
ChatGPTやClaudeを毎日使い倒していると、次は自分でAIアプリを作ってみたくなるはずだ。
でも、どこから手をつければいいか迷う人も多い。
結論から言うと、まずはPythonでLLMのSDKを触ってみるのが一番の近道だ。
この記事では、APIの基礎からセキュリティ対策まで、AIを作る側に回るための5つのステップを解説する。
初心者でも順番に進めれば、今日から自分のPCでAIを動かせるようになる。
特別な知識がなくても開発できる。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
前提知識
始める前に必要なものは以下の3つだけだ。
- Pythonが動くPC
- AnthropicやOpenAIのアカウント
- インターネット環境
特別なハイスペックマシンは必要ない。
普段使っているノートPCで十分開発できる。
まずはアカウントを作って、APIキーを発行するところから始める。
ステップ1:LLM SDKの基礎とセットアップ
LLM SDKとは、ChatGPTやClaudeなどのAIモデルをプログラムから簡単に呼び出すための道具箱だ。
直接APIと通信しようとすると、認証やエラー処理、データの変換など面倒な作業が山ほどある。
SDKはそれらをすべて肩代わりしてくれる便利な存在だ。
たとえば、Anthropicの公式SDKを使えば、数行のコードを書くだけで最新のClaudeを自分のパソコンで動かせる。
まずはPythonの環境に必要なライブラリをインストールする。
ターミナルを開いて、以下の2つを入れる。
- anthropic(AIと通信するための公式ツール)
- python-dotenv(パスワードなどの環境変数を管理するツール)
具体的には「pip install anthropic python-dotenv」というコマンドを実行するだけで準備は整う。
これで開発の土台が完成する。
複雑なネットワークの設定などは一切不要で、すぐに次のステップに進める。
ステップ2:APIキーの安全な管理方法
APIキーは、あなたが誰であるかをAIの提供元に証明するパスワードのようなものだ。
これをプログラムの中に直接書いてしまうのは、絶対にやってはいけない。
もしそのままGitHubなどの公開設定の場所にアップロードしてしまうと、悪意のあるプログラムに数分で検知される。
結果として、世界中の誰かに勝手にAIを使われ、身に覚えのない高額な請求が来る悲劇が起こる。
安全に管理するには、以下の2つのファイルを作るのが基本だ。
- .env(APIキーを保存する隠しファイル)
- .gitignore(ネットへのアップロードを除外する設定ファイル)
.envの中に「ANTHROPIC_API_KEY=あなたのキー」という形で保存する。
そして、プログラムからはpython-dotenvというツールを使って読み込むように設定する。
こうすれば、コードを誰かに見られてもAPIキーそのものが漏れる心配はない。
ステップ3:基本的なテキスト生成の実装
準備ができたら、実際にAIにメッセージを送ってみる。
プログラムの冒頭で.envを読み込む処理を書き、SDKのクライアントを立ち上げる。
あとは、使いたいモデルの名前と、AIへの質問をセットにして送信するだけだ。
たとえばモデルに「claude-sonnet-4-6」を指定して、「Pythonとは何ですか」と質問を送る。
たったこれだけで、AIからの返答を受け取れる。
ここで重要なのが、返答の最大長さを決める設定だ。
max_tokensという項目に数字を入れておくことで、AIが延々と喋り続けるのを防げる。
これを設定しないと、想定外の長文が生成されてコスト爆発するリスクがある。
テスト段階では1024くらいの余裕を持たせた数字を設定する。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、SDKの進化には本当に驚かされる。
理由はシンプルで、昔はAPIの通信エラーや再試行処理を全部自分で書く必要があって地獄だったからだ。
今は数行書くだけで安定してAIと通信できるから、開発のハードルが劇的に下がっているのを肌で感じる。
ステップ4:マルチターン会話(チャット履歴)の実装
AIと一問一答ではなく、連続して会話を成立させるには少し工夫が必要だ。
実は、LLM自体は過去のやり取りを一切記憶していない。
そのため、2回目の質問をするときは、1回目の質問と回答の履歴も一緒に送る必要がある。
これを毎回繰り返すことで、初めて文脈を理解した自然なマルチターン会話が成立する。
具体的には、プログラムの中で会話履歴を保存するリストを作る。
ユーザーが発言するたびにリストに追加し、AIの返答も同じリストに追加していく。
そして、毎回そのリスト全体をAIに送信する仕組みだ。
ただし、会話が長引くほど送るテキスト量が増えるため、通信コストが雪だるま式に高くなる。
1ターン目は100のデータ量でも、3ターン目には450を超えることも珍しくない。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
ステップ5:PII(個人情報)保護とセキュリティ対策
自分が使うだけなら問題ないが、他の人に使ってもらうアプリを作るならセキュリティ対策は必須だ。
ユーザーが入力した個人情報が、そのままAIプロバイダーのサーバーに送られるのは非常に危険だ。
氏名や電話番号、マイナンバーなどの機密情報が含まれると、重大な情報漏洩インシデントに繋がる。
これを防ぐために、CloakLLMのようなオープンソースのツールを導入する。
これは、AIにデータを送る前に個人情報を自動でマスキングしてくれる便利なミドルウェアだ。
たとえば「田中太郎のマイナンバーは」という文章を「[PERSON_0]のマイナンバーは」のように変換してくれる。
そして、AIから返ってきた回答を再び元の名前に戻してユーザーに表示する。
数行のコードを追加するだけで、安全なAIアプリを構築できる。
日本の電話番号や名前に対応しているツールを選ぶのがポイントだ。
Claude Codeで毎日コード書いてる身からすると、セキュリティ対策の自動化は本当に助かる。
理由はシンプルで、一人で開発していると個人情報の保護まで手が回らないことが多いからだ。
僕はThreadPostというSaaSを作っているけど、ユーザーのデータを扱う以上、PII保護は避けて通れない。
つまずきポイント
初心者がLLM SDK開発でハマりやすい罠を3つ紹介する。
事前に知っておけば、無駄な時間を溶かさずに済む。
- 環境変数の読み込み忘れ
.envファイルを作ったのに、プログラムの冒頭で読み込む処理を書き忘れるミスが非常に多い。
APIキーが見つからないというエラーが出たら、まずは読み込み処理の呼び出しを確認する。
コードの一番上に書く癖をつけるのがおすすめだ。
- トークン数の計算ミス
マルチターン会話を実装すると、気づかないうちに送信データが巨大化する。
1回のやり取りのコストは安くても、履歴が蓄積すると急激に課金額が跳ね上がる。
テスト中はこまめに利用料金のダッシュボードを確認する。
- 役割の指定間違い
AIにメッセージを送る際、ユーザーとAIの役割を交互に設定する必要がある。
ユーザーの発言が連続したり、役割の名前を間違えたりするとエラーになる。
エラーが出たら、送信するメッセージのリスト構造を見直す。
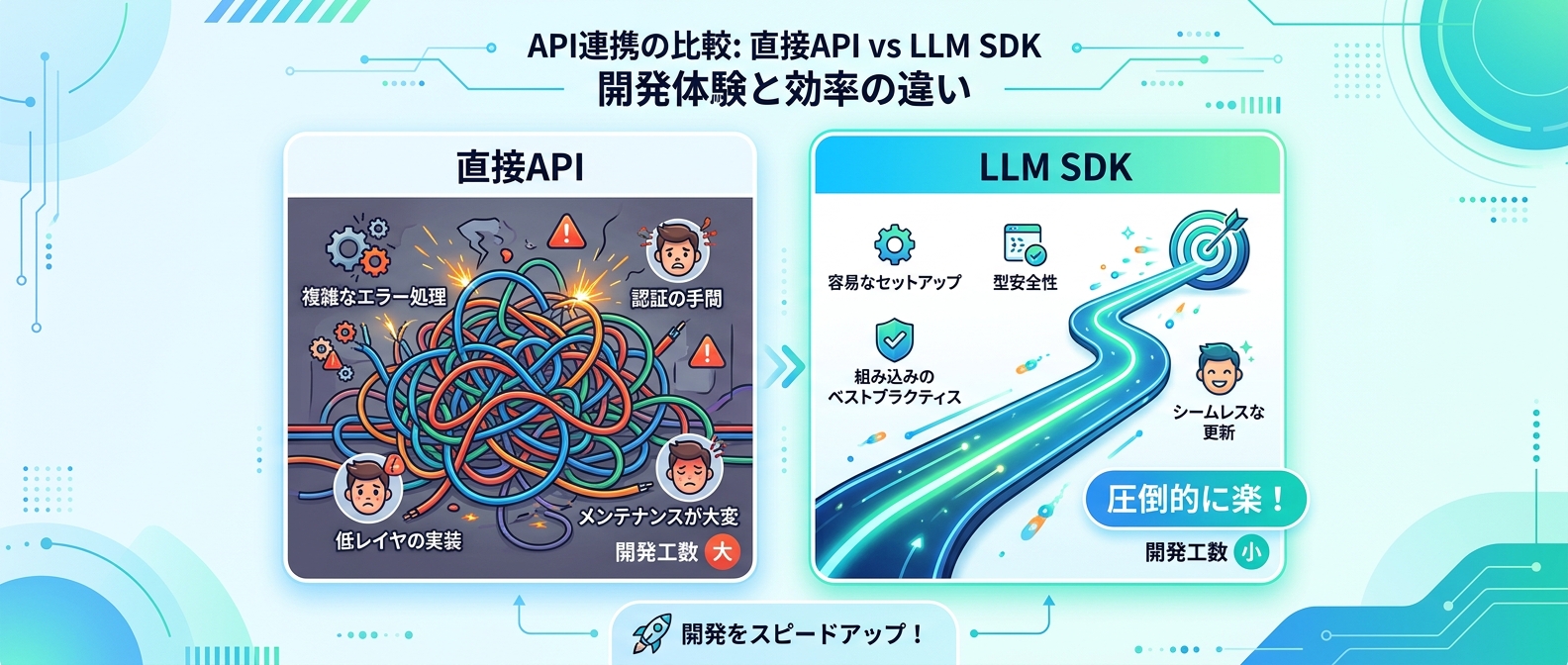
直接APIとSDKの比較表
開発手法を選ぶ際の参考として、直接APIを叩く場合とSDKを使う場合の違いをまとめた。
結論から言うと、SDKを使うのが圧倒的に楽だ。
| 比較項目 | 直接API通信(HTTPリクエスト) | LLM SDK利用 | おすすめ度 |
| :--- | :--- | :--- | :--- |
| 実装の手間 | 認証やエラー処理を全て自作 | 数行のコードで完了 | SDKの圧勝 |
| エラー対応 | 自分でリトライ処理を書く必要あり | 自動で再試行してくれる | SDKの圧勝 |
| 開発スピード | 調べる時間が長く遅い | 爆速でプロトタイプが動く | SDKの圧勝 |
| セキュリティ | 漏洩リスクの管理が複雑 | 環境変数との連携が簡単 | SDKの圧勝 |
FAQ
初心者が疑問に思いがちなポイントをまとめた。
Q1: LLM SDKと直接APIを叩くのは何が違う?
直接APIを叩く場合、通信の確立や認証ヘッダーの付与などをすべて自分で実装する必要がある。
LLM SDKを利用すると、これらの複雑な処理をライブラリが肩代わりしてくれる。
数行のシンプルなコードを書くだけで簡単にAIモデルを呼び出せる。
開発スピードが上がりバグも減るため、初心者はまず公式のSDKを使うのが圧倒的に効率的だ。
Q2: APIキーを誤ってGitHubに公開してしまったらどうする?
数分以内に悪意のあるボットに検知され、不正利用による高額請求が発生する危険がある。
気づいた時点ですぐにプロバイダーの管理画面にログインし、該当のAPIキーを無効化または削除する対応が必要だ。
その後、新しいAPIキーを発行し、必ず環境変数を使って安全に管理するよう修正する。
絶対に放置してはいけない。
Q3: マルチターン会話を実装するとコストが高くなるのはなぜ?
LLM自体は過去の会話を記憶する機能を持っていないからだ。
文脈を踏まえた自然な回答を得るには、過去のユーザーの発言とAIの回答をすべて毎回送信する必要がある。
会話が進むほど送信するテキスト量が雪だるま式に増えていく。
API課金は送受信したデータ量に比例するため、結果として通信コストが高くなる仕組みだ。
Q4: ユーザーが入力した個人情報をLLMに送るのは危険?
セキュリティやプライバシーの観点から非常に危険だ。
入力したプロンプトはプロバイダーのサーバーに送信され、ログとして保存される可能性がある。
氏名やマイナンバーなどの機密情報が含まれる場合、重大な情報漏洩インシデントに繋がる。
実運用では専用のミドルウェアを使い、送信前に個人情報を自動でマスキングする対策が必須だ。
Q5: 返答の最大長さを設定しないとどうなる?
AIが不必要に長い文章を生成し続けたり、ループに陥ったりする危険がある。
その結果、想定外の高額な課金が発生するコスト爆発のリスクが高まる。
開発時やテスト時は特に、用途に合わせて必要十分な長さに制限しておくことが重要だ。
これを設定するだけで、安全かつ経済的にAPIを利用し続けられる。
まとめ
今回は、Pythonを使ってLLM SDK開発を始めるための5つのステップを解説した。
使う側から作る側に回ることで、AIの仕組みや裏側の苦労がよくわかるようになるはずだ。
まずは環境を整えて、短いテキストを生成するところから試す。
自分で書いたコードでAIが動く瞬間は、何度経験しても感動する。
あなたが作ってみたいAIアプリのアイデアや、開発でつまずいたポイントがあれば、スレッドに書き込むといい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
