
結論から言うと、AIの回答品質を決めるのは「プロンプトの文章力」ではなく「渡す情報の質」だ。
どれだけ丁寧な言葉で指示を出しても、AIに渡すコンテキスト(文脈・背景情報)がノイズだらけなら、回答は必ず劣化する。逆に、コンテキストを正しく管理するだけで、同じモデルから引き出せる回答品質が劇的に変わる。この記事では、1人SaaS開発の現場で実践しているコンテキスト管理術を8つにまとめた。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
Tips 1|「プロンプトの工夫」より「コンテキストの質」を優先する
多くの人がAIの精度を上げようとするとき、まず「指示の言葉遣い」を磨こうとする。それ自体は悪くないが、優先順位が逆だ。
「どのモデルを使うか」「どう指示するか」よりも、「モデルに渡す情報をどう組み立てるか」の方がはるかに回答品質を左右する。
たとえば、同じ質問でもコンテキストの与え方によってAIの回答品質が最大4.6倍変わるという実験結果がある。プロンプトの文面を磨く前に、まず「AIに渡している情報はノイズだらけではないか」を疑うところから始めるといい。
Tips 2|「小さいモデル+RAG」でハルシネーションを防ぐ
直感に反するが、大規模なモデルほど「もっともらしい嘘(ハルシネーション)」をつく傾向がある。
賢いモデルは、知識の空白を自信満々に埋めてしまう。これが厄介だ。対策として有効なのが、軽量モデルにRAG(検索拡張生成)を組み合わせる手法だ。
外部の正確な情報をリアルタイムで検索・注入することで、モデルが「でたらめを自信を持って語る」状況を防げる。「大きいモデル単体」より「小さいモデル+RAG」の方が精度が高いケースは珍しくない。
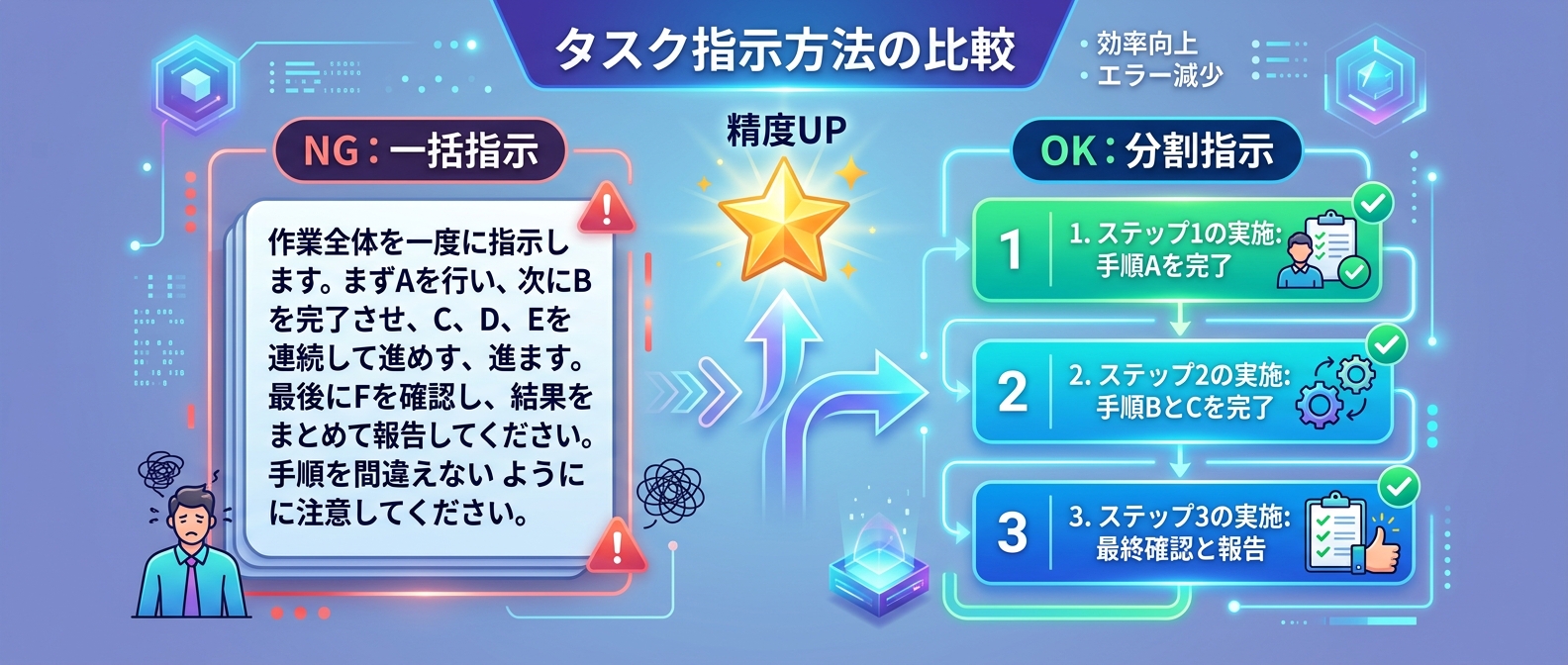
Tips 3|複雑なタスクは小さく分割し、1つずつ順番に要求する
「一度にすべてをやらせない」——これがコンテキスト管理の中で最も即効性が高いTipsだ。
複数の指示を一度に出すと、モデルは出力を1回に収めようとして品質が著しく低下する。たとえば「要件定義・設計・実装・テストを全部やって」と頼むのは最悪のパターンだ。
正しいやり方は、人間が複雑な仕事を分解するのと同じ発想だ。「まず要件を整理して」→「次にAの機能だけ実装して」→「その次にBを追加して」と、タスクを小さく切り出して1つずつ処理させる。これだけで回答品質は別物になる。
Tips 4|few-shot(例示)が逆効果になる「崩壊」現象に注意する
「AIに例を見せれば精度が上がる」——これは一般的に正しいが、例外が存在する。
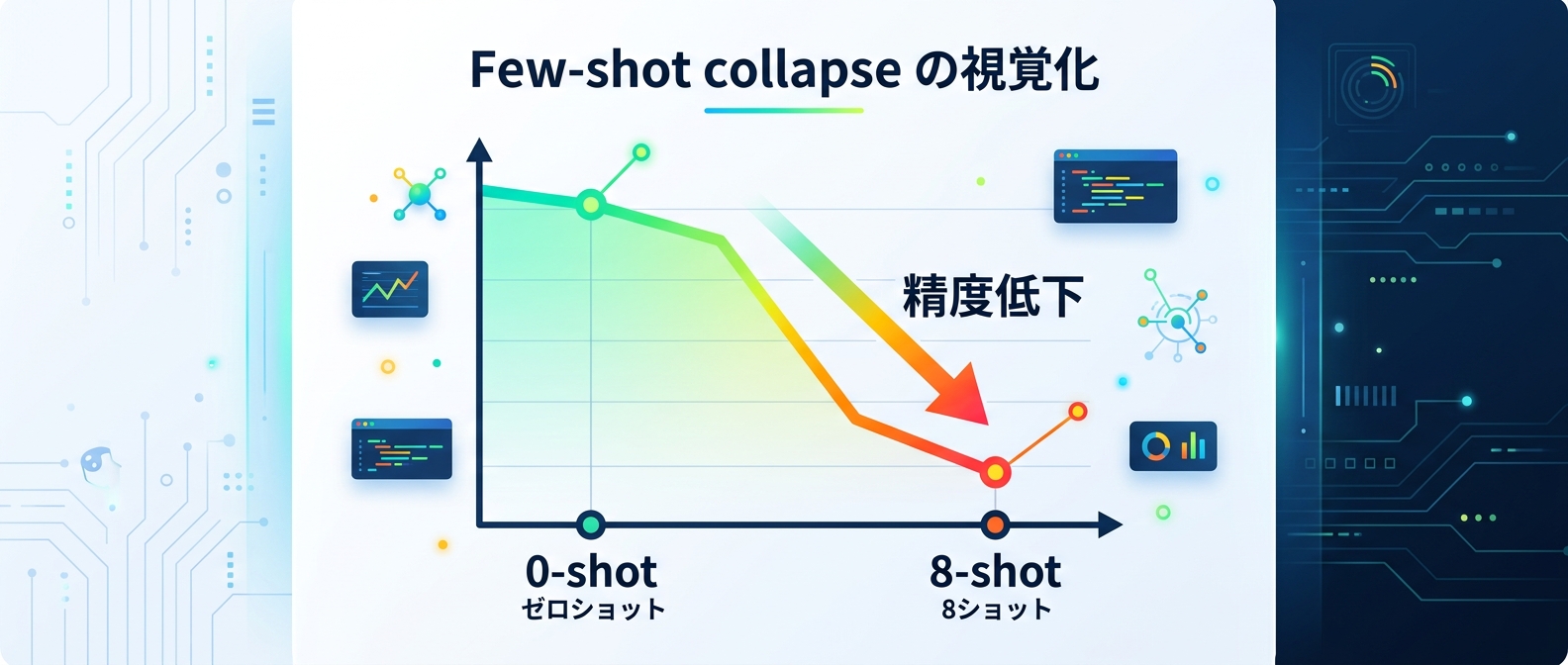
特定のモデルとタスクの組み合わせでは、例示を追加するほど性能が劇的に下がる「few-shot collapse(崩壊)」という現象が起きる。12モデル×5タスクで検証した実験では、0-shotで93%の精度を出していたモデルが、8-shotで30%まで崩壊したケースも確認されている。
例示を入れて回答がおかしくなったと感じたら、あえて例示を外した「0-shot」で指示を出し直すといい。例示は「常に正解」ではない。
Tips 5|モデルとタスクの相性を見極め、0-shotだけで評価しない
前のTipsと表裏一体の話だが、0-shotだけでモデルを評価するのも危険だ。
0-shotでは全く回答できないモデルが、例示を追加した途端に高精度を叩き出すケースがある。分類タスクでは、0-shotで全モデルが0〜20%のスコアだったのに、例示を追加したら80%超に改善したという実験結果もある。
また、推論特化モデルに要約タスクをさせると精度が出ないという相性問題もある。推論モデルは「情報を考えて増やす能力」に最適化されているため、情報を削る要約とは根本的に相性が悪い。モデル選定は0-shotの結果だけで判断しないのが鉄則だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
Tips 6|独立したタスクごとにコンテキストをクリア(/clear)する
関係のない過去の会話履歴は、無駄なトークンを消費するだけでなく、AIの精度を確実に下げる。
生成AIは会話履歴を内部メモリとして保持しているわけではない。過去のやり取りを毎回プロンプトの一部として送り直している。つまり、セッションが長くなるほど、一回の推論で処理されるデータ量が増え続ける。
課題Aを解決したセッションで課題Bを続けると、課題Aの履歴が課題Bの処理に「死荷重」として乗り続ける。タスクが完了したら「/clear」でコンテキストをリセットする習慣をつけるといい。トークン消費を抑えながら、情報密度を高い状態で維持できる。
Tips 7|AIが同じ誤りを繰り返す時は、迷わずコンテキストをリセットする
AIが指示通りに動かなくなったり、同じ間違いを繰り返したりする場合、原因は高確率で「過去の失敗パターンがコンテキストに残っていること」だ。
過去の失敗のやり取りが蓄積されると、それ自体がバイアスとして次の推論に悪影響を与える。何度修正指示を出しても改善しないなら、修正を重ねるのは逆効果だ。
迷わず会話をリセットし、前提条件だけを整理して再提示する。これが最速の解決策だ。「粘り強く同じセッションで修正し続ける」のは、コンテキスト管理の観点からは最もやってはいけない行動だ。
Tips 8|Auto-compact される前に、重要な情報を手動で保全する
会話が長くなりコンテキスト上限に近づくと、ツール側で「Auto-compact(自動要約)」が実行されることがある。
これは会話履歴を自動的に圧縮する処理だが、その過程で重要な仕様・制約・ニュアンスが欠落するリスクがある。自動要約に任せきりにするのは危険だ。
コンテキスト上限に達する前に、その時点での重要な結論・仕様・前提条件を自分でまとめ直し、新しいセッションで再提示して仕切り直すのが得策だ。重要な情報の保全は、ツールに任せず自分でコントロールするのが原則だ。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、Tips 6と7は本当に効いた。
以前は1つのセッションで「設計→実装→デバッグ→リファクタ」まで全部やろうとしてたんだけど、セッションが長くなるにつれてClaudeの回答がどんどん的外れになっていくのを感じてた。今は機能単位でセッションを切るのを徹底してる。体感として、回答の「ズレ」がほぼなくなった。
コンテキスト管理術8選|一覧比較表
| # | Tips | 難易度 | 即効性 | 特に効くシーン |
|---|------|--------|--------|----------------|
| 1 | コンテキストの質を優先する | ★☆☆ | 高 | 全シーン共通 |
| 2 | 小さいモデル+RAG | ★★★ | 高 | 事実確認・調査系 |
| 3 | タスクを小さく分割する | ★☆☆ | 非常に高 | 複雑なコーディング・長文作成 |
| 4 | few-shot collapseに注意 | ★★☆ | 中 | 精度が突然落ちた時 |
| 5 | モデルとタスクの相性を見極める | ★★☆ | 中 | モデル選定・評価時 |
| 6 | タスクごとに/clearする | ★☆☆ | 非常に高 | 日常的なAI利用全般 |
| 7 | 同じ誤りが続いたらリセット | ★☆☆ | 非常に高 | デバッグ・修正作業 |
| 8 | Auto-compact前に手動保全 | ★★☆ | 高 | 長期・大規模プロジェクト |
Tips 4の「few-shot collapse」は、Claude Code以外の話だけど、知っておくと視点が変わる概念だと思う。
「例示を入れれば入れるほど良くなる」という思い込みは、僕も持ってた。モデルやタスクによっては例示が完全に裏目に出るという事実は、AI活用の設計を考える上でかなり重要な知識だ。気になった人は実際に0-shotと8-shotを比較してみるといい。

よくある質問(FAQ)
Q1|プロンプトエンジニアリングとコンテキストエンジニアリングの違いは何か
プロンプトエンジニアリングは「AIへの指示の言葉遣いや構造」を工夫する手法だ。一方、コンテキストエンジニアリングは「AIに与える背景情報全体(会話履歴・外部データ・システム設定など)の質と量」を管理・最適化する手法だ。
どれだけ完璧な指示文を書いても、前提となる情報がノイズだらけだったり不足していたりするとAIは正しい回答を出せない。プロンプトが「指示の出し方」なら、コンテキストは「情報の渡し方」だ。2026年現在、AIの回答品質を本当に上げたいなら、プロンプトの磨き込みよりコンテキストの整理を先に取り組む方が費用対効果が高い。
Q2|コンテキストをクリア(/clear)する最適なタイミングはいつか
主に3つのタイミングが推奨される。
1つ目は「別のタスクや話題に移る時」——無関係な情報によるノイズを防ぐためだ。2つ目は「AIが同じ間違いを繰り返したり、指示を無視し始めた時」——蓄積された失敗のバイアスを断ち切るためだ。3つ目は「仕様や前提条件が大きく変わった時」——古い前提が新しい指示と衝突するのを防ぐためだ。
これらを守ることで、トークン消費を抑えながら高い回答精度を維持できる。「もったいない」と感じてクリアを躊躇う人が多いが、長いセッションを維持するコストの方がはるかに高くつく。
Q3|few-shot(例示)を入れると精度が下がることがあるのはなぜか
特定のモデルとタスクの組み合わせでは、例示に引きずられて本来の推論能力が阻害される「few-shot collapse(崩壊)」という現象が起きるからだ。
一般的には例示を増やすほど精度は上がるが、複雑な論理推論タスクや、特定の推論特化モデルでこの崩壊が発生しやすい傾向がある。12モデルを対象にした実験では、0-shotで93%の精度を出していたモデルが8-shotで30%まで落ちたケースも確認されている。例示を入れて回答がおかしくなったと感じたら、あえて例示を外した0-shotで試し直すのが有効だ。
Q4|AIに複雑なコーディングや長文作成を依頼するコツは何か
「一度にすべてをやらせない」ことが最大のコツだ。
AIは一度に出力できる量に限界があり、無理に1回で処理させようとすると品質が著しく低下する。人間が大きな仕事を分割するように、「まずは要件整理」「次にAの機能だけ」「その次にBの機能」と、タスクを小さく分割して1つずつ指示を出す。これだけで結果の品質は別物になる。また、タスクを分割することでどのステップで問題が起きたかも特定しやすくなるため、デバッグコストも下がる。
Q5|コンテキストウィンドウが巨大なモデルなら、履歴をクリアしなくても大丈夫か
大丈夫ではない。クリアすべきだ。
最新のモデルは本1冊分以上の情報を一度に読み込めるが、入力情報が多すぎると「コンテキストの品質劣化」が起こる。重要な指示が過去の無駄な会話の中に埋もれてしまい、AIが本当に集中すべき情報を見失う(Lost in the middle現象)。また、無駄な履歴を毎回送信することでAPIのトークン消費も跳ね上がる。「コンテキストウィンドウが大きい=何でも詰め込んでいい」は誤解だ。ウィンドウの大きさと情報の質は別の話だ。
まとめ|コンテキストを制する者がAIを制する
8つのTipsを振り返ると、共通するメッセージは1つだ。「AIに渡す情報のノイズを減らし、純度を高めること」——これがコンテキストエンジニアリングの本質だ。
まず今日から始めるなら、「1つのチャットで1つのタスクだけを扱う」ことを徹底するといい。話題が変わるたびに/clearでリセットする習慣をつけるだけで、AIの回答品質は明らかに変わる。
難しい技術は何もいらない。コンテキストを整理する習慣だけで、同じモデルから引き出せる価値が大きく変わる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
