
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
思考プロセスが課金対象に変わった日
AIが「考える時間」にコストがかかるようになった。
100万トークンの巨大なコンテキスト。2.5ドルの入力コスト。272Kトークンの見えない壁。
推論のブラックボックスが開き、開発者が手綱を握るフェーズに入った。
思考の深さを制御し、APIのレスポンス時間とコストを天秤にかけるゲームの始まりだ。
ただAPIを叩けばよかった時代は終わった。
AIの「脳味噌の使い方」を僕らが設計する番だ。
思考リソースの制御権が開発者に移行
AIの推論プロセスは、これまで完全にブラックボックスだった。
プロンプトを投げれば、モデルが勝手に考えてテキストを返してくる。
今は違う。
Claudeの「Extended Thinking」が登場し、AIに対して「どれくらい深く考えるか」を明示的に指定できるようになった。
考える時間を長くすれば、複雑な論理パズルも解けるようになる。
コードのバグ修正やアーキテクチャ設計で、その威力を発揮する。
だが、その分のトークン消費とレイテンシ増大という代償を払うことになる。
思考プロセスそのものが出力トークンとして課金される仕組みだ。
Claudeは「budget tokens」というパラメータで推論の上限を厳密に定義する。
1万トークンまで考えていい、と指示すれば、その範囲内で思考を巡らせる。
レスポンスは「thinking」ブロックと「text」ブロックの2つに分割されて返ってくる。
AIがどうやってその結論に達したのか、ステップバイステップで確認できる。
GPT系モデルも「effort」パラメータで推論の深さを制御する設計を採用している。
「low」「medium」「high」の3段階から選ぶだけだ。
コンテキスト長には罠がある。
- 127Kトークン以内: 最適なパフォーマンスと標準料金
- 272Kトークンまで: 精度97%を維持しつつ標準料金
- 272Kトークン超過: 精度が激落ちし、セッション全体の料金が倍増
272Kトークンを超えるとセッション全体の料金が倍増する。
無駄に長いコンテキストを投げつけるのは、お金をドブに捨てるようなものだ。
どちらのモデルも「考えるほど賢くなるが、遅くて高い」という物理法則は同じだ。
推論リソースの最適化が、今後のAIアプリケーション設計の核心になる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
トークン制御か、抽象化か。両社の思想の違い
AnthropicとOpenAIで、API設計の思想が完全に分岐した。
Anthropicはトークン数という絶対的な数値で開発者にコントロールを求める。
「budget tokens」で最大思考トークン数を指定する。
ここで注意すべきは「max tokens」との関係だ。
「max tokens」は思考と最終回答の合計上限を意味する。
「budget tokens」は思考だけの上限だ。
当然、「budget tokens」は「max tokens」より小さく設定しなければならない。
思考だけで上限を使い切ってしまうと、肝心の最終回答を出力する余裕がなくなる。
1万トークンまで考えていいと設定しても、毎回使い切るわけではない。
簡単な質問なら数百トークンで切り上げる。
OpenAIは抽象的な「effort」でモデル側に裁量を残す。
開発者は「low」「medium」「high」を指定するだけだ。
手軽に導入できる反面、裏でどれだけトークンを消費するかはモデル任せになる。
タスクの内容によって消費トークンが大きくブレる可能性がある。
開発者として直面するのは、ストリーミング処理の複雑化だ。
ClaudeのExtended Thinkingを有効にすると、イベントタイプが2種類飛んでくる。
「thinking delta」と「text delta」だ。
パース処理を間違えると大惨事になる。
生の推論過程がユーザーの画面に垂れ流しになるリスクがある。
これまでの単一テキストストリームを前提としたコードは、すべて書き直しだ。
ストリーミング処理の実装手順は以下のようになる。
- イベントタイプを監視する
- 「thinking delta」なら思考中UIコンポーネントに流し込む
- 「text delta」ならメインのチャット画面に表示する
- イベントの切り替わりでUIのアニメーションを制御する
しんたろー:
イベントが2つに分かれるの、地味に実装の手間が増える気がする。
パーサーの分岐処理と、UI側で思考中アニメーションと最終回答を別々にレンダリングする設計、どう整理するか考え中。
セキュリティ面でも大きな変化があった。
Claudeの思考ブロックには「signature」という暗号トークンが付与される。
マルチターン会話で前回の思考プロセスを再送する際、改ざんがないか検証するためだ。
テキストを1文字でも書き換えると、署名の検証が失敗する。
Anthropicのサーバー側で生成される強固な暗号だ。
開発者が悪意を持って推論を書き換え、モデルの判断を誘導するのを防ぐ仕組みだ。
さらに「redacted thinking」という概念も登場した。
安全機構に引っかかると、思考プロセスの一部が暗号化された墨消し状態で返ってくる。
個人情報への言及や、安全ガイドラインの内部処理が含まれた場合にトリガーされる。
これはエラーではない。
最終的な回答となるテキストブロックは通常通り生成される。
そのまま次のリクエストの「messages」に含めて送り返せばいい。
人間には読めないBase64エンコードされたデータだ。
だが、モデルは暗号化された思考プロセスを覚えたまま次のターンに進める。
コンテキストの連続性は完全に保たれる。
テスト環境で意図的にこの挙動を確認するためのマジックストリングも用意されている。
特定の文字列を入力に含めると、強制的に墨消し思考を返させることができる。
エラーハンドリングのテストには必須の機能だ。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
プロンプト改善をサボるための課金ではない
思考リソースの制御がアプリケーション設計の勝敗を分ける。
すべてのリクエストに最大推論を適用するのは破産への道だ。
タスクの難易度を事前判定する仕組みが求められる。
推論パラメータを動的にルーティングするミドルウェア層が必須になる。
入力されたテキストを解析し、適切なモデルと推論設定を選択する。
Claude Codeを使っていると、このメリハリの重要性がよくわかる。
複雑なアーキテクチャ設計には「model opus」や「model sonnet」で長考させる。
プロジェクト固有のルールは「CLAUDE.md」に記述してコンテキストを保つ。
単純なリファクタリングは「model haiku」で瞬殺させる。
チェックポイント機能で過去の会話を再開し、無駄なコンテキスト送信を省く。
モデルの使い分けと思考リソースの割り当ては、本質的に同じアプローチだ。
適材適所で推論コストを最適化する。
Claude Codeのコマンドでモデルを切り替える感覚に近い。
難しいバグ修正のときだけOpusを召喚するみたいな運用を、APIの裏側でも自動化しないとコストが爆発するな、と思っている。
Extended Thinkingは銀の弾丸ではない。
雑なプロンプトのまま思考を延長しても、AIが長々と迷走するだけだ。
思考トークンは出力トークンとしてしっかり課金される。
無駄な迷走にお金を払うことになる。
プロンプトの構造化。明確な指示。数個の具体例。
これらを試し尽くした上で、それでも足りないときに初めてExtended Thinkingの出番が来る。
温度設定にも注意が必要だ。
Extended Thinking有効時は「temperature」が1.0に固定される。
思考プロセスには確率分布全体が必要なため、決定論的な出力は設計上サポートされていない。
ゼロを指定しても強制的に上書きされる。
常に一定の揺らぎを持った出力になることを前提に設計しなければならない。
厳密なフォーマット指定が必要なタスクには向かない場合がある。
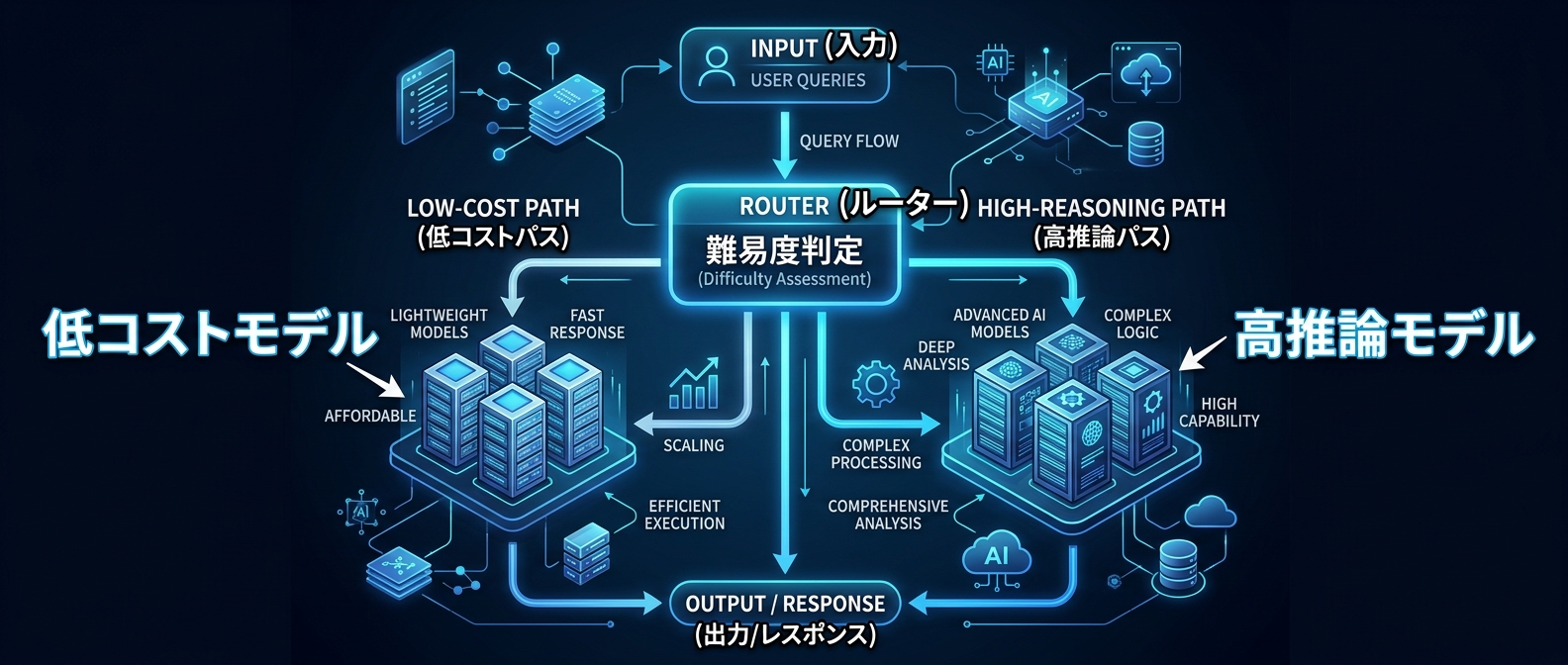
動的ルーティングがAIアプリの標準になる
常に全力で考えさせる設計はもう古い。
ユーザーの入力からタスクの複雑さを判定する。
単純な質問には低コストモデルを当てる。
複雑な推論が必要なときだけ、Extended Thinkingや「high effort」を解放する。
この動的ルーティングが、次世代のAIアプリの標準アーキテクチャになる。
動的ルーティングの実装ステップは以下の通りだ。
- ユーザーの入力を受け取る
- 前段の軽量モデルでタスクの難易度を分類する
- 難易度に応じて「effort」や「budget tokens」を決定する
- 最適化されたパラメータでメインモデルにリクエストを投げる
コードの解析なら「high」。日常的な会話なら「low」。
リクエストごとに最適なリソースを割り当てる。
思考のログを保存する際の仕様変更も押さえておく。
Claudeの場合、思考テキストだけでなく署名もセットで保存しないと再送できない。
データベースのスキーマ変更が必要になるケースも多いはずだ。
署名なしで再送しようとすると、APIから無情なエラーが返ってくる。
思考プロセスをデータベースに永続化するなら、署名用のカラムは必須だ。
ログ基盤の設計から見直す時期に来ている。
ThreadPostのデータベース設計、思考ログ用のカラムだけじゃなくて署名用の別カラムも要るのか、と気づいた。
マルチターン会話を実装するなら早めに対応しておきたい。
推論コストのROIをどう最大化するか。
トークンを節約しながら、必要なときだけAIの脳味噌をフル回転させる。
賢く怠けるためのシステム設計が試されている。
思考プロセスをブラックボックスから取り出し、開発者の武器に変える。
開発者が知っておくべき3つの疑問
ClaudeのExtended Thinkingを有効にすると、APIのレスポンス処理はどう変わりますか?
レスポンスが「thinking」ブロックと「text」ブロックの2つに分かれて返却されます。
ストリーミング処理を行う場合は、イベントタイプを監視する必要があります。
「thinking delta」と「text delta」をそれぞれ別のUIや変数に振り分ける実装が必須です。
また、マルチターン会話では「thinking」ブロックの署名も保持して送り返す必要があります。
budget tokensとmax tokensは、実務でどう設定すればいいですか?
「max tokens」は思考と最終回答の合計上限、「budget tokens」は思考だけの上限です。
「budget tokens」が「max tokens」を超えると、最終回答を出力するトークンが残らなくなります。
コスト上限を厳格に管理したいシステムでは、タスクの難易度に応じて「budget tokens」を動的に変えるのが現実的な設計です。
「budget tokens」は上限であり、モデルが毎回使い切るわけではないため、余裕を持たせた設定でも無駄打ちにはなりません。
Claudeのレスポンスに「redacted thinking」が含まれていた場合、エラーとして処理すべきですか?
いいえ、エラーではありません。
これは安全機構が働き、思考プロセスの一部が暗号化されただけです。
最終的な回答となる「text」ブロックは正常に生成されています。
開発者は中身をパースせず、そのまま次のリクエストの「messages」に含めて送り返してください。
これによりモデルのコンテキストを維持できます。
思考を制御し、コストを最適化する
推論プロセスが可視化され、コストと直結する時代になった。
推論コストを最適化しながらAIと協業する次世代の開発スタイルが求められている。
ThreadPostの開発プロセスを通じて、この新しいアーキテクチャを実践していく。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
