
Opus 4.6になってからClaude Codeが急に指示を忘れる。昨日まで動いていた自動化が途中で止まる。
原因は200Kトークンのコンテキストコンパクションだ。
今は3つのファイルを使ったコンテキストアーキテクチャで設計する。
エージェントに気持ちよく働いてもらうための、記憶の階層化について整理する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
コンテキストコンパクションという避けられない壁
Claude Codeはエージェントループで動作する。ユーザーの指示、モデルの応答、ツール呼び出しの結果がすべてコンテキストウィンドウに蓄積される。
Opus 4.6のコンテキストウィンドウは200Kトークンだ。
この上限に近づくと、古い会話部分を要約して短縮する。新しい情報を入れるスペースを確保する処理が自動的に実行される。
これがコンパクションと呼ばれる現象だ。
単なる古いメッセージの削除ではない。要約による情報の圧縮だ。
この過程で、詳細なルールや文脈が容赦なく失われる。
Opus 4.6になってから、このコンパクションの発生頻度が上がっている。
1つのセッションで28.7MBのログを吐き出し、17回のコンパクションが発生したケースも報告されている。
モデルの応答が長くなる過剰エンジニアリングの傾向が原因の1つだ。
同じターン数でもコンテキストの消費速度が上がり、あっという間に上限に達する。
既に読んだファイルを再度読んだり、不要なサブエージェントを生成したりする循環パターンも確認されている。
本来1ターンで済む操作に5〜8ターンかかり、コンテキストを無駄に消費している。
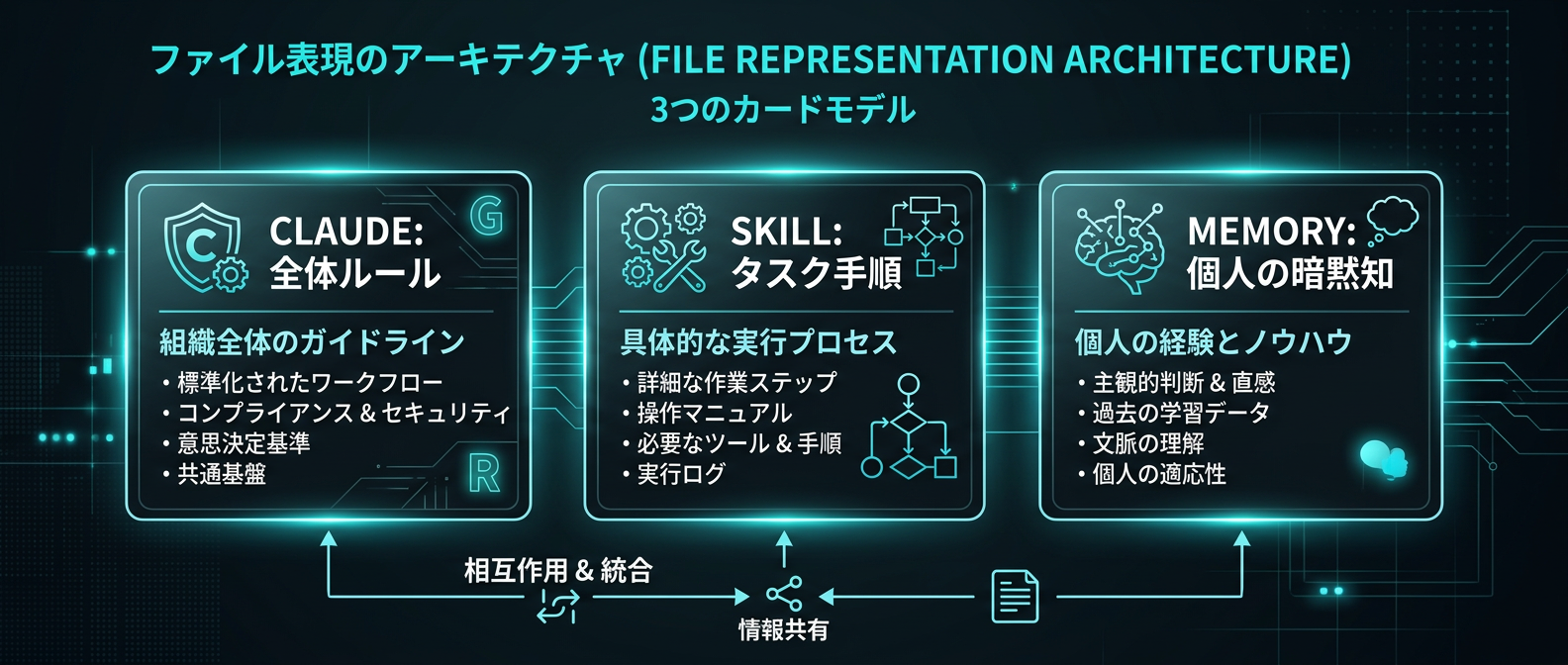
3つのファイルによる記憶の階層化
コンパクションによる忘却を防ぐため、プロンプトを1つのファイルに詰め込むのは最悪のアンチパターンだ。
解決策は、CLAUDE.md、SKILL.md、MEMORY.mdという3つのファイルを使い分けることにある。
CLAUDE.mdはプロジェクト全体で絶対のルールを定義する。
技術スタックや禁止事項など、最も優先度の高い制約のみを記述する。
SKILL.mdは特定のタスクを実行するための具体的な手順やワークフローを定義する。
コードレビューやテスト作成など、反復する作業を構造化して覚えさせる。
MEMORY.mdは会話の中で気づいた個人の好みや暗黙知を永続化する。
ファイル命名規則やコミットメッセージの言語など、セッションを跨いで維持したいルールを記録する。
段階的開示と構造化による制御
詳細なドキュメントをすべて読み込ませると、すぐにコンテキストが溢れる。
これを防ぐのが段階的開示という設計手法だ。
メインの指示ファイルには概要と参照先へのポインタだけを記述する。
エージェントは必要になったタイミングで自律的に詳細ファイルを読みに行く。
これにより、初期のトークン消費を抑えつつ、必要な深さの知識を提供できる。
トークン節約と指示の確実な実行を両立させる。
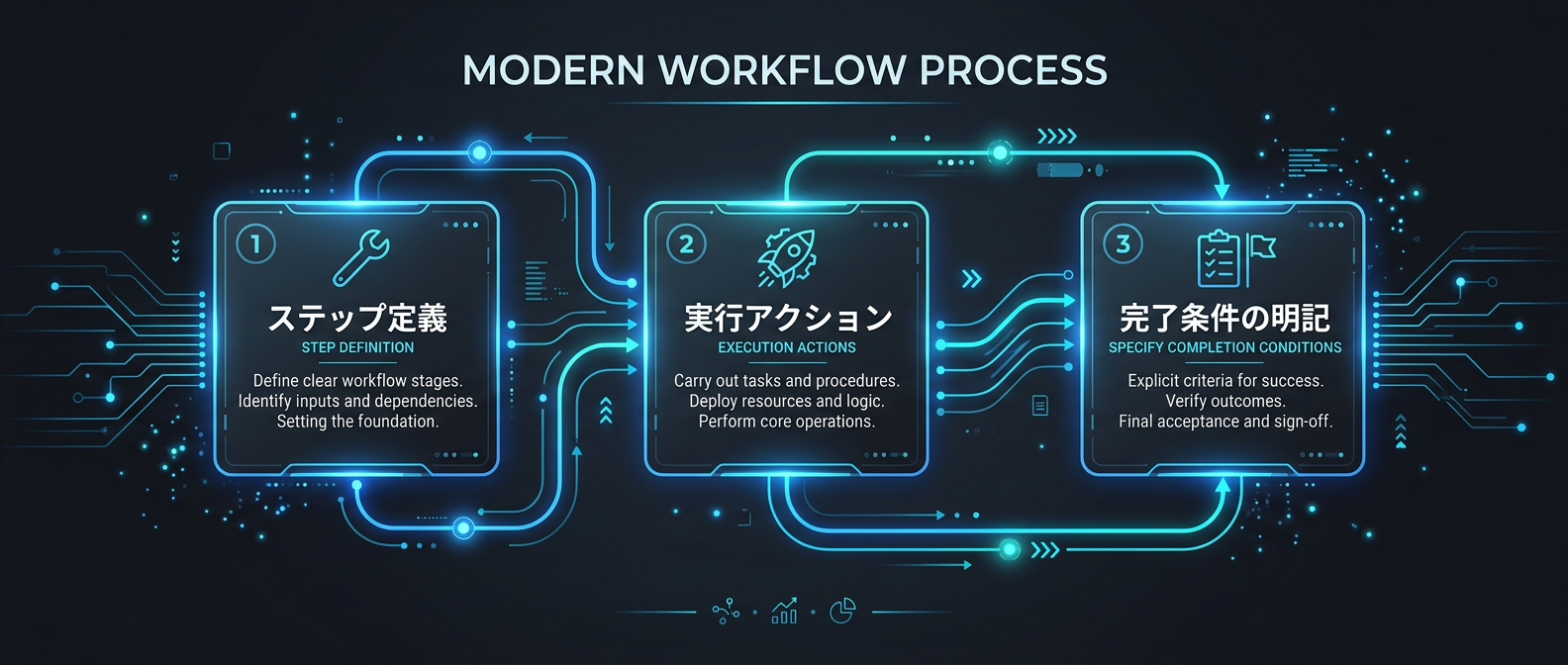
複数ステップの作業フローは、散文ではなくYAML形式で構造化する。
各ステップに完了条件を明記することで、エージェントが次に進むタイミングを自分で判断できるようになる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
エージェントの忘却を前提としたシステム設計
LLMエージェントは必ず忘れる。これをバグではなく仕様として扱う。
CLAUDE.mdにプロジェクトの全概要を書き込むと、毎ターンのコンテキスト消費が激増する。
エージェントはCLAUDE.mdをシステムプロンプトの一部として毎回送信する。
200行のルールファイルは、200Kトークンのウィンドウの中で無視できないコストになる。
目安として、CLAUDE.mdは500トークン以内に抑える。
どうしても長くなる場合は、プロジェクトルートの隠しディレクトリに分割ファイルを配置する。
必要な時だけ参照させる設計にしないと、すぐにコンパクションの餌食になる。
モデルに何を渡すかだけでなく、モデルが忘れた時にどうリカバリするかまで含めて設計する。
しんたろー:
Opus 4.6のコンパクション頻発、まじでビビる。
CLAUDE.mdに何でもかんでも突っ込んでたから、うちの環境でもたまに指示無視されてたのかも。
トークン節約ってAPI代の話だけじゃなくて、エージェントのIQを保つための死活問題だわ。
データ検証のスクリプト化
データを検証してから進めてという指示ではClaudeは動かない。
検証するが何を意味するのか分からないからだ。
Pythonスクリプトを実行してデータフォーマットを確認するなど、何をどうやって検証するかまで書くのが正解だ。
コードは決定論的だが、言語の解釈は曖昧だ。
重要な検証は言語指示だけに頼らず、スクリプト化するのが安定する。
必須フィールドの欠落や無効な日付フォーマットなど、一般的な問題をスクリプトで検知させる。
これにより、エージェントの推測によるエラーを排除できる。
YAMLによるワークフローの構造化
複数ステップの作業フローを散文で書くと、AIは曖昧に解釈する。
SKILL.mdでは、ワークフローをYAML形式で構造化する。
ステップ名、説明、実行するアクション、そして完了条件を明確に定義する。
完了条件の明記が鍵だ。
いつそのステップが完了したかが明確になり、エージェントが次に進むタイミングを自分で判断できる。
コンテキストウィンドウが溢れない限り、このワークフローは最後まで確実に実行される。
散文のプロンプトから構造化されたデータへの移行が、出力安定化に直結する。
サブエージェントの分離と制御
コンテキストを最も消費するのはツールの出力結果だ。
ファイルの全文読み込みや長大なログ出力が、コンテキストを一気に圧迫する。
重い調査タスクはサブエージェントに委任する。
サブエージェントはメインセッションとは別のコンテキストで動作するため、メインの消費を抑えられる。
ファイル検索やコードリーディングを任せ、メインセッションでは結果の要約のみを受け取る。
1つのサブエージェントに1つの調査タスクを割り当てるのが基本だ。
ただし、不必要にサブエージェントを生成する問題も起きている。
サブエージェントの利用は明示的に指示した場合のみに限定するルールを設定する。
暗黙知を自動で永続化する仕組み
エージェントにファイルを作らせると、命名規則がバラバラになりがちだ。
日本語だったり英語だったり、日付があったりなかったりする。
1日中作業していると、20〜30個のファイルが平気で生成される。
日付を跨ぐと、どのファイルが何なのか全く分からなくなる。
エージェントは毎回その場の判断で名前を決めている。
セッションを跨ぐと前回のファイル名を覚えていないので、一貫性の維持は構造的に無理だ。
ここでMEMORY.mdが威力を発揮する。
会話中にこれ覚えておいてと言うだけで、自動的にファイルに書き込まれる。
この内容は毎回のセッション開始時に自動で読み込まれる。
以降、別の日に別の会話を始めても、エージェントはこのルールに確実に従う。
手動でMEMORY.mdを直接編集することも可能だ。
プロジェクトごとの隠しフォルダ内に保存されているため、いつでも微調整ができる。

1セッションは15ターンで捨てる
コンパクションを防ぐ最もシンプルな方法は、発生する前にセッションを終了することだ。
明確な1タスクを定義してセッションを開始する。
10〜15ターン以内でタスクを完了させる。
その後はすぐに新しいセッションを開始し、ルールを新鮮な状態で読み込ませる。
複数タスクを連続で依頼し、50ターン以上続けるのは危険だ。
コンパクションが発生し、ルールが喪失して事故に繋がる。
現在のコンテキスト使用量を把握する習慣をつける。
使用率が70%を超えた時点で、新しいセッションへの移行を検討する。
リカバリールールの強制
コンパクションの発生自体を完全に防ぐことはできない。
発生した場合に備えて、重要情報が自動的にリカバリされる設計を組み込む。
CLAUDE.mdにコンパクション後のルールを明記する。
次のアクションの前に必ず重要セクションを再読し、現在のタスクの目的を再確認させる。
直前の作業状態をバージョン管理システムで確認させるのも有効だ。
記憶喪失に対する防御策として、一定の効果が期待できる。
モデルがこの指示自体を忘れるリスクはある。
しかし、ルールファイルはコンパクション後も再読される設計になっているため、被害を最小限に抑えられる。
1セッション15ターンで切るの、理屈はわかるけど実践するとなると結構ダルい。
ThreadPostの運用で、ついダラダラ会話が続く。
コンテキスト使用率70%での強制リセットが気になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
複雑なタスクのSkill化プロセス
日常的な改善は、短いセッションの往復でほぼ事足りる。
しかし、複雑な自動化は1つのSkillに抽出する。
広く浅く試すより、難易度の高い代表タスクを1つ決める。
それが安定するまで会話で詰め、うまくいった進め方を抽出する。
この順番を守ることで、質の高いコンテキスト設計が可能になる。
チームのコーディング規約のAI版として、強力な武器になる。
毎回同じ指示を繰り返さなくても、作業手順やドメイン知識をまとめて再利用できる。
一度教えて何度も使うための仕組みが、開発効率を底上げする。
特定の依存関係さえ満たせば、複数の利用面で再利用できるのも強みだ。
エージェントの自律性を高めるための、最も確実な投資になる。
MCPとSkillの連携
SkillはClaude.aiやClaude Code、APIで同じように動くことが想定されている。
一度作れば、依存関係さえ満たせば複数の利用面で再利用できる。
MCPと組み合わせることで、さらに強力になる。
特定のデータベースへのクエリ方法や、社内APIの叩き方をSkillに記述する。
MCPツールが提供する機能を、どのような手順で組み合わせるかを教え込む。
これにより、単なるテキスト生成を超えた自律的なシステム操作が可能になる。
ツールと手順の組み合わせが、エージェントの能力を最大限に引き出す。
Q1: SKILL.md、CLAUDE.md、MEMORY.mdはどう使い分ければいいですか?
A1: CLAUDE.mdはプロジェクト全体で絶対のルールを500トークン以内で簡潔に書く。技術スタックや禁止事項が該当する。SKILL.mdは特定のタスクを実行するための具体的な手順やワークフローを定義する。コードレビューやテスト作成などで使う。MEMORY.mdは、会話の中で気づいた個人の好みや暗黙知を永続化するために使う。ファイル命名規則やコミットメッセージの言語指定に最適だ。
Q2: Claude Codeが指示を無視したり、途中で忘れたりする場合はどうすればいいですか?
A2: コンテキストコンパクションが発生している可能性が高い。過去の会話が圧縮され、詳細なルールが失われている状態だ。対策として、1つのセッションを10〜15ターン程度で短く区切る。また、CLAUDE.mdにコンパクション発生時はルールを再読するというリカバリー指示を入れる。複雑な手順はYAML形式で完了条件を明記し、構造化して読ませるのが有効だ。
Q3: 詳細なドキュメントをClaudeに読ませたいが、コンテキスト上限が心配です。
A3: 段階的開示という手法を使う。メインの指示ファイルには概要と詳細ファイルへのポインタだけを記述する。エージェントは必要になったタイミングで自律的にそのファイルを読みに行く。これにより、初期のトークン消費を最小限に抑えつつ、必要な深さの知識を提供できる。すべてを1つのファイルに詰め込むのは、コンパクションを誘発する最大の原因だ。
まとめ
コンテキストの構造化と段階的開示が、エージェントの出力エラー率を80%低下させる。
忘却を前提とした設計こそが、これからのAI開発のスタンダードだ。
3つのファイルの使い分け、完全に理解した。
ThreadPostのコンポーネント設計ルールも、SKILL.mdへの移行を検討したい。
エージェントに気持ちよく働いてもらうための環境整備、奥が深すぎる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
