のモデルを組み合わせるのが基本になる。
4. 点数評価から一対比較への移行
LLMに100点満点で絶対的な点数をつけさせると、プロンプトのわずかなニュアンスで点数がブレやすい。
実務でモデルの優劣やプロンプトの改善効果を測りたい場合は、点数評価よりも一対比較を採用する方がおすすめだ。
「AとBのどちらが良いか」を問うことで、評価基準がシンプルになり精度が安定する。
ここで、点数評価と一対比較の違いを比較表にまとめておく。
| 評価手法 | 評価の安定性 | バイアスの影響 | おすすめの用途 |
| --- | --- | --- | --- |
| 点数評価 | 低い(ブレやすい) | 受けやすい | 単一出力の絶対基準での足切り |
| 一対比較 | 高い(安定する) | 受けにくい | プロンプト改善の前後比較 |
このように、目的によって使い分けるのが賢いやり方だ。
特にモデルの入れ替えを検討する際は、一対比較のほうが圧倒的に意思決定しやすくなる。
5. 一対比較による「それっぽさ」に隠れた粗の発見
LLMは一見それらしい文章を生成するのが得意だ。
そのため、単独の点数評価では、細かい抜け漏れや論理の飛躍が見逃されがちになる。
2つの出力を直接比較させることで、両者の細かな違いに目が向きやすくなる。
両方とも一定以上それらしく書けている前提で比較するため、表面的な「それっぽさ」に騙されにくくなる。
結果として、「それっぽいけれど粗がある」出力を見抜きやすくなるわけだ。
これも一対比較を導入する大きなメリットと言える。

システム化と自動検知
ここからは、より高度な品質管理をシステムに組み込むための手法を解説する。
複雑なタスクになるほど、単一のプロンプトだけで品質を担保するのは難しくなる。
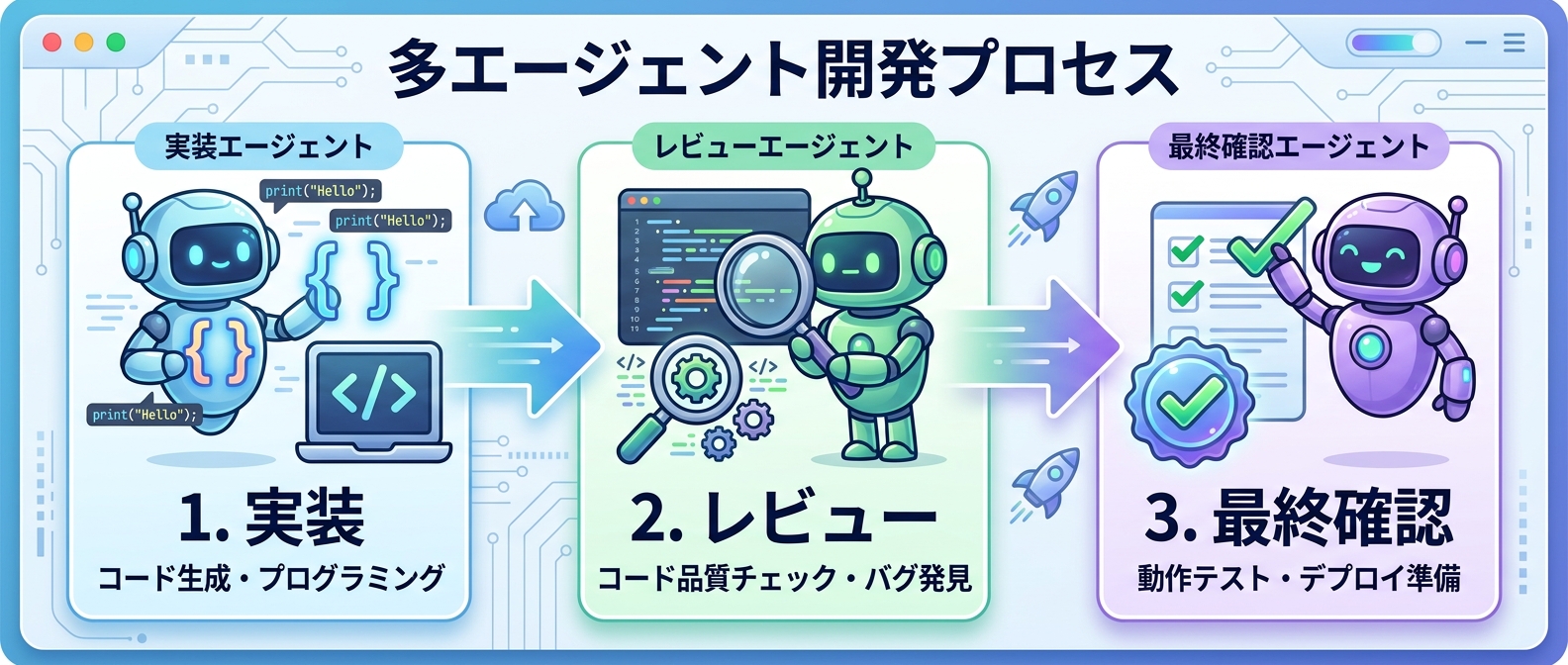
6. マルチエージェントによる多段階の品質ゲート構築
複雑なタスクでは、処理を複数の小さなステップに分割するのが効果的だ。
実装担当のAI、レビュー担当のAI、最終確認担当のAIといった具合に、役割を分けたマルチエージェントシステムを構築するといい。
複数のAIが相互にチェックすることで、システム全体の信頼性が格段に向上する。
単一のLLMにすべてを任せると、どうしても見落としが発生する。
実装エージェントのセルフレビュー、別エージェントのスポットチェック、最終品質検査という三段階の品質ゲートを設けるのが理想だ。
これにより、人間が介入しなくても一定水準の品質を担保できるようになる。
しんたろー:
Claude Codeで毎日コードを書いてる身からすると、この多段階チェックの仕組み化が一番使いやすかった。
理由はシンプルで、実装用のプロンプトとテスト用のプロンプトを完全に分離できるからだ。Claude Codeに「このコードのレビューアとして振る舞え」と指示するだけで、自分では気づかないエッジケースをサクッと指摘してくれる。一人開発の孤独なレビュー作業が劇的に楽になった。
7. エージェント間の入出力データクラスの標準化
処理を複数ステップに分割する際、各エージェントの入出力を標準化された形式で定義しておくことが重要だ。
これにより、各モジュールの独立性が保たれる。
将来的なモデルの入れ替えや、特定ステップのみの精度検証が容易になるメリットがある。
データの受け渡し形式がバラバラだと、どこでエラーが起きたのか追跡するのが困難になる。
JSONやYAMLなどの構造化データとして入出力を固定することで、検証の自動化もやりやすくなる。
システムをスケールさせるためには避けて通れない設計だ。
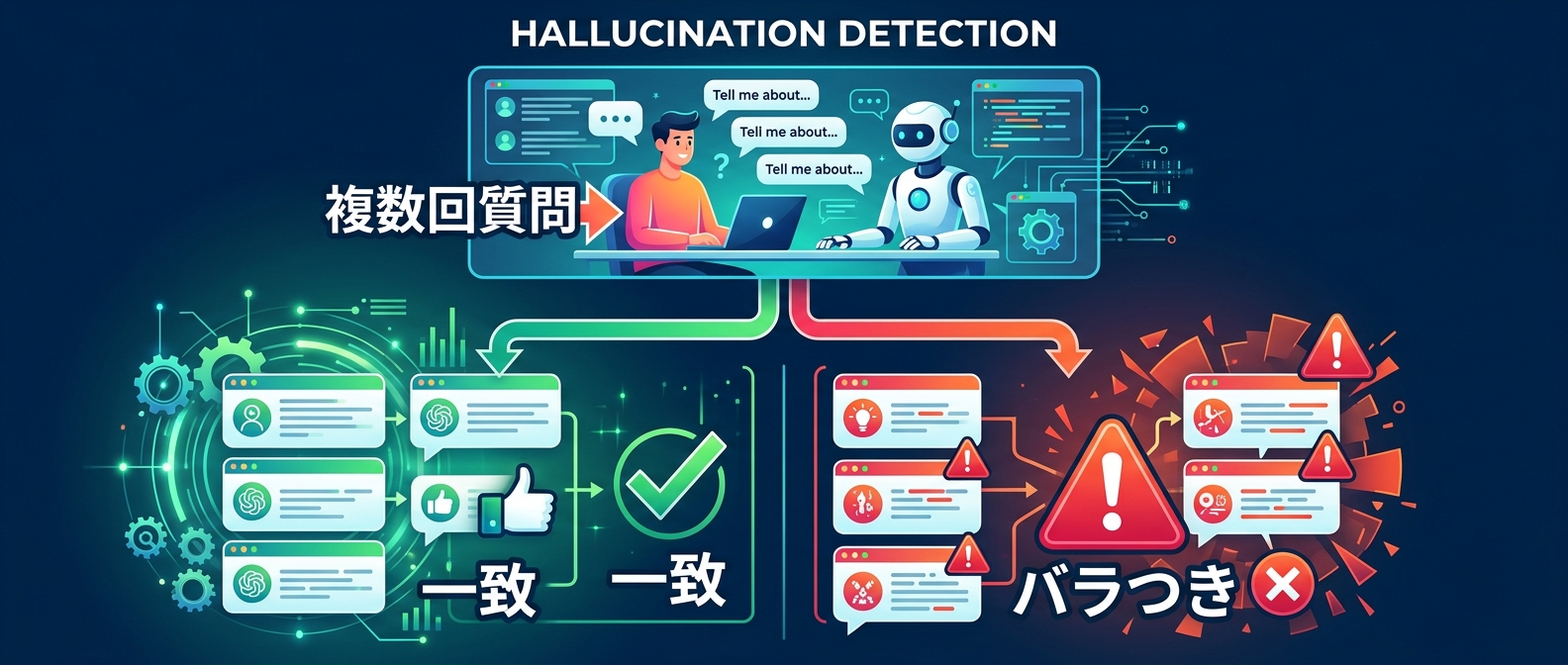
8. 自己チェック手法によるハルシネーションの自動検知
外部データベースを使わずに嘘の出力、いわゆるハルシネーションを検知する手法がある。
それが、LLM自身に自己チェックさせるアプローチだ。
同じ質問を複数回投げ、得られた回答同士の矛盾を確認することで、事実に基づかない怪しい出力をあぶり出すことができる。
事実に基づいた回答であれば、何度聞いても同じような内容になるはずだ。
逆にハルシネーションを起こしている場合は、回答ごとに内容がバラバラになる。
この性質を利用すれば、外部の正解データがなくてもある程度の嘘を見抜くことが可能になる。
9. 回答のバラつきのスコア化
複数回サンプリングした回答群に対して、表面上の類似度を計算してスコア化する手法も有効だ。
回答が毎回バラバラになる場合は、ハルシネーションの疑いが強いとシステム的に判断できる。
この「怪しさスコア」を閾値として設定しておけば、自動で警告を出す仕組みが作れる。
厳密な自然言語処理のアルゴリズムを使わなくても、単語の重複率を見るだけで十分な効果が得られる。
ラフな自己チェックでも、プロダクション環境では大きな威力を発揮する。
まずはこの簡易的なスコア化から始めるのがおすすめだ。
10. 人間によるレビューと評価プロンプトの継続的改善
LLMによる自動評価を構築した後も、人間によるレビューを完全に無くすことは推奨されない。
人間の感覚とLLMの評価のズレを定期的に確認することが不可欠だ。
そのズレをもとに、具体例を追加するなどして評価プロンプトを継続的に磨き上げる必要がある。
最初から完璧な評価基準を作れる人はいない。
運用しながら「こういうパターンの時は低く評価してほしい」という事例を集め、プロンプトに反映させていく地道な作業が求められる。
自動化はあくまで補助であり、最後の品質責任は人間が持つべきだ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
しんたろーのイチ推しTips
ここまで10個の手法を紹介してきたが、どれから手をつければいいか迷う人もいるだろう。
1人開発者として最も効果を感じたアプローチを共有する。
結論から言うと、まずは「点数評価から一対比較への移行」から始めるのが一番おすすめだ。
ThreadPostの開発でも、AIにSNSの投稿文を作らせる機能があるんだけど、最初は「この文章を100点満点で採点して」とやって大失敗した。プロンプトをちょっと変えただけで点数が乱高下して、改善してるのか改悪してるのか全くわからなくなった。
そこで「Aの文章とBの文章、どっちが自然か?」という一対比較に変えた途端、評価がバシッと安定した。評価プロンプトを作るのも簡単になるし、迷ったらまずは一対比較を試すといい。
よくある質問(FAQ)
Q1: LLMに自らの出力を評価させても問題ない?
LLMに自身の出力を評価させると、自己選好バイアスが働き、実際の品質よりも高い点数をつけてしまう傾向がある。人間が自分の書いた文章のミスに気づきにくいのと同じ原理だ。客観的で厳密な評価を行うためには、出力を生成したモデルとは別のモデルを評価役として使用することが推奨される。
Q2: 点数評価をするときの注意点は何?
点数評価はプロンプトのわずかなニュアンスや文脈に左右されやすく、点数がブレやすいという課題がある。また、一見それらしく書かれた文章に対しては、細かい抜け漏れがあっても甘く採点してしまう傾向が強い。モデルの優劣やプロンプトの改善効果を測りたい場合は、絶対的な点数をつけるよりも一対比較を採用する方が精度が安定する。
Q3: 嘘の出力(ハルシネーション)を自動で検知するには?
外部データベースを使わずにハルシネーションを検知するには、自己チェックアプローチが有効だ。LLMに対して全く同じ質問を複数回投げ、得られた回答同士の類似度や矛盾の有無を確認する手法になる。事実に基づいた回答なら毎回同じ内容になるが、ハルシネーションの場合は回答がバラつくため、その度合いから怪しさをスコア化できる。
Q4: 評価基準のプロンプトはどのように作ればいい?
まず最初に「何をもって良い出力とするか」という目的と成功基準を明確に言語化することが重要だ。漠然と指示するのではなく、正確性や読みやすさなど具体的な評価軸を設定し、用途に合わせて重み付けを行うといい。最初は人間がレビューしながら基準を修正し、具体例をプロンプトに含めることで評価精度を向上させることができる。
Q5: 複雑なタスクの品質を担保するコツはある?
複雑なタスクでは、処理を複数の小さなステップに分割し、それぞれを独立したAIエージェントに担当させるマルチエージェントシステムが効果的だ。実装担当のセルフレビュー、別エージェントによるスポットチェック、最終的な統合品質検査といった多段階の品質ゲートを設けることで、単一のLLMでは見落としがちなエラーをシステム全体で防ぐことが可能になる。
まとめ
LLMの出力を評価し、品質を担保するための10の手法を解説した。
感覚に頼った評価を卒業し、言語化された基準と仕組み化されたシステムを導入することで、AI開発の効率は劇的に向上する。
まずは評価軸を決め、一対比較を試すところから始めるといい。
AIの出力をコントロールできるようになれば、日々の業務やSNS運用も自動化しやすくなる。
評価の仕組み化ができたら、次は実際のサービス運用にAIを組み込んでみるといい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
