
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
巨大プロンプトの限界と「エージェントOS」への転換
1つの巨大なプロンプトですべてを解決する手法は限界を迎えている。どれだけ指示を詰め込んでも、AIは長すぎる命令を無視し、複雑な業務ロジックで迷子になる。
最新の海外事例では、AIを単一の知能としてではなく、複数の専門スキルを束ねる「OS」として設計する手法が主流だ。40億パラメータの音声特化モデルや、12.5Hzのフレーム単位で制御される音声合成、何百ものAPIを動的に使い分けるオーケストレーション層が活用されている。
この「モジュール化」へのシフトが、プロトタイプと実用レベルのプロダクトを分ける境界線だ。この設計思想により、メンテナンス不能なプロンプトの肥大化を防ぐ。
企業のカスタマーサービスを支える「AMP」と次世代音声AIの衝撃
AIエージェント管理プラットフォーム(AMP)という概念が、エンタープライズ領域で台頭している。ガチガチに固められたインテントツリーを作る必要はない。
最新のシステムでは、開発者は自然言語でエージェントの役割、ツール、境界線を定義する。次世代の推論モデルが状況に応じて最適なツールを呼び出し、多段階のリクエストを処理する。
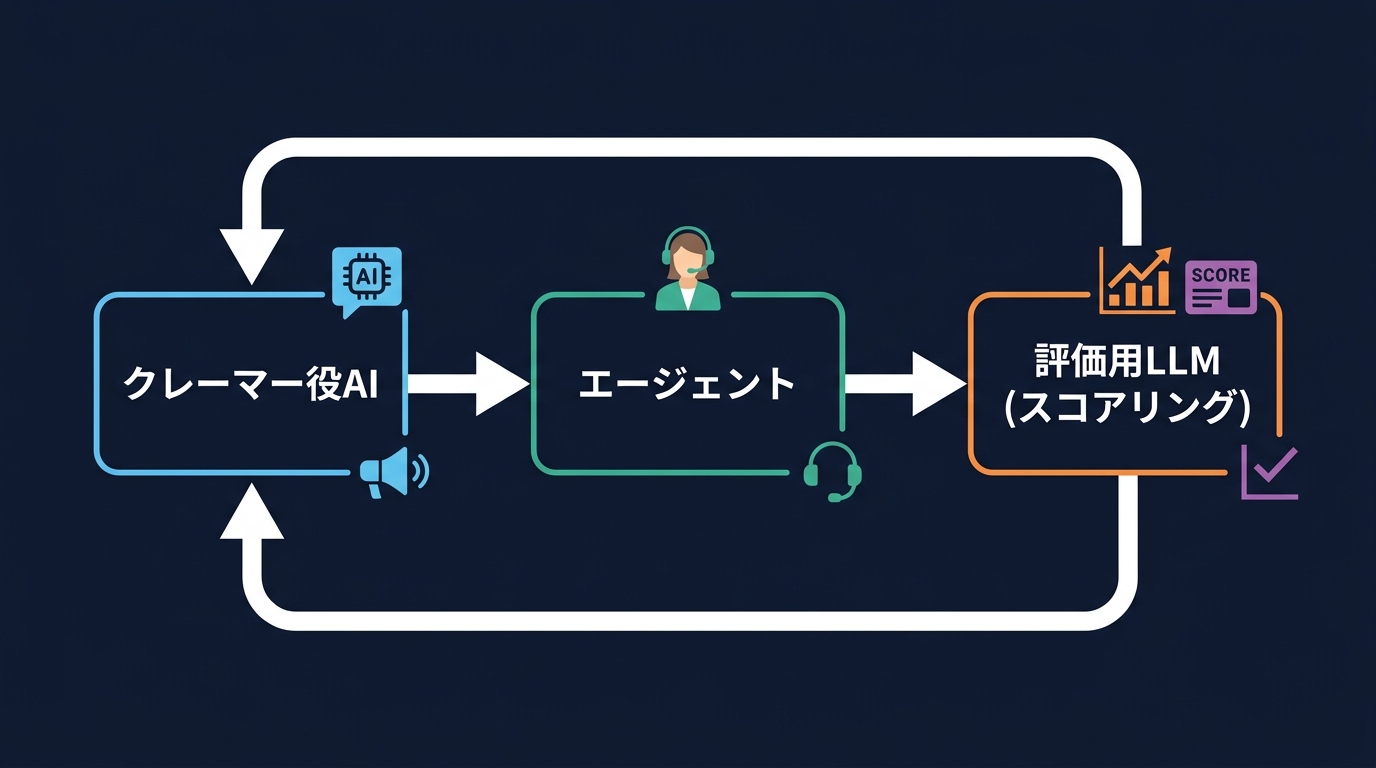
シミュレーションと評価のプロセスがシステム化されている。1つのモデルが「顧客」を演じ、もう1つのモデルが「エージェント」として対応する。
この対話をLLM-as-a-judgeがスコアリングし、デプロイ前に品質を担保する。決定論的なチェックとLLMによる定性評価を組み合わせ、本番環境での事故を未然に防ぐ。
音声AIの領域でもハイブリッド・アーキテクチャが採用されている。意味論を司る34億パラメータのデコーダーと、音響特性を司る3.9億パラメータのフローマッチング・トランスフォーマーを分離する。
わずか3秒の参照音声から、9ヶ国語で話者の特徴をコピーする。このモデルは、NVIDIA H200 1枚で30人以上の同時ユーザーを捌き、レイテンシは600ミリ秒以下で動作する。
しんたろー:
1つのモデルに全部やらせる非効率さが数字で見える。音声合成で「意味」と「音」を分ける設計は、バックエンド開発で「ロジック」と「プレゼンテーション」を分ける感覚に近い。単一の巨大モデルでは推論コストとレイテンシが爆発する。タスクを特化モデルに分けるのが今の正解だ。

開発者目線で読み解く「スキルベース・アーキテクチャ」の正体
プロンプトの肥大化は技術的負債を生む。1つのプロンプトに役割やルールを書き連ねると、AIは優先順位を見失い、ハルシネーションを連発する。
これを解決するのが、スキルベースのエージェントシステムだ。AIエージェントを、個別のスキルを呼び出すためのカーネルとして設計する。各スキルは独立したモジュールとして定義される。
- メタデータ: 名前、説明、カテゴリ、バージョン。
- スキーマ: 入出力のデータ構造。
- 実行ロジック: API呼び出しやPythonスクリプト。
設計の肝は動的ルーティングだ。ユーザーの入力に対し、エージェントは必要なスキルを判断し、ロードして実行する。Claude Codeも、コンテキストに応じて最適なツールを選択する自律性で動作する。
ThreadPostの開発でも役割分離が重要だ。SNS投稿、画像解析、スケジューリングを1つの巨大な命令セットにまとめると、デグレードが起きる。機能を独立したスキルとして切り出し、APIを介して結合する。この疎結合な設計がAI開発におけるクリーンアーキテクチャだ。
プロンプトエンジニアリングで頑張る時期は過ぎた。今は「どうやって機能を切り出すか」「どうやって評価を自動化するか」というエンジニアリング寄りの課題が面白い。複雑なプロンプトを書くより、機能をAPIとして切り出してエージェントに道具として渡すほうが確実だ。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
僕らの開発にどう影響するか。今日から変えるべき設計指針
巨大プロンプトをツール定義の集合に書き換える。
1. スキル・レジストリの構築
エージェントに直接命令を書くのをやめる。代わりに、エージェントが使えるツールのカタログ(レジストリ)を作る。各ツールにはLLMが理解しやすい詳細な説明文を付ける。
2. LLM-as-a-judge による継続的評価
開発フローの中に評価専用のLLMを組み込む。本番の会話ログをサンプリングし、指示への従順さやツールの使用方法を自動でスコアリングする。スコアが80点以下ならアラートを出す仕組みで信頼性を向上させる。
3. ハイブリッド・パイプラインの採用
マルチモーダルな要素を含む場合、意味と表現を分離する。テキスト生成には推論に強いモデルを使い、音声合成には表現力に特化した小型モデルを使う。タスクの性質に応じてモデルを使い分けるパイプラインがコストと品質の最適解だ。
4. シミュレーション環境の構築
ユーザーに触れさせる前に、AI vs AIのデバッグを徹底する。クレーマー役や初心者役のAIをプロンプトで作り、自分のエージェントを攻撃させる。見つかったエッジケースをスキルの制約事項にフィードバックする。
AI開発も伝統的なソフトウェア工学に回帰している。モジュール化、テスト、評価、デプロイ。魔法の杖を探すのをやめて、堅牢なシステムを組む。これが近道だ。
FAQ
Q1: モジュール化すると、逆にエージェントの文脈理解が低下しませんか?
A1: 文脈理解の低下は、オーケストレーション層でのコンテキスト管理で解決する。各スキルに渡す情報を必要最小限に絞り、共通のステート管理層で会話履歴を保持することで、巨大なプロンプトによる指示の埋没を防ぐ。スキル間のデータ受け渡しを構造化し、必要な文脈だけを抽出して渡す設計にする。
Q2: LLM-as-a-judgeによる評価は、コストが高すぎませんか?
A2: 開発フェーズでのシミュレーションや、本番環境でのサンプリング評価に限定することで最適化する。GPT-4o-miniのような軽量モデルを評価者に使うことで、コストを抑えつつ品質を担保する。信頼性の高いシステムを作るための品質保証コストと割り切る。
Q3: 音声AIで「表現力のギャップ」を埋めるには、何から始めるべきですか?
A3: 意味論と音響のパイプラインを分離する。最新のハイブリッドモデルを採用するか、既存のTTSに感情パラメータを外部から注入する。単一モデルに感情表現まで期待せず、プロンプトで感情のトーンを明示し、音響モデルの制御信号として活用する。24kHzの高品質な波形を、600ms以下の低遅延で提供できる構成を目指す。
まとめ:AIを「OS」として設計する勇気
今回の知見をまとめると、プロンプトを捨てる勇気がエージェントをプロダクトに変える。
- 単一モデルから専門モジュールのオーケストレーションへ。
- 指示の羅列からスキルのレジストリへ。
- 勘による開発からLLM-as-a-judgeによる評価へ。
このシフトは、書くべきコードの増加を意味する。しかし、制御可能な領域も増える。AIの気まぐれに一喜一憂するフェーズは終わりだ。設計したOSの上で、AIという強力なリソースを走らせる。
AIエージェントを「OS」として設計する手法を、開発環境に取り入れる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
