
RAGを作ってみたものの、本番環境で全然使い物にならないと悩んでいないか。単純に検索してLLMに渡すだけの構成では、実務の複雑な要求には耐えられない。
RAGをPoCで終わらせず、本番で安定稼働させるにはシステム全体を高度化する設計パターンが必要だ。結論から言うと、データ基盤の整備とエージェント化の視点を取り入れることが解決の糸口になる。
今回は、データパイプラインの構築から自己修正ループの実装まで、RAGの精度を劇的に改善する10の設計パターンを解説する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
データ基盤と検索精度の改善
RAGの土台となるのは、間違いなくデータ基盤だ。ここを疎かにすると、どれだけ優秀なAIを使っても意味がない。
1. 精度の核心となるチャンキングとメタデータ設計
RAGの精度の80%はデータで決まると言える。PDFや社内ドキュメントを単純に丸ごと分割するだけでは、検索時にノイズが大量に混入してしまう。
500から1000トークンを目安に、見出しやセクション単位で意味が通るように区切るのが基本だ。文脈が途切れないように工夫することで、AIが情報を正しく解釈できるようになる。
さらに、ソースファイル名、作成部門、バージョンといったメタデータを付与することが極めて重要だ。これにより、検索時の絞り込みが容易になり、検索精度を大幅に引き上げることができる。
2. ハイブリッド検索とリランキングの導入
ベクトル検索は意味の近さを捉えるのには優れているが、それだけでは不十分だ。専門用語や特定の型番など、厳密なキーワードの一致を拾いきれないケースが多々発生する。
そこで、ベクトル検索と従来のキーワード検索を組み合わせたハイブリッド検索の導入が必須になる。両者の強みを活かすことで、取りこぼしを防ぐことができる。
検索された複数のドキュメントに対して、メタデータの優先度やスコアで再度順位付けを行うリランキングを挟むとさらに効果的だ。これでLLMに渡すコンテキストの質が劇的に向上する。
出力制御とハルシネーション対策
正しい情報を見つけても、AIがそれを正しく出力できなければ意味がない。出力の安定化は本番運用における最大の課題だ。
3. OutlinesとPydanticによる型安全な出力制御
LLMの出力フォーマットが崩れる問題には、厳密なスキーマ検証が有効だ。JSON形式で出力させようとしても、途中でテキストが混ざってパースエラーになることはよくある。
OutlinesとPydanticというツールを組み合わせることで、型安全な出力をAIに強制できる。これにより、後続のシステム処理でエラーが発生しにくい堅牢なパイプラインを構築できる。
本番運用では、こうした出力の安定性がシステムの信頼性に直結する。このアプローチは非常に良さそうなので、データ連携の要として導入を検討するといい。
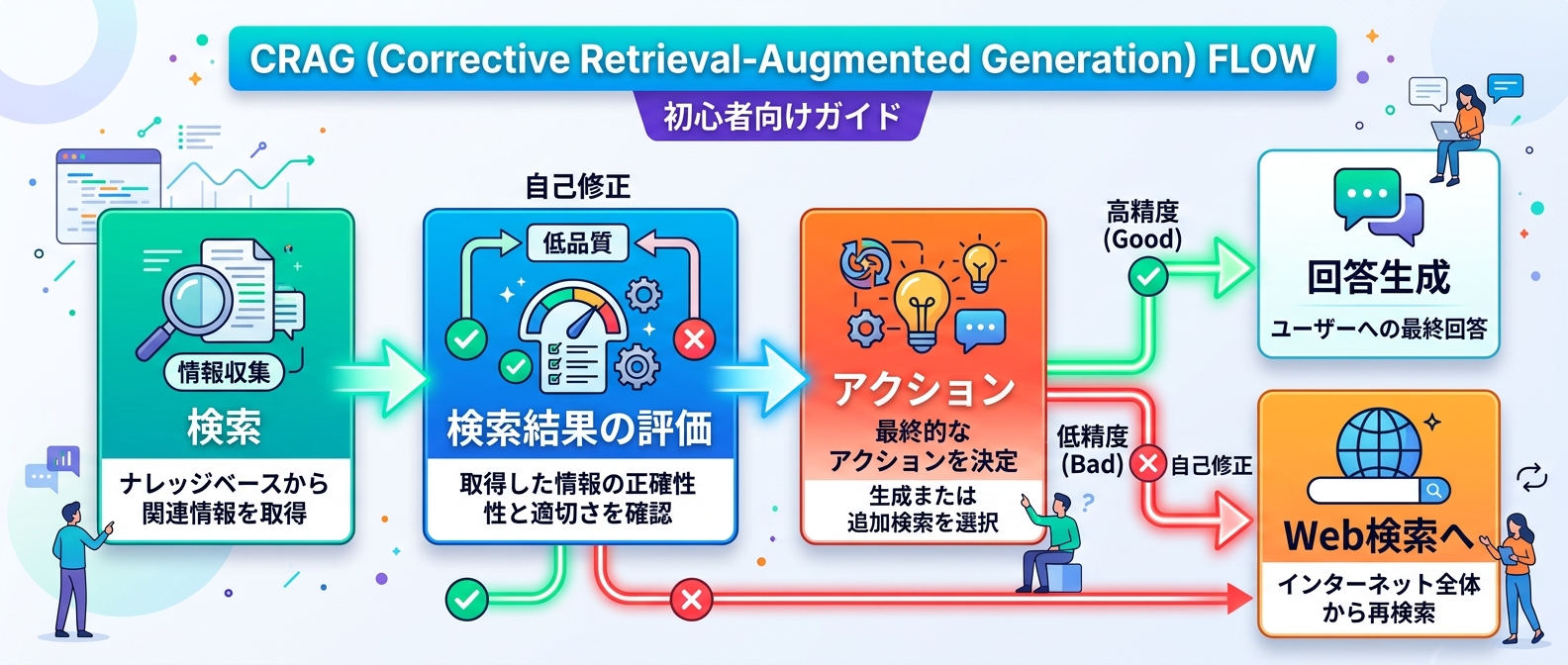
4. CRAGによる検索結果の自己評価
検索器が間違った情報を持ってきた際に、LLMもそれに引きずられて嘘をつく問題がある。これを防ぐために、評価器を導入するCRAGという手法が注目されている。
検索されたドキュメントが質問に回答するのに十分かを、高速なLLMで事前に判定する仕組みだ。情報が不十分であれば、そのまま回答を生成するのをストップさせる。
この評価ステップを挟むことで、AIのハルシネーションを構造的に防ぐことができる。確実性を担保するための重要な設計パターンだ。
5. 検索失敗時のフォールバック設計
CRAGの評価器で検索結果が不正確、または曖昧と判定された場合のみ、Web検索などの代替アクションを実行する。社内データに無いなら外に探しに行くという条件分岐だ。
常にWeb検索を行うシステムと比べ、APIコストを抑えつつ必要な時だけ外部情報を補完できる。この賢いルーティングが、コストパフォーマンスの高いシステムを作る鍵になる。
オンプレミス環境などWeb検索ができない場合は、ユーザーに質問を言い換えさせる処理にフォールバックさせるといい。
評価とコスト最適化
システムが完成した後の運用フェーズを見据えた設計も欠かせない。
6. 本番運用のためのRAG評価設計
RAGは作って終わりではない。検索精度、回答精度、誤回答率などの定量的な指標を設け、継続的に評価と改善を回すループが必要だ。
テスト用の質問と正解のセットを用意し、定期的にシステムの性能を測定する仕組みを作るといい。評価指標がないと、プロンプトやデータを修正した際に本当に改善されたのか判断できなくなる。
人間によるレビューと自動評価を組み合わせることで、運用の質を担保できる。
7. キャッシュとモデル最適化によるコスト削減
本番環境では、ベクトル化の処理やLLMの推論コストが肥大化しやすい。頻出クエリのキャッシュ化により、無駄なAPI呼び出しを防ぐことがコスト削減に直結する。
すべての処理に高性能なモデルを使う必要はない。検索結果の妥当性評価などの単純なタスクには、軽量で安価なモデルを使い分ける設計が効果的だ。
さらに、プロンプトの最適化や検索件数の上限調整を組み合わせることで、精度を維持したまま運用コストを最適化できる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
エージェント化への進化
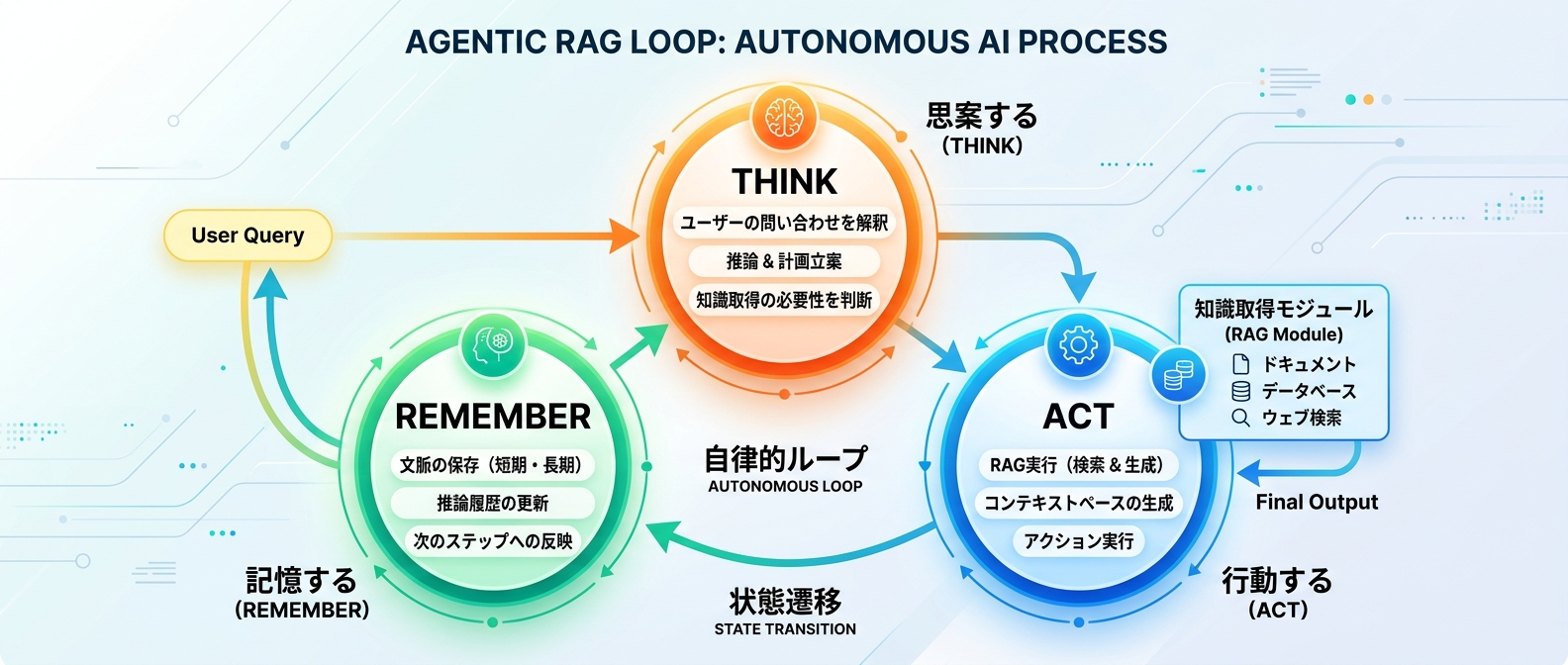
RAGの究極の形は、自律的にタスクをこなすAIエージェントへの統合だ。
8. RAGを知識取得モジュールとして再定義する
RAG単体では、1回の質問に対して1回回答を返す静的な処理に留まる。業務を完遂させるには、RAGを単なる検索システムではなく、AIエージェントの部品として捉え直す視点が必要だ。
エージェントが意思決定を行うために必要な、正確なドメイン知識を渡すためのモジュールとしてシステムに組み込むといい。これにより、より複雑な業務の自動化が見えてくる。
RAGは不要になるわけではなく、システムの中核を担う知識取得レイヤーとして進化していく。
9. Semantic Kernelによるループ構造の実装
AIエージェントを構築するためのフレームワークを活用すると、思考、行動、記憶の責務をシステム内で明確に分離できる。Semantic Kernelなどのツールがその代表例だ。
これにより、単発の推論ではなく、目的が達成されるまで継続的にタスクを処理し続けるループ構造を実装可能になる。複雑な業務フローを自動化する際の強力な武器だ。
エージェントの設計フレームワークを取り入れることで、開発の見通しが圧倒的に良くなる。
10. LangGraphを用いた状態遷移の構築
CRAGのような複雑な条件分岐や自己修正のフローは、状態遷移のグラフとして実装するのがおすすめだ。LangGraphを使うと、この複雑なフローを視覚的にも論理的にも整理できる。
ノード間で状態を渡し合いながら評価と検索を繰り返すことで、自律的で信頼性の高いシステムを実現できる。単なるRAGから、自律的に動くエージェント型RAGへの進化を支える技術だ。
この技術も非常に気になっており、より高度な推論パイプラインを作る際に役立つはずだ。
しんたろー:
僕は毎日Claude Codeを使って1人でSaaS開発をしているんだけど、データ処理の複雑なパイプラインを書く時にClaude Codeの恩恵を痛感している。
チャンキングのロジックやリランキングの処理を実装する際、Claude Codeに要件を伝えると、プロジェクト全体の文脈を理解した上で最適なコードベースを一気に組み上げてくれる。
今回まとめた10の設計パターンも、AIコーディングツールと組み合わせることで1人でも十分に実装可能な範囲だと言える。
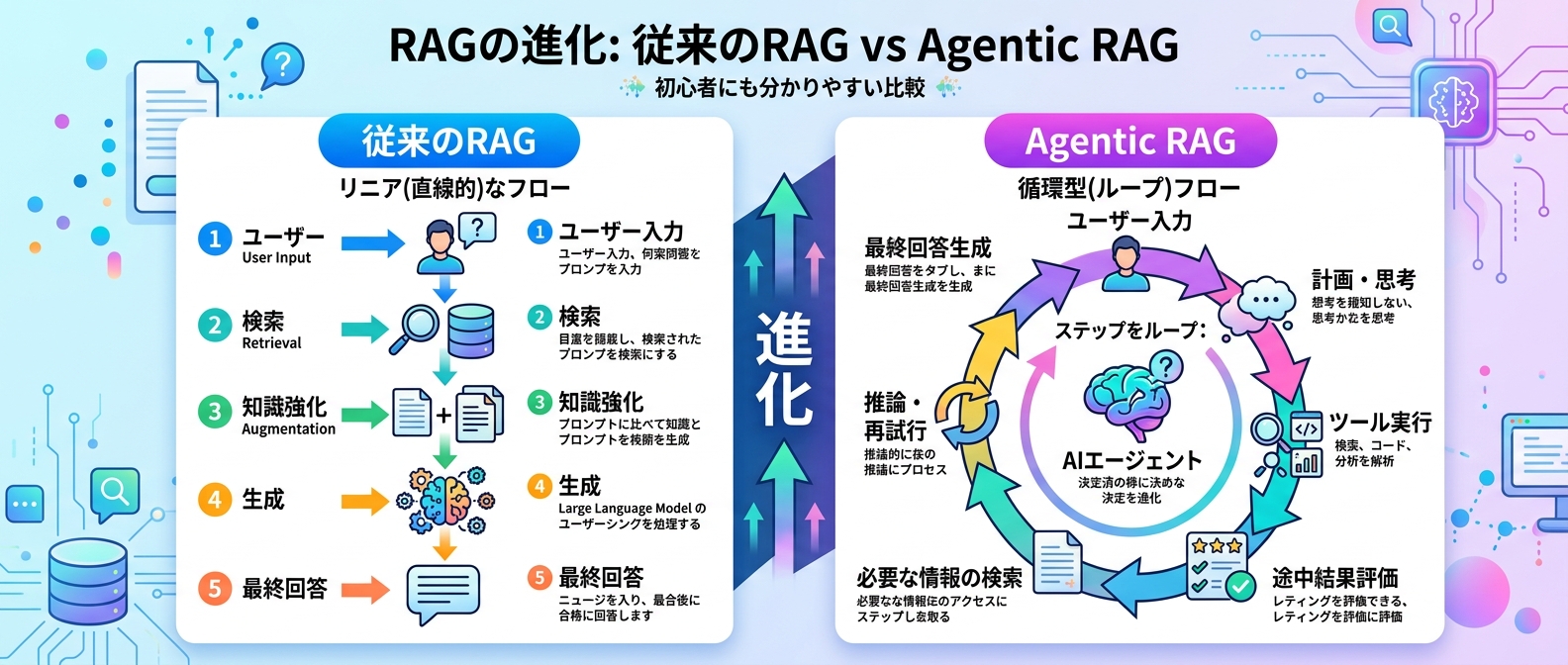
RAG進化の比較表
単純なRAGからエージェント化に至るまでの進化の過程を比較表にまとめた。
| フェーズ | システム構成 | 主な特徴 | 適した用途 |
| :--- | :--- | :--- | :--- |
| 初期RAG | ベクトル検索 + LLM | 単純な1問1答。ハルシネーションのリスクあり | 社内FAQの簡易検索 |
| 高度なRAG | ハイブリッド検索 + リランキング + 評価器 | 検索精度が高く、出力が安定。自己評価を含む | カスタマーサポート支援、マニュアル検索 |
| Agentic RAG | 状態遷移グラフ + 外部ツール連携 | 目的達成まで自律的に検索と行動を繰り返す | 複雑な調査業務、データ分析の自動化 |
よくある質問(FAQ)
Q1: RAGの精度が上がらない場合、まず何を見直すべきか?
最も優先すべきはデータ基盤の見直しだ。RAGの精度の80%はデータで決まると言われており、ここを疎かにするとどれだけ優秀なLLMを使っても正しい回答は得られない。ドキュメントを丸ごと分割するのではなく、500から1000トークンを目安に見出しやセクション単位で意味が通るように区切ることが重要だ。さらに、ソースや作成部門などのメタデータを付与することで、検索時のノイズを大幅に減らし、精度の高い情報抽出が可能になる。
Q2: ベクトル検索だけで十分ではないのか?
ベクトル検索は文章のニュアンスを捉えるのには優れているが、特定の製品名や専門用語などの厳密なキーワードの一致を拾いきれないケースが多々発生する。そのため本番環境では、ベクトル検索と従来のキーワード検索を組み合わせたハイブリッド検索を導入するのが一般的だ。さらに、検索された複数のドキュメントに対して、メタデータの優先度やスコアに基づいて再度順位付けを行うリランキング処理を挟むと、コンテキストの質を劇的に向上できる。
Q3: LLMが嘘をつくのを防ぐにはどうすればいいか?
基本となるのはプロンプトエンジニアリングだ。提供された情報のみを使って回答することや、情報が不足している場合は推測せずに情報が見つからないと答えることをシステムプロンプトで強く制御する。さらに高度な対策として、CRAGという手法が効果的だ。検索器が取得したドキュメントが質問に答えられる内容かを別の軽量なLLMに事前評価させ、不十分な場合は回答生成を止めるかWeb検索に切り替えることで、嘘を構造的に防ぐことができる。
Q4: RAGとAIエージェントの違いは何か?
RAGは1回のクエリに対して1回検索を行い、1回回答を生成するという静的で単発の知識取得システムだ。これに対しAIエージェントは、目的が達成されるまで自律的に思考し、行動し、結果を記憶して次の行動を決めるという継続的なループ構造を持った意思決定システムだ。両者は競合するものではなく、RAGはAIエージェントが意思決定を行うために必要な正確なドメイン知識を提供するモジュールとしてシステムに組み込まれる。
Q5: 本番環境での運用コストを抑えるにはどう設計すべきか?
RAGの本番運用では、ドキュメントのベクトル化費用やデータベース維持費、LLMの推論API費用が主なコスト要因になる。これを最適化するには、まず頻出する質問と回答のペアをキャッシュして無駄なAPI呼び出しを防ぐことが重要だ。また、検索結果の妥当性評価などの単純なタスクには軽量で安価なモデルを使い分ける設計が効果的だ。社内データで解決できない場合のみ外部Web検索APIを叩くといった条件分岐を設けることで、精度を維持しながらコストを抑えられる。
まとめ
RAGは単純な仕組みに見えて、本番で使い物にするには泥臭いデータ整備とシステム設計が不可欠だ。
まずはチャンキングとメタデータの見直しから始め、徐々に評価器の導入やエージェント化へとステップアップしていくといい。今回紹介したパターンを一つずつ試すことで、確実にシステムの堅牢性は上がっていくはずだ。
ThreadPostの開発でもデータ構造の設計にはかなり気を遣っているけれど、AIに正確な文脈を渡す重要性はどんなシステムでも変わらない。
AIの進化は早いが、データの質とシステムアーキテクチャの基本設計こそが、最終的なプロダクトの勝敗を分ける。
焦らずに足元のデータ基盤からしっかり固めていくのが一番の近道だ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
