
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
1時間で動く。30分でPRが出る。速さが生む新たな罠
1時間で動くものが作れる。
30分でPRが出る。
実装スピードが上がった。
その手軽さが最大の落とし穴になる。
状態管理とプロセスの境界設計。
これが今の開発者の主戦場だ。
実装が数十分で終わるからこそ、泥臭いアーキテクチャ設計から逃げられない。
手軽さに流されたシステムは必ず破綻する。
マルチステップで崩壊するAI。見直される「OS的」アプローチ
複数のAI開発フレームワークやIDEのアップデートが相次いでいる。
UI上で手軽に「サブエージェント」や「スキル」を追加できるようになった。
開発のハードルは極端に下がった。
だが、現場ではマルチステップのタスクで破綻するケースが続出している。
短いループ処理はうまくいく。
状態を伴う長いタスクになると途端におかしくなる。
理由はシンプルだ。
コンテキストの欠如と観測不可能性だ。
単にチャットAIを導入しても、期待した価値が出ない。
会話ができるだけではビジネスの価値にはならない。
AIがビジネスの文脈を理解し、業務プロセス自体がAIで処理しやすい形になっている必要がある。
市場の評価もシビアだ。
B2B市場では二極化が起きている。
- データ基盤を前面に出す企業は140%以上の成長
- AI時代に不可欠なセキュリティ企業も70%の急伸
- 従来型のエンタープライズSaaS企業は30%以上の株価調整
- 単なるAI機能の追加ではなく、根本的なデータ設計が問われている
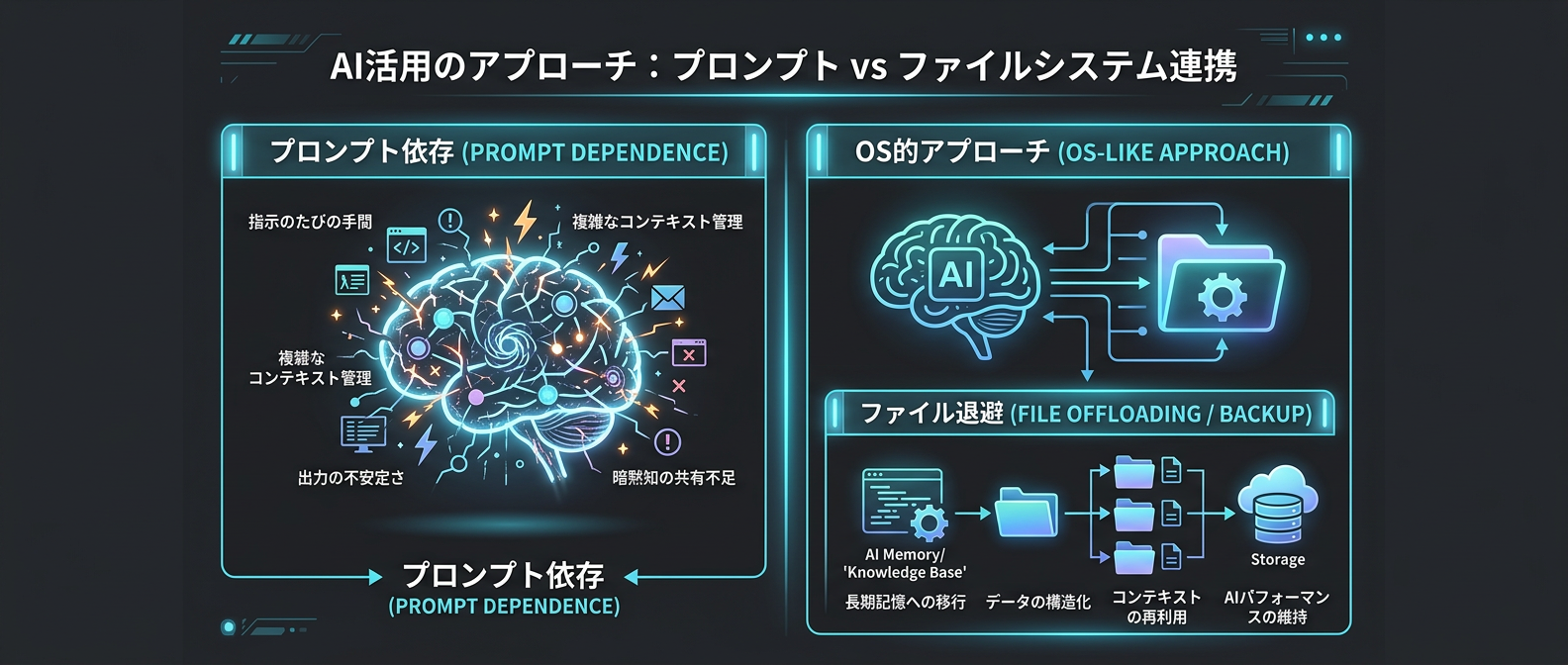
ここで注目されているのが、状態管理とプロセス分離のアプローチだ。
マルチステップで状態を伴うタスクにおいて、AIは計画を立て、記憶を保持し、コンテキストを隔離する必要がある。
すべてをプロンプト内に保持しようとすると、すぐにトークン制限を突破する。
中間生成物のデータサイズが膨れ上がる。
状態の管理がアプリケーション開発者任せになっているのが現状だ。
そこで、ファイルシステムを仮想的に活用する動きが活発化している。
中間生成物や大きな出力をファイルに書き出して退避させる。
必要な時に再度読み込む。
この「OS的」なアプローチが再評価されている。
さらに、プロセスの観測可能性も焦点になっている。
軽い処理だからと、AIにサブタスクを安易に委譲する。
すると、親プロセスの中にコンテキストが閉じてしまう。
外部から状態遷移を確認できない。
再実行や承認フローの介入もできない。
結果として、システム全体でのデバッグや運用管理が不可能になる。
これを防ぐため、独立したプロセスとしてエージェントを切り出すアーキテクチャが支持を集めている。
AIの実装ハードルが下がった反面、開発者はコンテキストの永続化やプロセスの観測・制御といった泥臭い設計に向き合う必要がある。
しんたろー:
1時間で動くものが作れるのは最高なんだけど、その後のデバッグで地獄を見る。
ブラックボックス化したエージェントの暴走ほど怖いものはない。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
速さは設計を代替しない。Claude Code時代のアーキテクチャ論
ここからは開発者の視点で深掘りする。
Claude Codeで毎日コードを書いている身として、この変化は痛いほどわかる。
実装コストが下がりすぎた。
30分調べるくらいなら、30分で作って試せばいい。
この判断は一見合理的だ。
高速なフィードバックサイクルで「作って壊す」を回せる。
結果的に正解にたどり着ける気さえする。
だが、速さは設計を代替しない。
「作って壊す」が速いことと「正しい設計判断ができている」ことは全く別の話だ。
仕事の本質は「情報収集」「判断」「実行」のサイクルだ。
人間でもAIでもこれは変わらない。
AIが価値を生むためのサイクルは以下のようになる。
- 現状把握や情報収集を行うフェーズ
- 収集したデータから答えや判断を導き出すフェーズ
- 最終的なアクションを実行するフェーズ
- これらの点と点をシームレスにつなぐこと
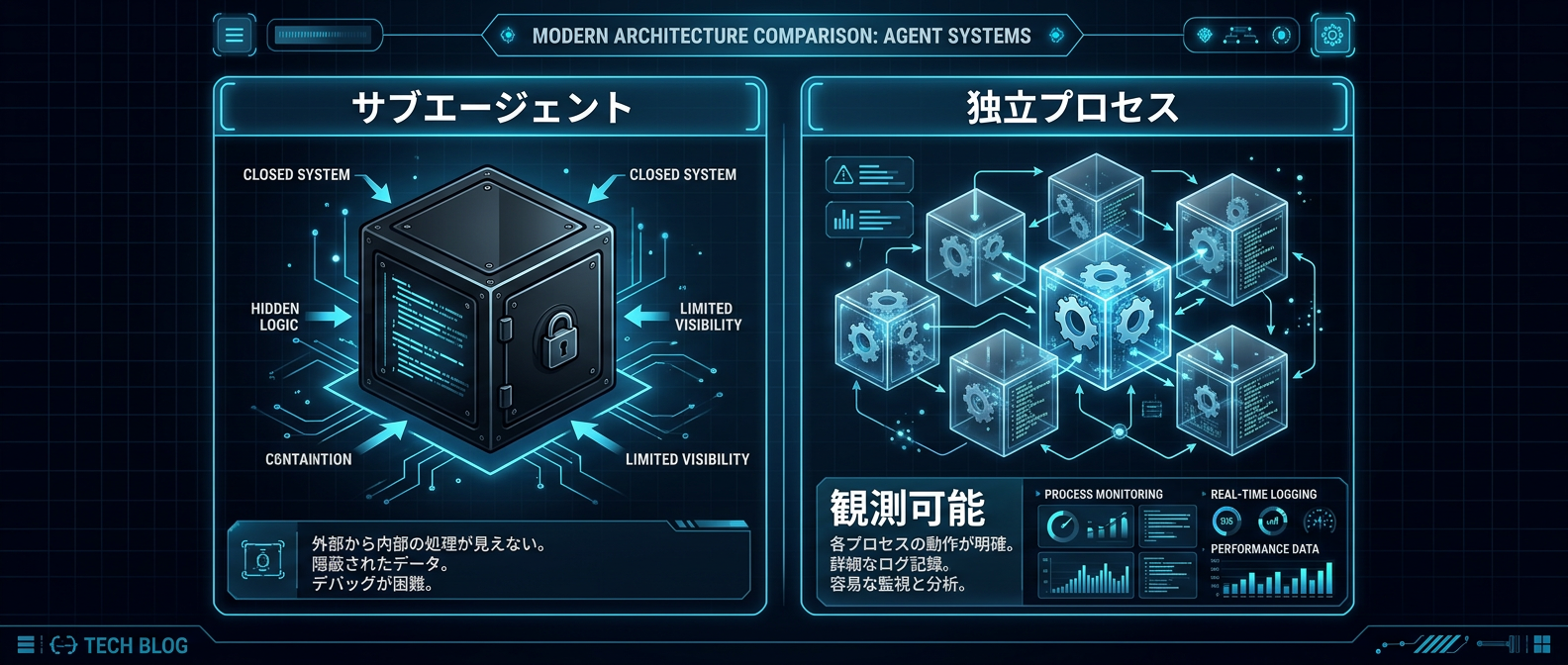
軽い処理だから「サブエージェント」でいい。
この判断がシステムを壊す。
サブエージェントの実行ログは確かに存在する。
しかし、システムの一部として観測・制御できる形で残っているかが問われる。
親プロセスに閉じたコンテキストは、外部から手出しできない。
独立プロセスとして切り出せば、ログが残る。
状態遷移が外部から読み取れる。
プロセス間通信や状態管理のインフラに乗せられる。
独立プロセス化のメリットは以下の通りだ。
- プロセス管理ツールからの観測が可能になる
- 実行ログがシステムのエコシステムに自然に収まる
- 状態遷移が外部から読み取れる
- 人間が最終的なコントロールを握れる
AIエージェントというバズワードの下で起きているのは、先祖返りだ。
「状態管理」「ファイルシステムへの退避」「プロセス間通信」。
従来のOSやバックエンド開発に近いパラダイムが戻ってきた。
シェルスクリプトとパイプでプロセスをつなぐ。
この枯れた技術が、AIエージェントの制御にピタリとはまる。
もう一つ、AIの「スキル」に対する誤解も解いておく。
IDEの進化により、スキルやエージェントがUI上のプルダウンから選べるようになった。
すると、ユーザーはこれらを「インストールして使う機能」と錯覚する。
本来、スキルは無詠唱で発動するものだ。
文脈が条件を満たしたときに、モデルが自然に参照する補助知識だ。
毎回人が選ぶ機能ではない。
ここを取り違えると、開発者は構文論に逃げる。
YAMLで書くか、JSONで書くか。
文字数は何文字にするか。
そんなものは運用設計の問題をすり替えているだけだ。
LLMはコンパイラではない。
厳密な入力言語をパースして決定論的に出力する機械ではない。
文脈全体から意味を補完して行動を組み立てる機械だ。
スキルの本質的な設計要素は構文ではない。
- どのような文脈で発火するかの条件定義
- どこまでをそのスキルが担うかの責務の境界
- エラーが起きた場合の例外条件
- 人間に判断を仰ぐエスカレーションのルール
- 期待通りに動いたかの検証方法
これらを定義せずにスキルを量産しても、システムは賢くならない。
UIに見えているものほど、設計上どの階層に属するのかを意識して分ける必要がある。
機能一覧と記法の工夫の話に引きずられてはいけない。
Claude Codeのsubagent機能は便利だけど、使い所を間違えると本当に追えなくなる。
うちの構成だと、外部API叩く部分は独立プロセスにしてログ吐かせないと怖くて眠れない。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
1人SaaS開発で生き残るためのコンテキスト永続化と境界設計
で、僕らの開発にどう関係するのか。
1人SaaS開発の現場でも、このパラダイムシフトは直撃する。
単一のLLM呼び出しで完結する機能はもう少ない。
複数のエージェントが連携し、長期間のコンテキストを維持する機能が当たり前になる。
まず、コンテキストの永続化に向き合う。
プロンプトエンジニアリングの限界を認める。
なんでもかんでもプロンプトに詰め込むのは悪手だ。
10万トークン入るからといって、全部入れるわけではない。
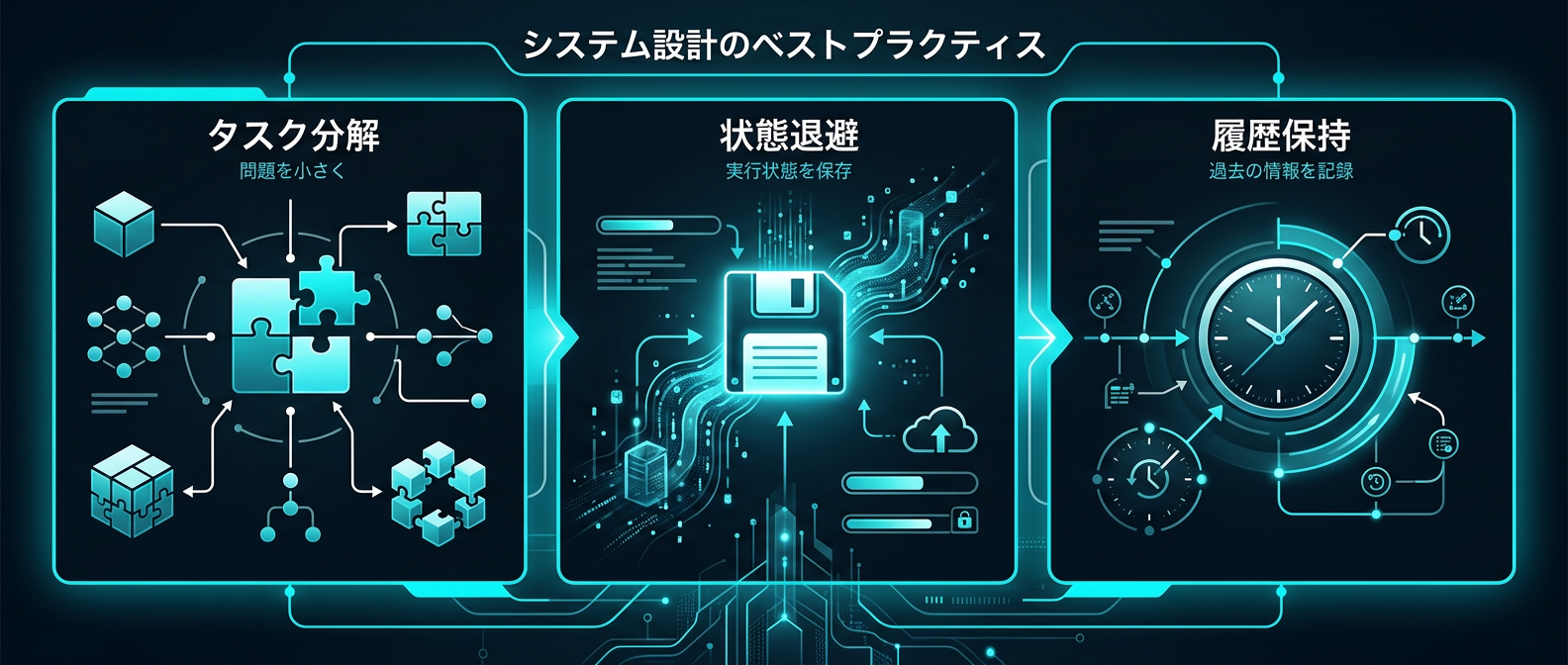
コンテキスト管理の具体的な手法を実践する。
- 複雑なタスクを細かいステップに分解する
- 進行状況をトラッキングして計画を更新する
- 大きな出力結果はファイルに書き出す
- プロンプトのウィンドウから不要な情報を逃がす
この「仮想的なファイルシステム」の構築が、安定したAI機能の土台になる。
さらに、時間軸を持ったコンテキストの管理が鍵になる。
ビジネスの文脈は静的ではない。
その時点のスナップショットだけを見ても意味がない。
どういう経緯でその状態になったのか。
前回の実行結果から何がどう変化したのか。
変化の履歴をコンテキストに含める。
この動的な情報のつながりが、AIの推論精度を底上げする。
次に、観測可能性の確保。
エージェントの行動をブラックボックスにしない。
独立したプロセスとして動かす。
状態をファイルに書き出す。
外部から現在のステータスを監視できるようにする。
人間が途中で介入できる設計を残す。
完全自動化を急がない。
承認フローやエラー時のエスカレーションルートを明確にする。
これがシステムの暴走を防ぐ手段だ。
そして、事前の設計要件定義。
実装が30分で終わるからこそ、設計に時間をかける。
「とりあえず動かす」の誘惑に勝つ。
アーキテクチャ設計で意識することは変わらない。
- 実装の軽さに騙されない
- 既存のシステムアーキテクチャとの一貫性を保つ
- 設計要件を事前に洗い出す
- システムから観測・制御できるインターフェースを用意する
ThreadPostのようなSNS運用ツールを想定してみる。
投稿の生成、スケジューリング、分析。
これらを一つの巨大なエージェントに任せると必ず破綻する。
責務を分離し、それぞれを独立したプロセスとして観測可能にする。
これがスケーラビリティを生む。
結局、泥臭いバックエンドの設計知識が一番活きる。
AIがコードを書いてくれる時代になっても、システム全体のアーキテクチャを描くのは人間の仕事だ。
AIエージェント設計の核心に迫るFAQ
Q1: AIエージェントのコンテキスト溢れを防ぐにはどうすればよいですか?
ファイルシステムや外部ストレージを仮想的に活用する。中間生成物や大きな出力をファイルに書き出して退避させる手法が有効だ。すべてをプロンプト内に保持するのではなく、必要な時に再度読み込む設計にする。これでトークン制限を回避しつつ、長期的な状態を維持できる。メモリという曖昧な概念ではなく、物理的なファイルへの入出力として扱うのが確実だ。
Q2: サブエージェントと独立したプロセスのどちらを選ぶべきですか?
外部からの観測可能性や制御可能性が必要な場合は、独立したプロセスとして実装する。処理自体が軽くても、ログの確認や状態遷移の追跡、再実行の介入が必要なら独立させる。サブエージェントは親プロセスにコンテキストが閉じがちだ。システム全体でのデバッグや運用管理が難しくなるリスクがある。アーキテクチャ上の位置づけで判断する。
Q3: AIのスキルやエージェントを設計する際の注意点は何ですか?
UI上の見え方や、YAMLかJSONかといった構文論に囚われない。どのような文脈で発火するか、責務の境界はどこか、例外時のエスカレーションはどうするかといった運用設計に注力する。スキルは機能一覧から選ぶものではなく、モデルが必要な時に参照する補助知識として設計する。LLMをコンパイラのように扱わず、文脈を補完する機械として扱う。
手軽さに流されず、アーキテクチャを描き切れ
実装が数十分で終わる時代。
だからこそ、泥臭い状態管理とプロセスの境界設計に向き合う開発者だけが生き残る。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
