
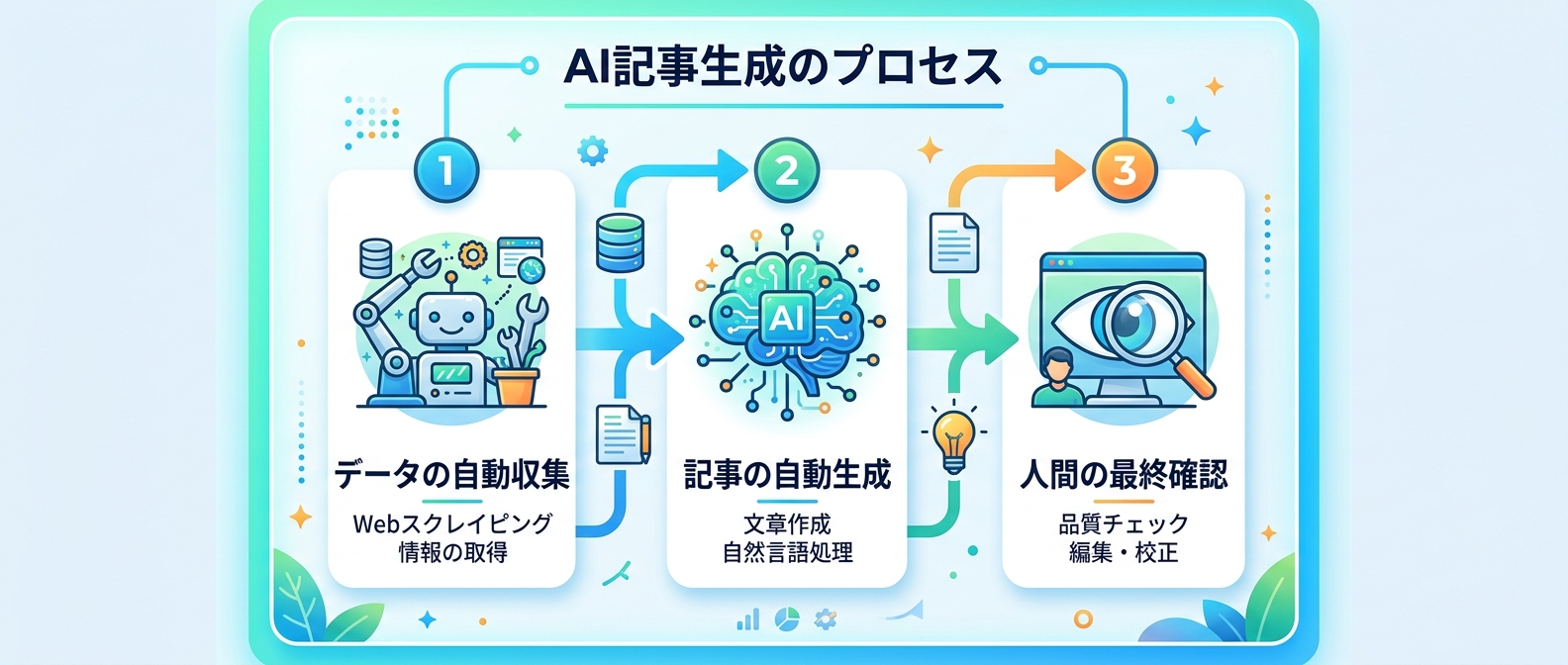
Web上のデータを自動で集めて、そのままブログ記事にしてくれたらどんなに楽だろうと思ったことはないだろうか。
結論から言うと、今のAI技術を使えばそれは完全に可能だ。
しかも、プログラミング初心者でも正しい手順を踏めば、今日から自分のパソコンで動かすことができる。
この記事では、Webデータ収集から構造化データの抽出、そして記事の自動生成までを1つの流れとして構築する6つのステップを解説する。
読めば何から始めればいいのかが明確になるはずだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
前提知識と必要な準備
まず始める前に必要なものを整理しよう。
パソコンとインターネット環境はもちろん、Pythonを実行できる環境が必要になる。
また、AIにデータを処理させるためのOpenAIアカウントも必須だ。
これさえあれば、あとは順番に進めるだけで自動化の仕組みが完成する。
Step 1: 環境構築とAPIキーの準備
まずは開発環境を整えるところから始めよう。
Pythonで開発を進める際、一番最初にやるべきなのは仮想環境の作成だ。
仮想環境を作ることで、他のプロジェクトと設定が混ざるのを防げる。
必要なパッケージは以下の5つになる。
- 通信用パッケージ: Webサイトからデータを取得するための通信係
- 解析用パッケージ: 取得したWebページの構造を解析するツール
- OpenAI公式パッケージ: AIにテキストを処理させるための専用ツール
- データ定義パッケージ: 抽出したいデータの形を厳密に定義するツール
- 環境変数管理パッケージ: 秘密のパスワードなどを安全に管理する仕組み
これらをインストールしたら、次はAPIキーの設定だ。
OpenAIのAPIキーを直接プログラムの中に書き込むのは非常に危険だ。
必ず環境変数ファイルを作成して、そこに保存しよう。
さらに、バージョン管理システムを使っている場合は、そのファイルを無視する設定を忘れないようにする。
これを怠ると、世界中に自分のAPIキーを公開することになり、高額な請求が来る恐れがある。
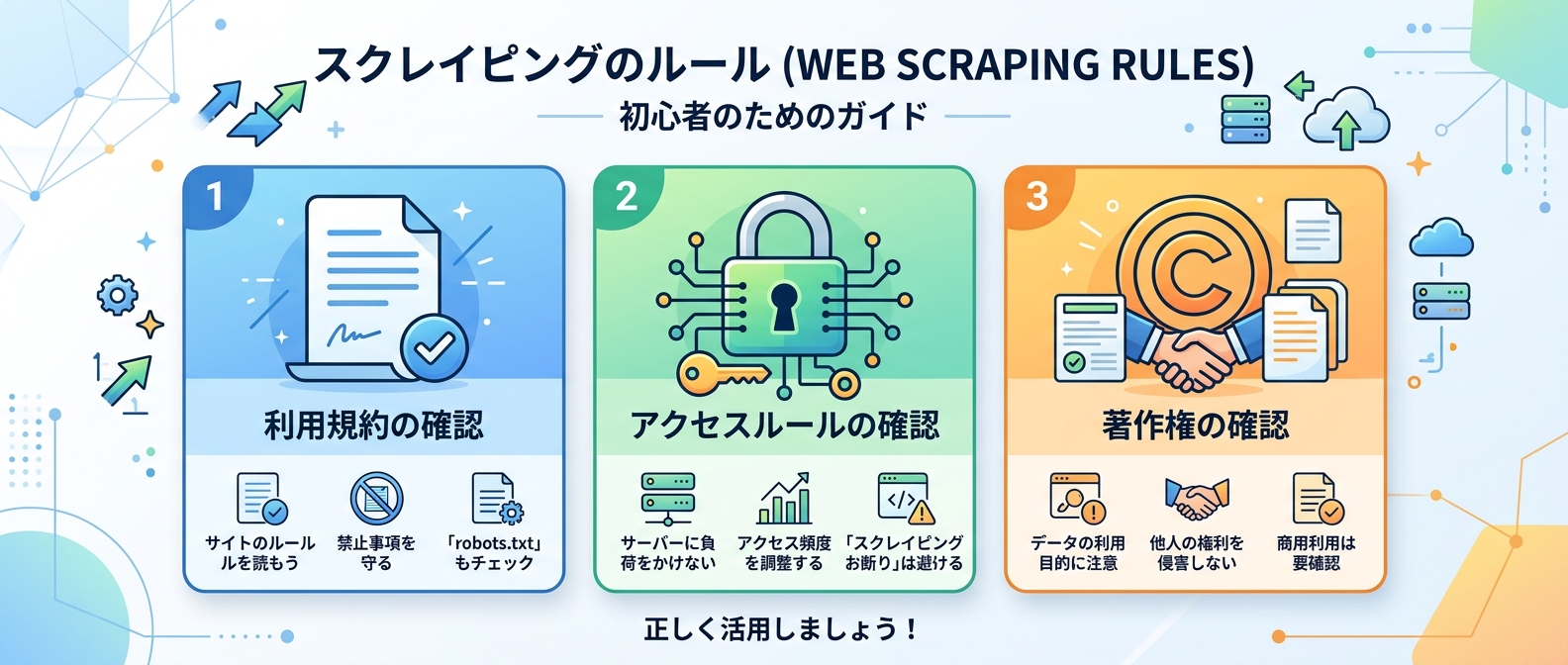
Step 2: 対象サイトの規約確認とアクセス許可チェック
環境が整ったらすぐにデータを集めたくなるが、注意が必要だ。
Web上のデータ収集には、守るべきマナーとルールが存在する。
まず、対象となるサイトの利用規約を隅々まで確認しよう。
自動アクセスを明確に禁止しているサイトは意外と多い。
次に確認すべきは、サイトのアクセスルールを記したテキストファイルだ。
プログラムを使って、このファイルにアクセス許可が書かれているかを自動で判定する仕組みを組み込むといい。
これをやらないと、最悪の場合は法的なトラブルに発展する。
- 利用規約の確認: 自動収集が明確に禁止されていないか
- 著作権の確認: 取得したデータをそのまま公開して問題ないか
- アクセスルールの確認: プログラムからのアクセスが許可されているか
初心者のうちは、スクレイピングの練習用に用意された専用のサイトを使うのが一番安全だ。
練習用サイトなら、気兼ねなくプログラムの動作テストを行える。
Step 3: HTMLの取得とクリーニング(ノイズ除去)
安全が確認できたら、いよいよデータの取得だ。
通信用のパッケージを使ってWebページの生データを取得する。
しかし、ここで取得したデータをそのままAIに渡してはいけない。
Webページには、人間には見えない裏側の設定や、デザインを整えるためのコードが大量に含まれているからだ。
ここで解析用のパッケージの出番となる。
記事の作成に全く関係のない不要な要素を、プログラムで徹底的に削ぎ落とすのだ。
具体的には以下のような要素を削除する。
- 画面に動きをつけるためのプログラムコード
- 見た目や色を整えるためのデザイン指定コード
- サイト内の他のページへ案内するナビゲーションメニュー
- ページの一番下にあるフッター情報
これらを削除するだけで、AIに渡すデータ量を劇的に減らせる。
データ量が減れば、AIの処理速度が上がり、利用料金も大幅に節約できる。
まさに一石二鳥の重要な工程だ。
Step 4: OpenAI APIによる構造化データの抽出
きれいになったテキストデータを、いよいよAIに渡す。
ここで使うのは、コストパフォーマンスに優れた最新の小型モデルだ。
ただテキストを渡すだけでなく、欲しいデータの形を明確に指定するのが成功の鍵になる。
たとえば、中古車の情報を集めるなら以下のような項目を指定する。
- 走行距離: 数値としてのデータ
- 年式: 製造された年
- 車検: 車検の残り期間
- 修復歴: あり・なしの判定
データ構造を厳密に定義する専用のパッケージと、OpenAIが提供する出力を固定する最新機能を組み合わせることで、AIは指示通りのきれいなデータを作ってくれる。
昔のAIはよく項目を飛ばしたり、勝手にフォーマットを変えたりしたが、今の技術ならその心配はほとんどない。
確実に狙った情報を引き出せるのが、今のAIの本当にすごいところだ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
Step 5: Markdown記事の自動生成と保存
必要な情報がきれいに抽出できたら、次は記事の作成だ。
抽出したデータと、このデータを使ってブログ記事を書いてという指示をセットにして、もう一度AIに投げる。
AIは与えられた事実データだけを元に、読みやすいブログ記事の形式で文章を生成してくれる。
生成された記事は、パソコン内の専用フォルダに自動で保存する仕組みを作ろう。
このとき、ファイル名には必ず実行した日付と時間を含めるのがおすすめだ。
- 記事のフォーマットはブログで使いやすい形式を明確に指定する
- 実行日時をファイル名に入れて過去のファイルを上書きするのを防ぐ
- 保存先のフォルダが存在しない場合は自動で作るように設定する
こうすることで、毎日プログラムを動かしてもファイルが整理された状態を保てる。
後から人間が確認したり編集したりする際にも、非常に管理がしやすくなる。
Step 6: ドメイン変更時の注意と運用フローの確立
ここまでで一連の流れは完成だ。
この仕組みができれば、次は不動産情報も中古車情報も同じように集めようと思うはずだ。
結論から言うと、仕組みの骨組みは流用できるが、中身は大幅な書き直しが必要になる。
なぜなら、サイトが違えばページの構造も、抽出したい情報も全く異なるからだ。
不動産なら築年数が必要だし、中古車なら走行距離が必要になる。
サイトごとの違いを吸収するための専用の処理を、個別に開発しなければならない。
また、一番重要なのは運用フローだ。
AIが作った記事を、誰も確認せずにそのままインターネットに公開するのは絶対にやめよう。
AIは時々、もっともらしい嘘をつくことがある。
間違った価格や存在しないスペックを公開してしまうと、サイトの信用は一瞬で地に落ちる。
必ず人間が元のデータと見比べて、事実確認を行う工程を挟むべきだ。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、こういう自動化スクリプトの開発は本当に一瞬で終わる。
理由はシンプルで、要件を伝えるだけで必要なライブラリの選定からエラーハンドリングまで全部やってくれるからだ。
サイトごとの面倒な処理の書き直しも、Claude Codeに任せれば手作業の数分の一の時間で完了する。
初心者がハマりやすい3つのつまずきポイント
ここで、実際に手を動かす際によくある失敗を共有しておく。
事前に知っておけば、無駄な時間を過ごさずに済むはずだ。
1. 秘密のキーを公開してしまう
一番多いのが、AIの利用に必要なキーをそのままソースコードに書いてしまうミスだ。
そのままインターネット上のコード共有サービスにアップロードすると、世界中から不正利用される。
必ず環境変数という仕組みを使って、コードとは別の安全な場所に保管しよう。
2. データ量が多すぎてエラーになる
Webページのデータを何も処理せずにAIに投げると、一度に処理できる文字数の上限に引っかかる。
エラーで止まるだけでなく、無駄な通信料金が発生してしまう。
先ほど解説したノイズ除去の工程は、絶対に飛ばしてはいけない。
3. 全てをAI任せにしてしまう
自動化という言葉に惹かれて、最終確認まで省いてしまうケースだ。
AIは完璧ではない。
特に数字や固有名詞については、間違える前提でシステムを設計する必要がある。
人間の目による最終チェックは、システムの一部として必ず組み込もう。
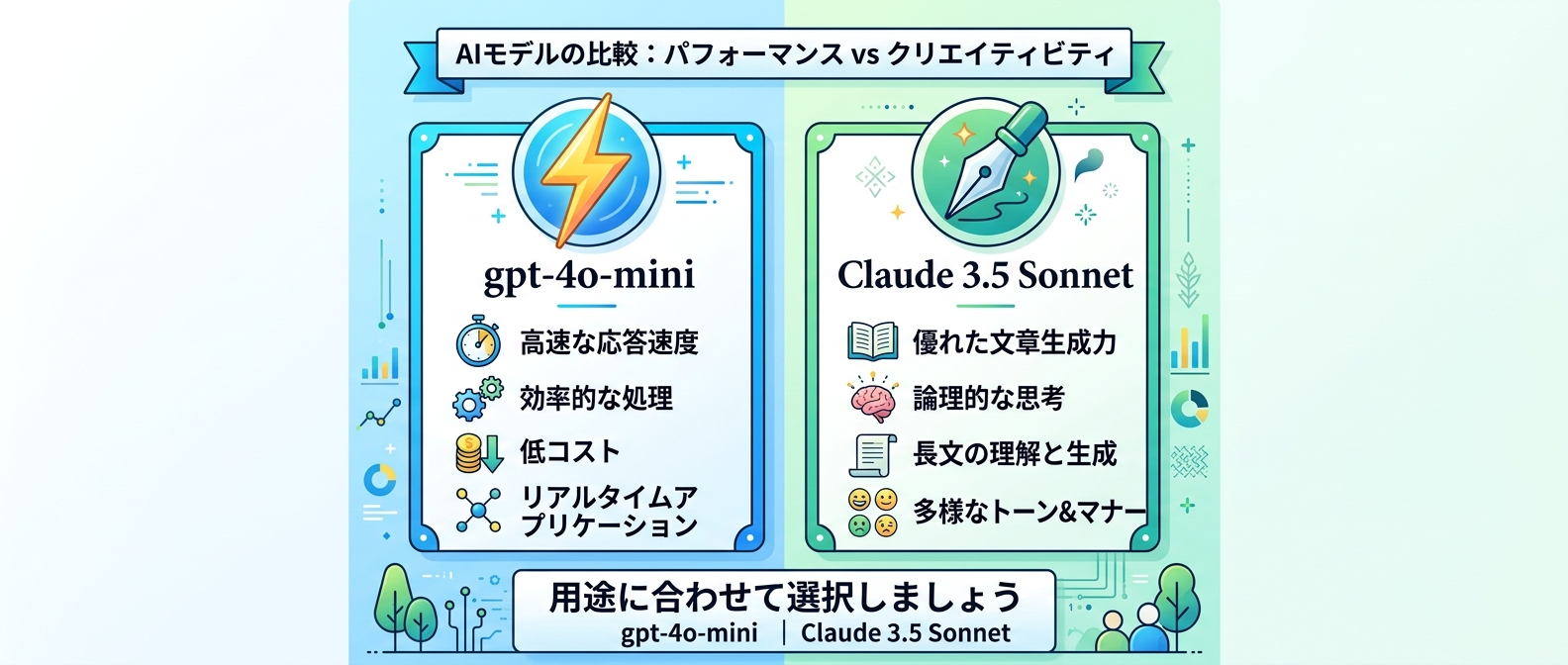
記事生成AIモデルの徹底比較
記事生成のパイプラインに組み込むAIモデルは、どれを選ぶべきか。
用途に合わせた比較表を作成したので参考にしてほしい。
| モデル名 | 得意な処理 | コスト感 | おすすめ度 |
|---|---|---|---|
| gpt-4o-mini | データの構造化抽出、大量処理 | 非常に安い | ★★★★★ |
| gpt-4o | 複雑な推論、高品質な文章生成 | やや高い | ★★★☆☆ |
| Claude Haiku | 走行距離や年式などの分析 | 非常に安い | ★★★★☆ |
結論から言うと、日常的に大量のデータを処理するなら、一番上の安価なモデルが圧倒的におすすめだ。
速度も速く、構造化データの抽出精度も申し分ない。
文章の質に極限までこだわる特別な記事だけ、他のモデルを使い分けるといい。
比較表にはいろいろ書いたが、自動化の裏側で動かすなら安くて速いモデル一択だ。
別のツールもいくつか気になっているものはあるが、まずは一番標準的なものから試すのが上達の近道になる。
よくある質問(FAQ)
Q1: スクレイピングは違法ですか?
スクレイピング自体は違法ではないが、やり方によっては法的な問題に発展する恐れがある。
まず、対象サイトの利用規約で自動収集が禁止されていないか、アクセスルールで制限されていないかを確認する必要がある。
また、収集したデータをそのまま公開すると著作権侵害になる恐れがあるため、取得したデータを元に独自の分析や考察を加えたコンテンツに変換することが重要だ。
不安な場合は法務担当者に相談するといい。
Q2: 別のサイトのデータを集める場合、同じコードをそのまま流用できますか?
基本的な処理の流れは流用できるが、コードの大部分は書き直しが必要になることが一般的だ。
例えば不動産サイトと中古車サイトでは、抽出したい情報が全く異なる。
また、サイトごとにページの構造やカテゴリ分類のルールが違うため、手作業での調整や、そのサイト専用の処理を個別に開発する必要がある。
Q3: HTMLをそのままAIに渡して記事を作らせてはいけないのですか?
生のHTMLをそのままAIに渡すことは推奨されない。
HTMLにはデザイン用のタグや裏側のプログラム、ナビゲーションメニューなど、記事の文脈とは無関係なノイズが大量に含まれている。
これらをそのまま渡すと、AIの入力文字数制限に引っかかりやすくなるだけでなく、無駄な利用料金が発生してしまう。
必ず事前にテキストのみを抽出して、きれいにクリーニングしてからAIに渡そう。
Q4: AIが自動生成した記事をそのままブログに公開してもいいですか?
AIが生成した記事を無人・無確認でそのまま公開するのは非常に危険だ。
AIは、もっともらしい嘘をつく事実誤認を起こすことがある。
間違った価格や存在しないスペック情報を公開してしまうと、サイトの信頼性を大きく損なうことになる。
自動化するのはあくまで下書きの作成までとし、公開前には必ず人間が元のデータと照らし合わせて事実確認を行う運用フローを構築しよう。
Q5: OpenAI APIの料金はどれくらいかかりますか?
利用するモデルと処理するテキスト量によって変動する。
記事自動生成の仕組みでは、コストパフォーマンスに優れた小型モデルを使用するのが一般的だ。
これを使えば、1記事あたり数円から十数円程度の低コストでデータ抽出から記事生成までを行える。
開発中やテスト段階では、利用上限額を設定しておくことで、予期せぬ高額請求を防げる。
まとめ:小さく始めて運用フローを育てよう
今回は、Web上のデータ収集から記事の自動生成までの6つのステップを解説した。
まとめると以下のようになる。
- 環境とキーの準備を安全に行う
- 対象サイトの規約とルールを必ず守る
- 取得したデータはきれいに掃除する
- AIに欲しいデータの形を明確に指示する
- 生成した記事は整理して保存する
- 人間の目による最終確認を必ず行う
最初は練習用のサイトを使って、自分のパソコンでプログラムが動く感動を味わうといい。
そこから少しずつ対象サイトを広げ、自分だけの自動化の仕組みを育てていくのがおすすめだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
