
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIエージェントの「次のフェーズ」が始まっている
AIエージェントが「常駐する」フェーズに入った。
チャットに質問して答えを待つ、じゃない。バックグラウンドで24時間動き続け、スケジュールやイベントをトリガーに自律的にコードを書き、PRを出し、Slackに報告する。そういうエージェントが、今まさに普通のツールとして手の届く場所に来ている。
ただし、落とし穴がある。インフラが整った先に、もっとデカい壁がある。エージェント同士が会話し始めた瞬間に、自然言語の曖昧さが牙を剥く。

何が起きているか — 常駐型エージェントの「民主化」と「次の問題」
大きく3つの動きが同時に起きている。
1つ目。常駐型エージェントを自作するインフラが整った。
Anthropicが提供するエージェント実行フレームワーク「Claude-Agent-SDK」を使えば、プログラム上でClaudeエージェントを定義し、バックグラウンドプロセスとして常駐させられる。Unixソケットサーバーとして動かし、24時間いつでも指示を受け付ける構成が作れる。
注目点は、Claude Codeと同じツールセット(Read / Write / Bash等)を使える点だ。つまり、日常的に書いている「CLAUDE.md」や「settings.json」をそのままエージェントのコンテキストとして流用できる。Claude Codeで積み上げたプロジェクト固有のルールが、自動化ワークフローの基盤として直接機能する。
セッション管理、CRONによる定期実行、Discord・Slack連携、REST API(FastAPI + uvicorn)まで実装できる。毎朝9時に「今日のAIニュースを整理して」と自動送信する、みたいな運用がローカルで動く。
2つ目。SaaSレベルの常駐エージェント基盤も登場した。
CursorがAutomationsという機能をリリースした。スケジュールか、Slack / Linear / GitHub / PagerDuty / Webhookからのイベントをトリガーに、クラウドサンドボックス上でエージェントが起動する。設定したMCPとモデルで指示を実行し、過去の実行から学習するメモリ機能まである。インフラ管理ゼロで常駐エージェントが持てる。
3つ目。そして、次の壁が見えてきた。
GitHubのエンジニアリングチームが、マルチエージェントシステムの失敗パターンを公開した。コードベースのメンテナンス、依存関係の更新、コード品質チェック、Issue・PRのトリアージ。これらのシナリオで、エージェントが複数になった瞬間に何が起きるか。
「あるエージェントが閉じたIssueを、別のエージェントが再度開く」「下流のチェックを知らずに変更をプッシュする」。こういう失敗が、ログを見ても原因がわからない形で起きる。
原因は自然言語の曖昧さだ。フィールド名が変わる、データ型が合わない、フォーマットがずれる。エージェント間の通信を自然言語や不定形JSONに頼った瞬間、システム全体が「なんとなく動いてるけど信頼できない」状態になる。
しんたろー:
これ、読んだとき「あ、分散システムの話だ」と思った。
エージェントが複数になった瞬間に、マイクロサービス設計と同じ問題が出てくる。インターフェース契約を明示しないと、チーム開発でAPIが崩壊するのと同じことが起きる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
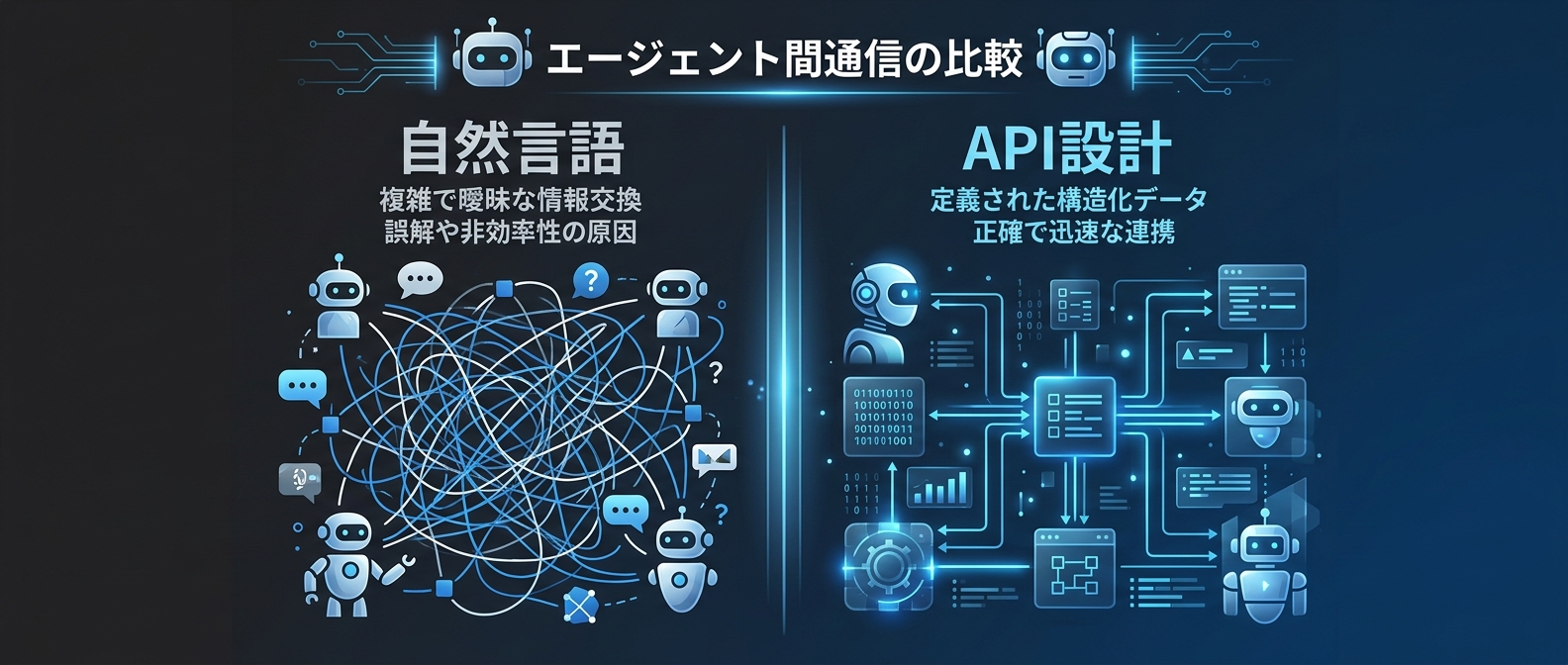
「プロンプトの上手さ」より「スキーマ設計の正確さ」が求められる理由
ここが本質だ。
AIエージェントの活用スキルというと、「プロンプトをうまく書く」「文脈をうまく渡す」という話になりがちだ。それは単一エージェントの話。エージェントが複数になり、自動化ワークフローに組み込まれた瞬間に、求められるスキルが変わる。
必要なのは「分散システム的思考」だ。
具体的に何が変わるか。
エージェントAが「調査結果をまとめて次のエージェントに渡す」とき、自然言語で「〜という結果でした」と渡すのか、型定義されたスキーマで渡すのかで、システムの信頼性が桁違いに変わる。
JSON SchemaやPydanticモデルで出力形式を事前定義する。「status」「files_changed」「error_code」といったフィールドを型付きで強制する。後続のエージェントはパースエラーを起こさず、スキーマ違反は「コントラクト違反」として即座に検知できる。
デバッグの質が変わる。「ログを見て推測する」から「このペイロードがスキーマXに違反した」という明確なエラーになる。
GitHubのチームはこれを「typed schemas are table stakes(型付きスキーマは最低条件)」と表現している。これがなければ、他の何も機能しない、という言い方だ。
Claude-Agent-SDKとの接続で考えると、こういうことになる。
Claude Codeの「CLAUDE.md」で「出力は必ずこのJSON形式で返せ」というルールを定義しておく。それを「setting_sources=["user", "project"]」でエージェントに読み込ませる。エージェントが複数になっても、全員が同じ出力契約に従う。
これはプロンプトエンジニアリングではなく、APIの仕様書を書く作業だ。
単発のプロンプトを磨くのか、エージェント間の通信プロトコルを設計するのか。後者のほうが、自動化ワークフローで圧倒的に価値を持つ。
もう一つ大きな変化がある。
常駐型エージェントは「状態」を持つ。セッション管理、会話履歴(.claude/projects/配下のJSONLファイル)、CRONで蓄積されるコンテキスト。これは単発のAPIコールとは根本的に違う設計が必要になる。
Cursor Automationsのメモリ機能(「過去の実行から学習する」)も同じ方向だ。エージェントが「前回はこうだったから今回はこうする」という判断をし始める。これはステートフルなシステムを管理するということであり、データの整合性をどう担保するかという問題が生まれる。
Claude Codeで毎日コードを書いてる身からすると、CLAUDE.mdがそのままエージェントの契約書になるという発想がすごくしっくりくる。
「このプロジェクトではこういうルールで動け」というのを、人間向けにも書いてたし、エージェント向けにも同じファイルが使えるなら、管理コストが全然違う。
うちのThreadPost開発の構成でも、エージェントを複数走らせるとしたら、まずスキーマ定義から入らないとカオスになるのが目に見える。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実際の開発にどう影響するか
今すぐ変えられることと、知っておくべきことを整理する。
① CLAUDE.mdをエージェントの仕様書として書き直す価値がある
今まで「自分(人間)が使うための設定ファイル」として書いていたCLAUDE.mdを、「エージェントへの契約書」として見直す。出力フォーマット、禁止操作、エラー時の振る舞い。これを明示的に書いておくと、Claude-Agent-SDKで常駐エージェントを動かすときにそのまま使える。
② エージェント間の通信設計は「API設計」として考える
エージェントAからエージェントBへデータを渡すとき、自然言語に頼らない。期待するデータ構造を事前定義し、スキーマ違反を検知する仕組みを入れる。これは「プロンプトを工夫する」問題ではなく「インターフェース設計」の問題だ。
③ 自作 vs SaaS(Cursor Automations)の選択基準
- 閉じた環境・ローカル統合・コスト重視 → Claude-Agent-SDKで自作
- インフラ管理ゼロ・GitHub/Slack連携を即開始・クラウドサンドボックス必須 → Cursor Automations
どちらが正解ではなく、環境と用途で決まる。
④ 本番投入の順序
Claude-Agent-SDKは現時点でv0.x系だ。基本機能(非同期処理、Discord/Slack連携、CRON実行)は動く。ただし、エッジケースのエラーハンドリングは自分で実装する必要がある。
最初から本番のクリティカルなフローに入れるのはリスクが高い。社内の開発補助、定型レポートの自動生成、Issue分類の補助など、影響範囲が限定された領域から始めるのが現実的だ。
⑤ マルチエージェントで最初に設計すること
- 各エージェントの「入力スキーマ」と「出力スキーマ」を先に定義する
- スキーマ違反をコントラクト違反として扱う(リトライ・修復・エスカレーション)
- 共有状態(どのエージェントが何のIssueを担当しているか等)の管理方法を決める
- 実行順序の依存関係を明示する
GitHubのチームが「エージェントが閉じたIssueを別のエージェントが開き直す」という失敗例を出してたの、読んだときに笑えなかった。
自分でマルチエージェント組んだら絶対やらかすやつだ。
スキーマ設計を先にやれ、というのは、APIの仕様書を先に書けという話と全く同じで、それを知ってるはずの開発者がエージェントになると忘れるの、なんか面白い。
よくある質問
Q1. 常駐型AIエージェントを自作するのとCursor Automationsを使うのはどちらが良いですか?
用途と環境に大きく依存する。社内の閉じたシステムや独自のローカル環境に深く統合したい場合、あるいはコストを抑えて柔軟にカスタマイズしたい場合は、Claude-Agent-SDK等を用いた自作が適している。自前のUnixソケットサーバーで動かし、既存のClaude Code設定(CLAUDE.md / settings.json)をそのまま流用できる点は大きな強みだ。一方、インフラ管理を一切意識せず、GitHub / Slack / Linear / PagerDuty連携を即座に始めたい場合や、クラウドサンドボックスでの安全な実行環境を求める場合は、Cursor Automationsが圧倒的に手軽で強力な選択肢になる。最初の判断基準は「ローカルに閉じていたいか、クラウドで外部連携を即開始したいか」の一点だ。
Q2. マルチエージェントシステムで「型付きスキーマ」を使うとは具体的にどういうことですか?
エージェントに対して「結果をまとめて教えて」と自然言語で出力させるのではなく、JSON SchemaやPydanticモデルなどを事前に定義し、必ずそのデータ構造で出力させるよう強制することだ。例えば「status」「files_changed」「error_code」といったフィールドを型付きで定義しておく。これにより、後続のエージェントやシステムがパースエラーを起こさず、確実なデータ連携が可能になる。スキーマ違反が起きたとき、デバッグが「ログを見て推測する」から「このペイロードがスキーマXに違反した」という明確なエラーになる。自然言語の曖昧さを排除し、APIのレスポンスと同じように扱うことが安定稼働につながる。GitHubのエンジニアリングチームは「型付きスキーマは最低条件であり、これがなければ他の何も機能しない」と断言している。
Q3. Claude-Agent-SDKは本番環境の業務で実用レベルですか?
現時点ではv0.x系であり、発展途上の段階だ。基本的な非同期処理、外部ツール連携(Discord / Slack)、CRON実行などは十分に機能する。ただし、予期せぬエラーのハンドリングやエッジケースへの対応は開発者自身で堅牢に実装する必要がある。エンタープライズのクリティカルな本番業務にいきなり投入するよりは、まずは社内の開発補助や定型タスクの自動化など、影響範囲の限定された領域から導入を始めるのが現実的だ。なお、AWS / Azure / GCPとの連携も可能なため、エンタープライズ環境への将来的な統合を見据えた設計はしやすい。本番化のタイミングは、エラーハンドリングの実装が完了し、影響範囲の小さいユースケースで十分に動作確認できてからと考えておくのが無難だ。
まとめ
常駐型エージェントのインフラは整った。次の問題はプロンプトではなくスキーマだ。
エージェントが1つなら、うまいプロンプトで乗り切れる。複数になった瞬間に、分散システムの設計問題になる。型付きスキーマ、インターフェース契約、状態管理。これは新しいスキルではなく、API設計でずっとやってきたことだ。
Claude Codeで毎日コードを書いてる人間にとって、CLAUDE.mdが常駐エージェントの契約書になるというのは、地味だけどかなりデカい話だと思っている。
常駐型エージェントの構築手法や、失敗しないマルチエージェントのスキーマ設計について、あなたの知見や試行錯誤をSNSで発信してみませんか?

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
