
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
1Mトークンが「標準価格」になった日
100万トークンが追加料金なしで使える。
これが何を意味するか。
平均的なコードファイルを1,000〜2,000トークンとして計算すると、500〜1,000ファイル分のコードを丸ごとコンテキストに突っ込める。
普通サイズのSaaSプロダクトなら、リポジトリ全体を一度に読ませることも現実的になる。
今まではこれに最大100%のサーチャージがかかっていた。
つまり倍の値段。
開発者は「どこを削るか」を考えながらコンテキストを設計するしかなかった。
その制約がなくなった。
Claude 4.6で何が変わったのか
Sonnet 4.6が正式リリースされた。
価格はSonnet 4.5と同じ。
入力$3・出力$15(100万トークンあたり)。
今回の最大のポイントは価格体系の変更だ。
これまで200,000トークンを超えるリクエストには最大100%のサーチャージが発生していた。
9,000トークンのリクエストと900,000トークンのリクエストでは、同じモデルを使っているのにコストが倍近く違う状況だった。
それが撤廃された。
9,000トークンでも900,000トークンでも同一価格。
Opus 4.6も同様に1Mトークンの標準価格化が適用されている。
Opusは入力$5・出力$25。
機能面での変化も大きい。
- コーディング性能: Anthropicの公式発表によると、早期アクセスユーザーがSonnet 4.5より70%の確率でSonnet 4.6を選好。2025年11月リリースのOpus 4.5より好まれるケースもあった。
- Computer Use: OSWorldベンチマークで着実に進歩。複雑なスプレッドシート操作や複数タブをまたぐフォーム入力で人間レベルの能力を示し始めた。
- メディア制限: 1リクエストあたりの画像・PDFページ上限が100から600に拡大。
- 対応プラットフォーム: Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundryで新価格が適用。
さらに同時期に、DeepSeekがDeepSeek-R1というオープンソースの推論モデルをリリースした。
従来世代比で圧倒的な低コストと高い推論精度を両立したモデルだ。
2つのニュースが重なった。
これは偶然じゃない。
しんたろー:
「サーチャージ撤廃」って地味に聞こえるけど、これ開発者にとってはめちゃくちゃデカい。
今まで「長いコンテキスト使いたいけどコストが怖い」でチューニングしてたやつが全部不要になる。
設計の前提が変わるやつだ。でも相変わらずプロンプトのtypoでエラー吐かせて課金されるのは変わらない。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
コスト制約で妥協していた設計の見直し
開発者がコンテキスト長を制限していた理由は、ほぼコストだった。
技術的な制限ではなく、経済的な制限。
これが外れると何が起きるか。
まずリポジトリ全体読み込みが現実的になる。
今まで「関連ファイルだけ渡す」「要約してから渡す」という前処理が必要だった。
それをやるためのコードを書いて、メンテして、バグを踏んでいた。
その手間が丸ごと消える。
次にログ分析の設計が変わる。
本番環境のログを大量に突っ込んでAIに分析させるシナリオが、コストを気にせず実行できる。
エラーの文脈を追うためにログを手動でフィルタリングする作業が減る。
そしてエージェント開発のループが長くなる。
エージェントが複数ステップのタスクを実行するとき、過去の実行履歴をどこまでコンテキストに含めるかは常にトレードオフだった。
長くすれば精度が上がるがコストが増える。
このトレードオフの天秤が、大きく「長く持てる」方向に傾いた。
ClaudeのアプローチとDeepSeekのアプローチは、同じ問題を別の角度から解いている。
Claudeは「長いコンテキストを安く使えるようにした」。
DeepSeek-R1は「モデルがどれだけ深く考えるかを推論プロセスで最適化した」。
簡単なタスクには低レイテンシで即答させ、複雑な論理推論が必要なタスクには計算リソースを多く割り当てる。
全てのタスクに同じ深さの推論をかけるのは明らかに非効率だ。
「ファイル名を変える」タスクと「バグの根本原因を特定する」タスクに同じリソースを使う必要はない。
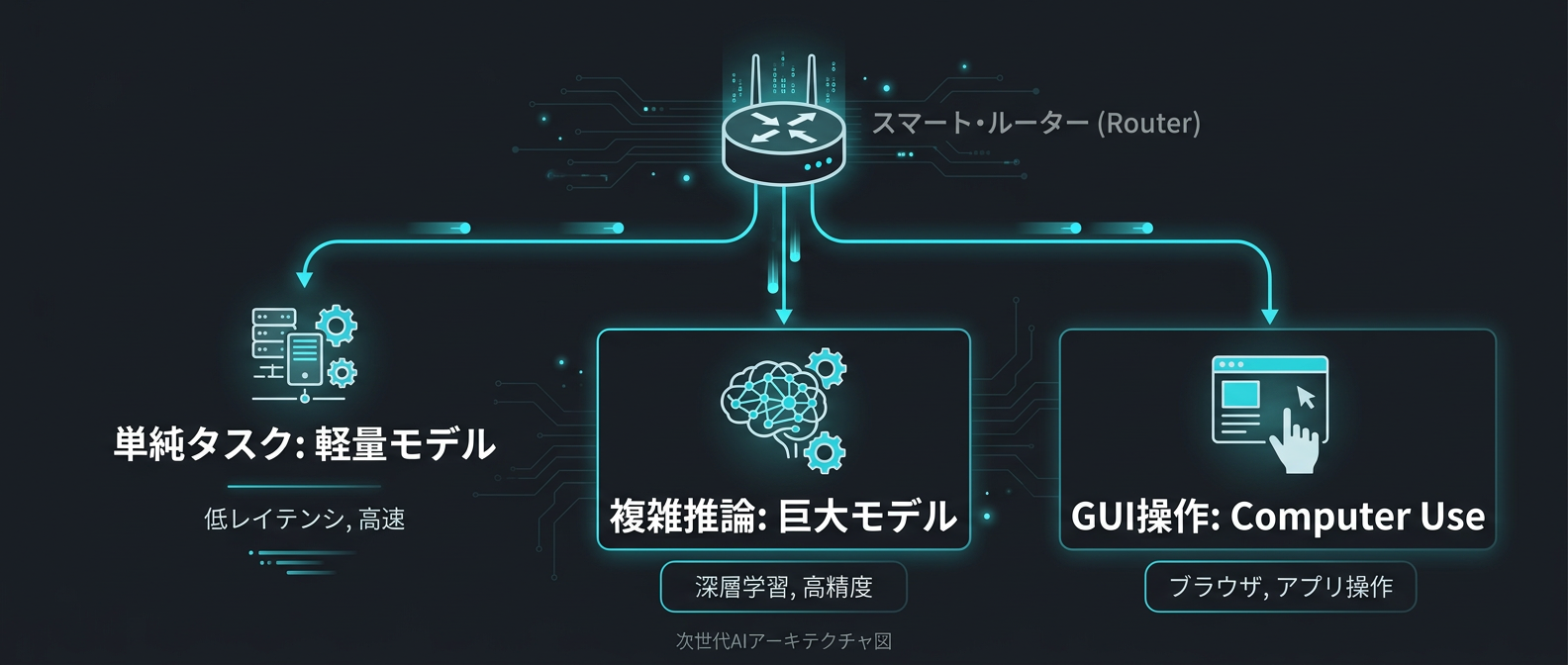
この考え方はモデルのルーティング設計に直結する。
プロプライエタリモデルとオープンソースモデルの役割が、はっきり分かれてきた。
Claude(プロプライエタリ): Computer Useに代表される「エンドユーザー環境の直接的な自動化」に注力。
GUIを持つレガシーシステムや、APIが存在しない既存ソフトウェアの操作を、人間と同じ方法で行う。
DeepSeek-R1(オープンソース): マルチエージェントの「推論エンジン」としてのシステム組み込みに特化。
自分でホストできる・ファインチューニングできる・推論の深さを制御できる。
どちらをどこに使うかの設計判断になる。
Claude CodeでThreadPostのコードベースを触ってると、コンテキスト切れが地味にストレスだった。
「あ、またここで切れるな」って予測しながらファイルを分割して渡す作業、正直めんどくさい。
1Mが標準になったら、その認知負荷が下がるのはかなりありがたい。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務での変更点
コンテキスト節約のための前処理コードを棚卸しする。
「長いコンテキストを送らないために」書いたコードが、あなたのリポジトリにあるはずだ。
要約ロジック、チャンキング処理、関連ファイルフィルタリング。
これらが本当に必要かどうか、改めて評価する。
ただし注意点がある。
コンテキストが長くなれば精度が下がる問題は未解決だ。
1Mトークンが安く使えるようになっても、100万トークン全部を精度よく処理できるかは別の話。
「コンテキストが長くなるほど、モデルが中間部分の情報を見落としやすくなる」という問題(いわゆる「中間の迷子」問題)は依然として存在する。
使い方の現実的な指針:
- 重要な情報は冒頭か末尾に置く。中間に埋めない。
- 全部突っ込むより構造化して渡す方が精度が高いケースは多い。
- 長文脈が有効なのは「全体把握」が必要なタスク。コード全体の依存関係分析、大量ログの異常検知、長いドキュメントの矛盾チェックなど。
マルチエージェントシステムを設計するとき、タスクの複雑さに応じてモデルを切り替えるルーティングは今後の標準的なアプローチになる。
具体的には:
- 単純な分類・抽出タスク → 軽量モデル
- コード生成・デバッグ → Sonnet 4.6クラス
- アーキテクチャ設計・複雑な推論 → Opus 4.6クラスやDeepSeek-R1
- GUIを持つ既存システムの操作 → Computer Use対応モデル
全部同じモデルに投げるのは、コストと速度の両方で非効率だ。
Sonnet 4.6のComputer Useは確実に進歩している。
OSWorldベンチマークでの改善は16ヶ月で継続的に積み上がっている。
ただしAnthropic自身が「最も熟練した人間にはまだ遅れをとっている」と認めている。
実運用での推奨レベル:
- 今すぐ使える: 人間の監督下でのアシスタント的利用。エラーが起きても影響が少ない社内業務。
- 慎重に: 完全自律的な無人運用。プロンプトインジェクション攻撃のリスクは下がったが、ゼロではない。
- まだ早い: ミッションクリティカルなシステムへの完全無人アクセス。
プロンプトインジェクション耐性が向上した。
Computer Useを本番に入れる上での最大のセキュリティ懸念の一つだった。
Computer Useは「面白いデモ」から「使えるツール」に近づいてきた感じがする。
ただ「最も熟練した人間にはまだ遅れをとっている」という言い方、Anthropicがこういう書き方をするのは信頼できる理由の一つだ。
よくある質問
Q1. Claude 4.6の1MトークンコンテキストはAPI経由でどのように課金されますか?
以前は200,000トークンを超えるリクエストに対して最大100%のサーチャージが発生していた。
同じモデルを使っているのに長いリクエストは倍近いコストになるという構造だった。
今回のアップデートでこれが完全に撤廃された。
Sonnet 4.6の場合、入力が9,000トークンでも900,000トークンでも、100万トークンあたり入力$3・出力$15の標準価格が適用される。
Amazon BedrockやGoogle Cloud Vertex AI、Microsoft Foundryなどの主要クラウドプロバイダーでもこの新価格が適用される(メディア制限の拡張はBedrock除く)。
長大なログやコードベースを読み込ませるエージェント開発のコストが大幅に下がる。
月次のAPI費用試算をしている人は、長文脈リクエストの比率が高いほど恩恵が大きい。
Q2. 推論モデルの台頭はエージェント開発にどう影響しますか?
API経由でモデルがタスクに対してどれだけ深く考えるかを最適化できる。
従来のモデルでは推論の深さが固定されているか、複雑なプロンプトエンジニアリングに頼る必要があった。
DeepSeek-R1のような推論モデルでは、複雑な論理的推論が必要なタスクには計算リソースを多く割り当てて精度を高めるというプロセスをモデル自身が行う。
マルチエージェントシステム全体のコストと応答速度の最適化が容易になる。
エンタープライズ向けの組み込み用途で特に強みになる。
Q3. ClaudeのComputer Use機能は実運用レベルに達していますか?
「使える場面がある」が答えだ。
Sonnet 4.6はOSWorldベンチマークで着実な進歩を見せている。
複雑なスプレッドシート操作や複数タブをまたぐフォーム入力などで人間レベルの能力を示し始めている。
プロンプトインジェクション攻撃への耐性も大幅に向上した。
ただし、Anthropic自身が「まだ最も熟練した人間には遅れをとっている」と認めている。
完全に自律的な無人運用にはまだリスクが伴う。
現段階での現実的な用途:
- 人間の監督下でのアシスタント的利用
- エラーが発生しても影響が少ない社内業務の自動化
- APIが存在しないレガシーシステムとのインテグレーション
ミッションクリティカルな本番環境への完全無人アクセスは、もう少し待った方が安全だ。
まとめ
1Mトークンのサーチャージ撤廃と推論モデルの台頭。
アプローチは違うが、どちらも「エージェントAIを実運用するときのコストとレイテンシの壁」を削る動きだ。
コンテキスト節約のために書いた前処理コードを見直す。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
