
最近、LLMのプロンプトをいじっていて「本当に精度が上がっているのか」と不安になることはないだろうか。結論から言うと、感覚での評価はすでに限界を迎えている。LLMの回答品質を本番環境で担保するには、客観的で定量的な評価パイプラインが不可欠だ。
今回は、1人SaaS開発の現場で使えるLLMの品質評価やベンチマークの手法を10個に厳選してまとめた。どれも初心者から中級者が今日から試せる具体的なTipsばかりだ。開発現場で「なんとなく良くなった」という主観的な評価から抜け出し、確実な品質向上を目指すための参考になるはずだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
カテゴリ1:評価パイプラインの構築
主観的な評価から抜け出し、自動化された仕組みを作るところから始めよう。
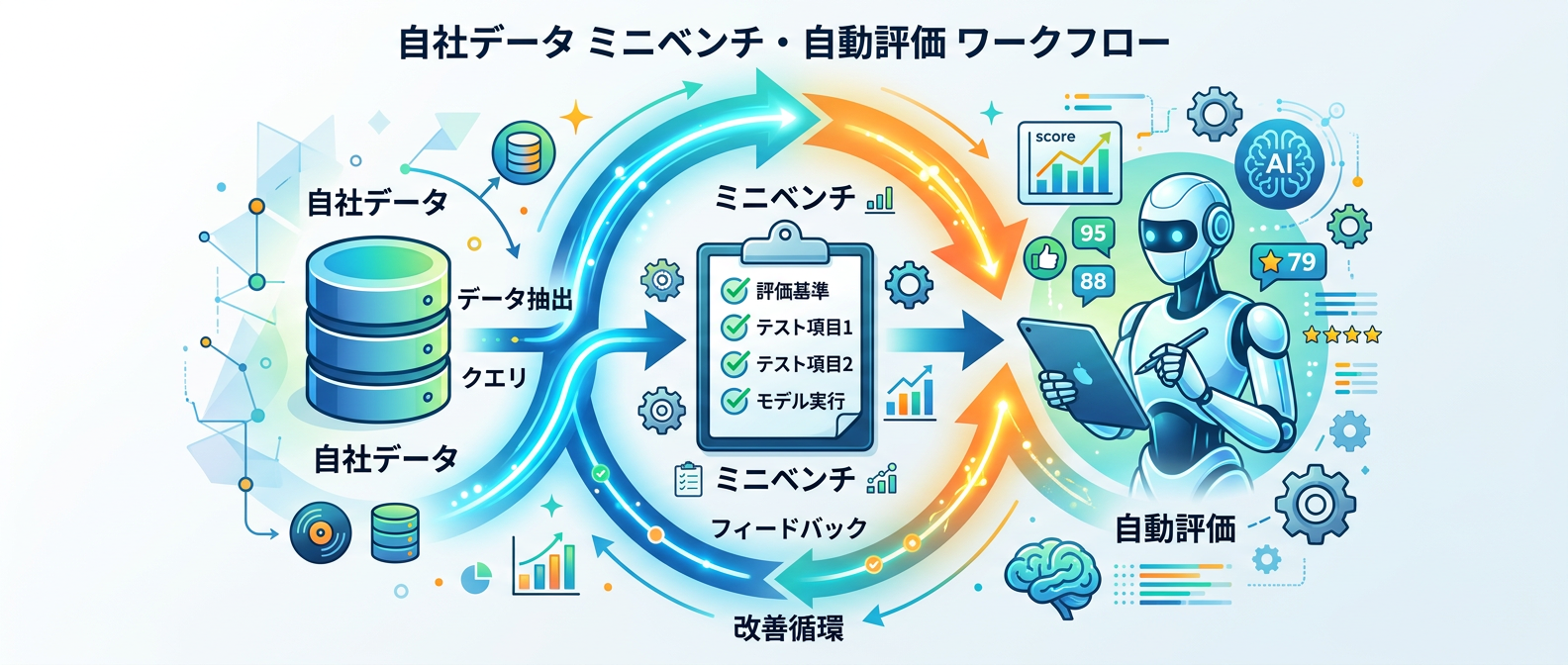
1. 自社専用ミニベンチマーク環境の構築
まずはPythonとAPIを使って、自社のタスクに合わせた小規模な評価データセットを作るのがおすすめだ。世の中にある一般的なベンチマークは規模が大きすぎて、手元の開発には向かないことが多い。
たとえば、自社サービスでよくある質問を10問から20問程度ピックアップし、理想的な正解データを用意する。これを「おもちゃベンチ」として手元に置いておく。プロンプトを変更するたびにこのデータセットでテストを回せば、改善したかどうかが一目でわかるようになる。最初は小さなデータセットで十分だ。実業務に直結したプロンプト手法の比較を迅速に行える環境を作ることが最優先になる。
さらに、このミニベンチマークは開発が進むにつれて少しずつ問題を入れ替えていくといい。ユーザーからの実際のフィードバックをもとに、LLMが間違えやすいエッジケースを追加していくことで、より実践的なテスト環境へと育っていくはずだ。
2. LLM-as-a-Judge(AIによる自動評価)の導入
手動で回答を読むのは時間がかかるし、評価者の気分によってブレが生じる。そこで役立つのが、生成された回答を別のAIに採点させる手法だ。
クラウドの評価サービスなどを活用すれば、あらかじめ設定した基準に従ってAIが自動でスコアをつけてくれる。たとえば「回答の正確性」や「トーンの適切さ」を10点満点で評価させる仕組みだ。人間による主観的な評価から脱却でき、スケーラブルな評価パイプラインを構築できる。これは今後のAI開発におけるスタンダードになるはずだ。
評価用のプロンプトには、採点基準をできるだけ具体的に記述することが重要になる。「丁寧な言葉遣いか」といった曖昧な基準ではなく、「敬語が正しく使われているか」「専門用語の解説が含まれているか」など、AIが客観的に判断できるチェックリストを用意すると評価の精度が劇的に向上する。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、テストの自動化は本当に重要だ。
理由はシンプルで、プロンプト変更のたびに手動確認するのは1人開発だと時間が足りないからだ。自動評価の仕組みは早めに作っておくと後が圧倒的に楽になる。
3. 統計的定量化によるデグレ検知
プロンプトを改善したつもりが、別の部分の回答品質が落ちてしまう「デグレ」はよく起こる。これを防ぐには、100件単位の固定データセットでテストを実施するのが効果的だ。
「なんとなく良くなった」という感覚を排除し、「今回のアップデートで精度が5%向上した」と数字で語れる状態にする。定量化されたスコアがあれば、本番環境へデプロイするかどうかの判断基準が明確になる。一部の改善が全体に悪影響を与えていないか、常に全体スコアを監視する仕組みを持とう。
また、スコアの推移をダッシュボードなどで可視化しておくと、どのタイミングの変更が品質に影響を与えたのかを後から追いかけやすくなる。継続的なインテグレーション(CI)のプロセスにこの評価を組み込むことで、品質の低下を未然に防ぐことができる。
カテゴリ2:プロンプト改善とモデル特性の把握
モデルの癖やプロンプトの影響度を正しく理解するための手法を紹介する。
4. 統計的な指標によるプロンプト改善効果の測定
プロンプト変更前後のスコア差分を、統計的な指標を用いて測定する手法だ。単なる平均点の差ではなく、データのばらつきを考慮して改善の大きさを客観的に評価できる。
統計学で使われる標準化された指標を用いると、効果の大きさを数値化しやすい。たとえば、スコアが一定基準以上なら「大きな効果があった」と判断するルールを設ける。これにより、微小なノイズによるスコア変動なのか、本当にプロンプト改善による効果なのかを見極められる。
特に、A/Bテストのように複数のプロンプトを同時に走らせて比較する場合、統計的な有意差を確認することは必須のプロセスになる。感覚的な判断を排除し、データに基づいた意思決定を行うための強力な武器になるはずだ。
5. ペルソナ付与による自己評価バイアスの検証
LLMに「あなたは天才エンジニアです」といったペルソナを付与すると、モデルの自己評価が不当に高くなる現象が確認されている。人間の心理学でいうダニング=クルーガー効果のようなものだ。
システム設計時にLLMに自信度を出力させる場合、このバイアスに注意する必要がある。ペルソナによって自信満々に間違った回答を生成するリスクが高まるからだ。モデルに自己評価させるテストを組み込み、実際の正答率とのギャップを測定しておくと安心だ。
このバイアスを軽減するためには、ペルソナの付与と同時に「客観的な事実に基づき、不確実な場合はその旨を明記すること」といった制約をプロンプトに加える手法が有効になる。

6. 回答スタイルと基本能力の分離評価
プロンプトで専門家になりきらせると、専門用語を使った洗練された回答が出力されるようになる。しかし、論理的な推論やバグを見つけるといったモデルの基本能力自体は向上しない。
評価を行う際は、「表現の適切さ」と「問題解決能力」を分けてスコア化することが重要だ。表現力はプロンプトでカバーできるが、根本的な推論力が足りない場合はモデル自体の変更を検討するしかない。この2つを混同すると、根本的な課題を見誤ることになる。
たとえば、カスタマーサポートのAIを評価する場合、「丁寧な謝罪ができているか」というスタイル評価と、「ユーザーの課題に対する正しい解決策を提示できているか」という能力評価を完全に分離して測定する仕組みが必要になる。
7. モデルの知性とプロンプト抵抗の検証
モデルのパラメータ数や賢さが上がるにつれて、システムプロンプトによる行動制御が効きにくくなるという興味深い現象がある。
小型のモデルは指示に素直に従う傾向があるが、高度な推論能力を持つ大型モデルは、プロンプトの指示よりも独自の合理的な判断を優先することがある。そのため、モデルをアップグレードする際は、以前と同じプロンプトが意図通りに機能するかを再検証する必要がある。モデルの知性に合わせて評価基準を調整しよう。
この「プロンプト抵抗」を評価するためには、あえてモデルの一般的な知識に反するような特殊なルールを指示し、それにどこまで忠実に従えるかをテストする手法が効果的だ。
カテゴリ3:高度な推論とアライメント検証
より複雑なタスクや、モデルの振る舞いそのものを評価するための高度なTipsだ。
8. ハルシネーション特化型テストの実施
LLMが嘘をつく「ハルシネーション」を防ぐには、事実の信頼性を評価する専用のテストが必要になる。
自社の専門的な知識に関する質問と、あえて存在しない架空の用語に関する質問を混ぜたテストデータを用意する。モデルが知ったかぶりをして架空の回答を生成せず、「分からない」と正しく答えられるかを測定するのだ。推論能力の高さと嘘の少なさは別軸の能力なので、専用のテストでしっかり評価しておきたい。
さらに、回答の根拠となる情報源を引用させるプロンプトを組み合わせることで、ハルシネーションの発生率を定量的に測定しやすくなる。引用元のURLや文書の該当箇所が実在するかを自動でチェックするスクリプトを組むと完璧だ。
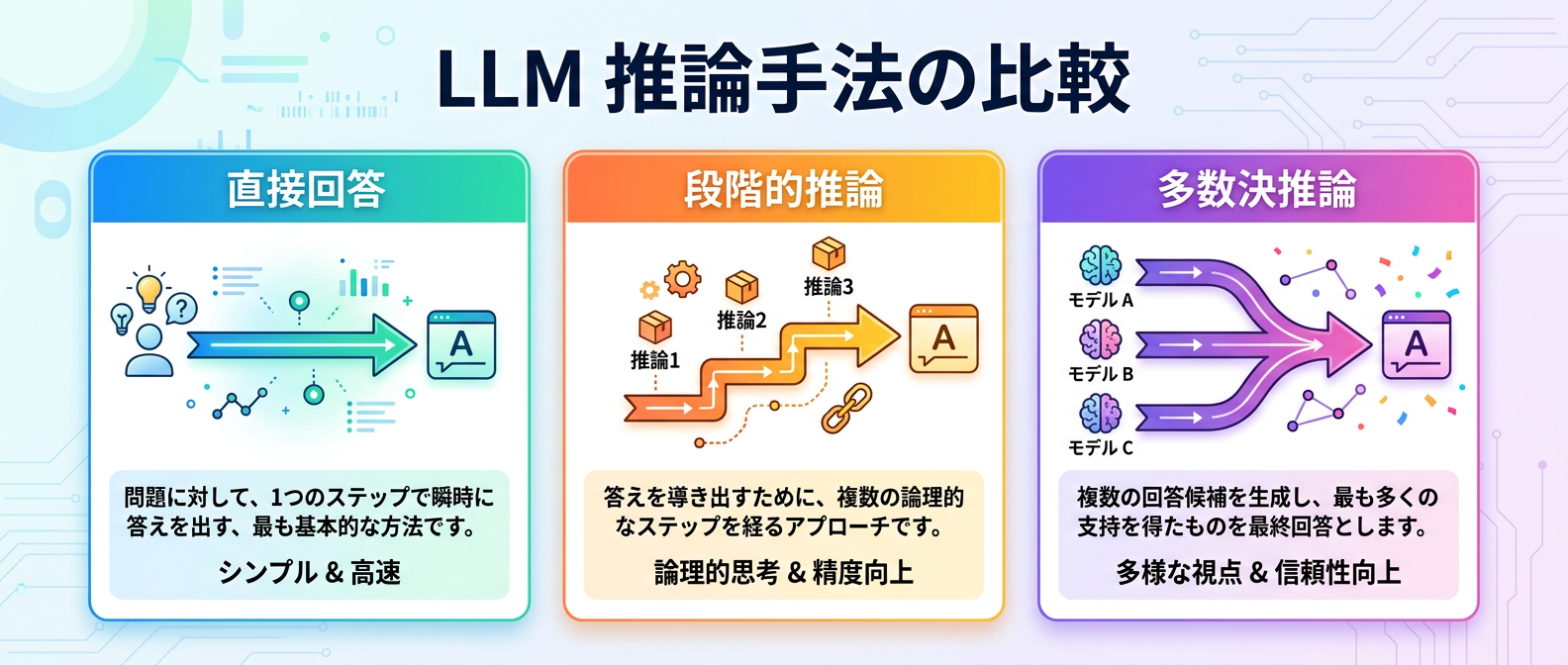
9. 複数回推論による精度の検証
複雑な計算や論理推論の精度を上げる手法として、複数回回答を生成して多数決をとる方法がある。これを実装して、単発の回答と精度を比較評価する。
1回の推論では間違える問題でも、複数回の結果を総合すると正答率が跳ね上がることが多い。ただし、APIの呼び出し回数が増えるためコストも増加する。精度向上とトークン消費のトレードオフを定量的に比較し、実業務に導入すべきかを判断するための検証が不可欠だ。
この検証を行う際は、温度パラメータ(Temperature)を少し上げて回答に多様性を持たせることがポイントになる。全く同じ回答を繰り返しても多数決の意味がないため、パラメータ調整を含めた総合的な評価が求められる。
ここで、代表的な推論手法の比較表をまとめておく。
| 手法名 | 概要 | 精度向上 | コスト | おすすめ度 |
| --- | --- | --- | --- | --- |
| 直接回答 | 質問に対して即座に答えを出力させる | 低 | 最小 | ★ |
| 段階的推論 | 思考プロセスを順番に出力させてから答える | 中 | 中 | ★★★ |
| 多数決推論 | 複数回推論を行い、最も多い答えを採用する | 高 | 最大 | ★★ |
| 自動評価 | 別のAIモデルに回答の妥当性を採点させる | 測定用 | 中 | ★★★ |
10. 反復ゲームを用いたアライメント定量評価
単なる正答率ではなく、モデルの倫理的・協力的な振る舞いを定量評価するユニークな手法だ。囚人のジレンマのようなゲーム理論の枠組みを用いてテストを行う。
モデルが「裏切った方が得な状況」に置かれたとき、全体の利益を考えて協力的な行動をとれるかを測定する。自律的に動くAIエージェントを開発する場合、こうした倫理観や協調性がシステム全体の安全性に直結する。単なる一問一答のテストでは測れない、モデルの根本的な性質を評価できる。
特に、複数のAIエージェントが相互にやり取りするような複雑なシステムを構築する際には、このアライメント評価が致命的なバグや暴走を防ぐための重要な防波堤になるはずだ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
しんたろーのイチ推しTips
僕のイチ推しは「自社専用ミニベンチマーク環境の構築」だ。
理由はシンプルで、自分のプロダクトに直結する評価ができるからだ。一般的なベンチマークの数値は実務では当てにならないことが多い。結局、自分のサービスでユーザーが入力するリアルなデータを使って、10問でもいいからテスト環境を作るのが一番確実だ。
よくある質問(FAQ)
プロンプトを改善したつもりが、別の回答が悪化してしまう。どう防げばいいか。
主観的な確認ではなく、100件程度の固定テストデータセットを用意し、AIによる自動評価を導入して定量的にスコア化するといい。変更前後のスコアを統計的に比較することで、一部の改善が全体的なデグレを引き起こしていないかを確実に検知できる。
LLMの嘘(ハルシネーション)を評価するにはどうすればいいか。
モデルが知らないことを正しく「分からない」と答えられるかを測るテストが有効だ。自社のドメイン知識に関する質問と、存在しない架空の用語に関する質問を混ぜたデータセットを用意し、知ったかぶりをして架空の回答を生成しないかを評価しよう。
プロンプトで「あなたは専門家です」と指定すると精度は上がるか。
回答の表現やスタイルは専門家らしく洗練されるが、論理的推論やバグ検出といったモデルの根本的な問題解決能力は向上しない。むしろ自己評価が過剰になるバイアスが生じることもあるため、基本能力の不足はモデル自体のアップグレードで解決するべきだ。
段階的な推論を使っても複雑な問題を間違える場合はどう評価すべきか。
推論を1回実行するだけでなく、複数回実行して最も多かった答えを採用する多数決の手法を試して比較評価するといい。精度は大きく向上する傾向があるが、トークン消費量とのトレードオフになる点に注意して実用性を判断しよう。
ローカルの小型モデルとクラウドの大型モデルで、プロンプトの効き方に違いはあるか。
明確な違いがある。小型モデルはシステムプロンプトの指示に素直に従いやすい一方、賢い大型モデルほどプロンプトによる制御に抵抗し、独自の合理的な判断を優先する傾向が確認されている。モデルの知性に合わせて評価基準を変える必要がある。
まとめ
今回は、LLMの品質評価やベンチマークに使える10個のTipsを紹介した。
結論から言うと、LLMを実運用に乗せるなら、感覚的なプロンプト調整から卒業して定量的な評価パイプラインを構築するしかない。まずは手元で10問程度の小さなテストデータを作り、改善の度合いを数字で測る習慣をつけるところから始めよう。
あなたの現場ではLLMの回答品質をどうやって評価しているだろうか。客観的な指標を持つことで、開発のスピードも確実性も劇的に上がるはずだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
