
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
冒頭フック
出た。Cursor 3.0の目玉機能、エージェントの並列実行だ。
ローカルやクラウドをまたいで複数のAIを同時に走らせる。完全に力技だ。
でも、数を増やせばコードの品質が上がるわけじゃない。
並行してAI界隈で起きているのは、Claude Codeのカスタムスキルを使った「品質ゲート」と「AutoHarness」による厳格なパイプライン化だ。
量で殴るか、質で制御するか。2026年のAI開発は、この2つのアプローチの使い分けで勝負が決まる。
ニュースの概要
AIエージェントの進化が2つの異なる方向に明確に分岐している。
一つは圧倒的な「水平スケール」の追求だ。
最新の開発環境アップデートで、複数のエージェントを同時に並列実行できる機能が実装された。
ローカル環境、ワークツリー、クラウド環境。
さらにはリモートのSSH接続先まで、あらゆる環境で複数のAIが同時にタスクをこなす。
画面上には複数のチャットがタブやグリッドで並ぶ。
開発者は指揮官のように、各エージェントの進捗を俯瞰するだけだ。
これは確かに強力な機能だ。
異なるリポジトリの修正を同時に進行させることも可能になる。
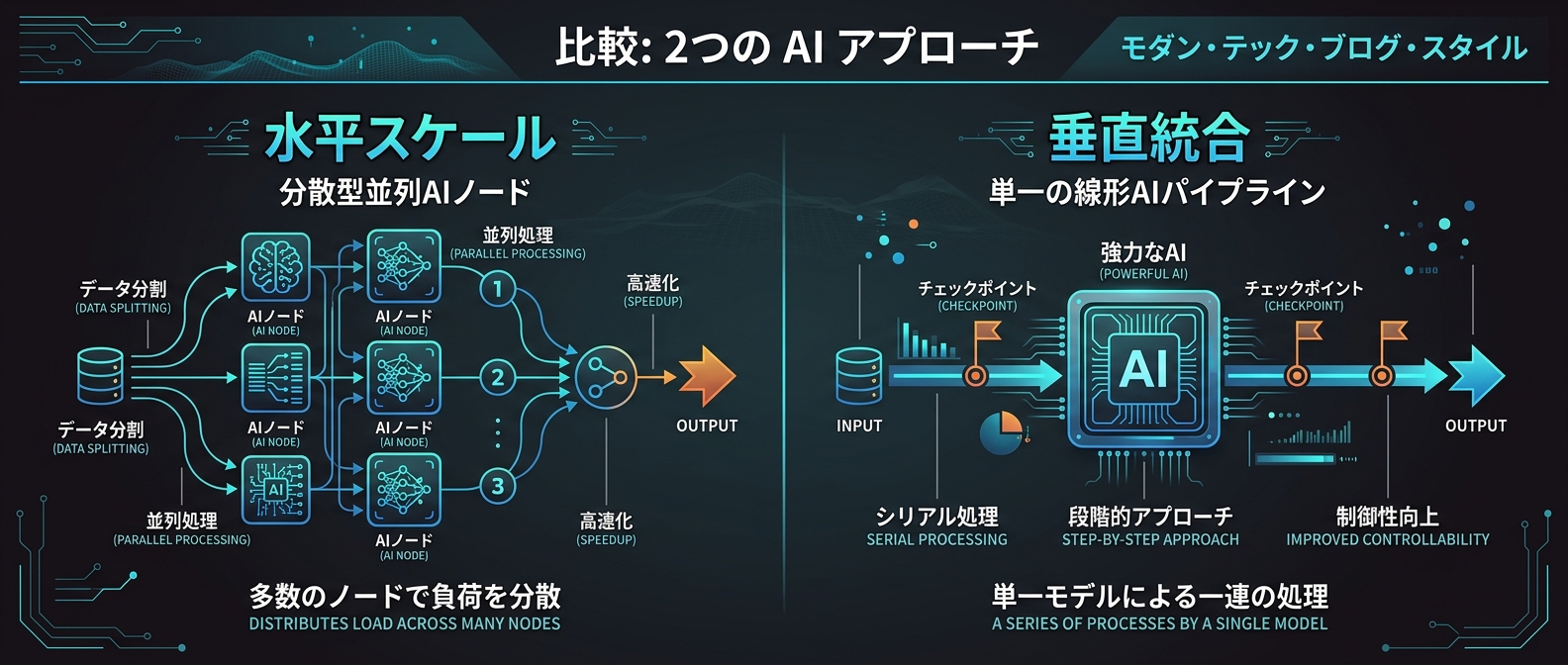
だが、並列数を増やせば増やすほど、出力の品質管理は極めて難しくなる。
ここで注目されているのが、もう一つの進化の方向である「垂直統合と品質ゲート」だ。
一部のAI開発コミュニティでは、20体ものエージェントを並列稼働させる力技を明確に否定している。
代わりに、1つのエージェント内でサブプロセスを起動し、厳格な評価基準を設けるアプローチが主流になりつつある。
API課金を無駄に消費するマルチエージェント協調は不要だという強い主張だ。
中核となるのは、特定のタスクに特化したカスタムスキルの構築だ。
リサーチ、執筆、コード生成などの各フェーズをパイプラインで一直線に繋ぐ。
そして、各フェーズの間に「品質ゲート」を設ける。
AI自身に生成物を採点させ、基準に満たない場合は自動で差し戻す仕組みだ。
ディレクトリ構成をサポートする新しいスキル定義方式が、これを可能にしている。
フロントマターで利用可能なツールを制限し、モデルの自律的な呼び出しを禁止する。
これにより、開発者の意図した通りの厳密なフローが実現する。
無駄なツール呼び出しが減り、処理速度も劇的に向上する。
さらに、この品質管理を自動化する「AutoHarness」という概念も台頭している。
プロジェクト内の設定ファイルや過去のエラー履歴から、AIが自律的にルールを学習する。
「うちのプロジェクトではこう書く」という暗黙知を、AIが勝手に言語化して検証スクリプトを作成する。
開発者が毎回同じ指摘をする必要がなくなる。
この仕組みは、最新のAI論文から着想を得たものだ。
不正な出力を根本から排除するための検証ハーネスを、AI自身に作らせる。
木探索を用いて環境フィードバックを自動収集し、ルールを反復的に洗練させる。
単なるプロンプトエンジニアリングを超えた、自律的な品質改善の仕組みだ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線の解説
複数のAIを並列で動かせるようになった。これは面白い。
でも、開発現場のリアルはそんなに単純じゃない。
エージェントを20体並べて一気にコードを書かせたらどうなるか。
コンフリクトの嵐と、プロジェクトの規約を無視したスパゲッティコードの山ができるだけだ。
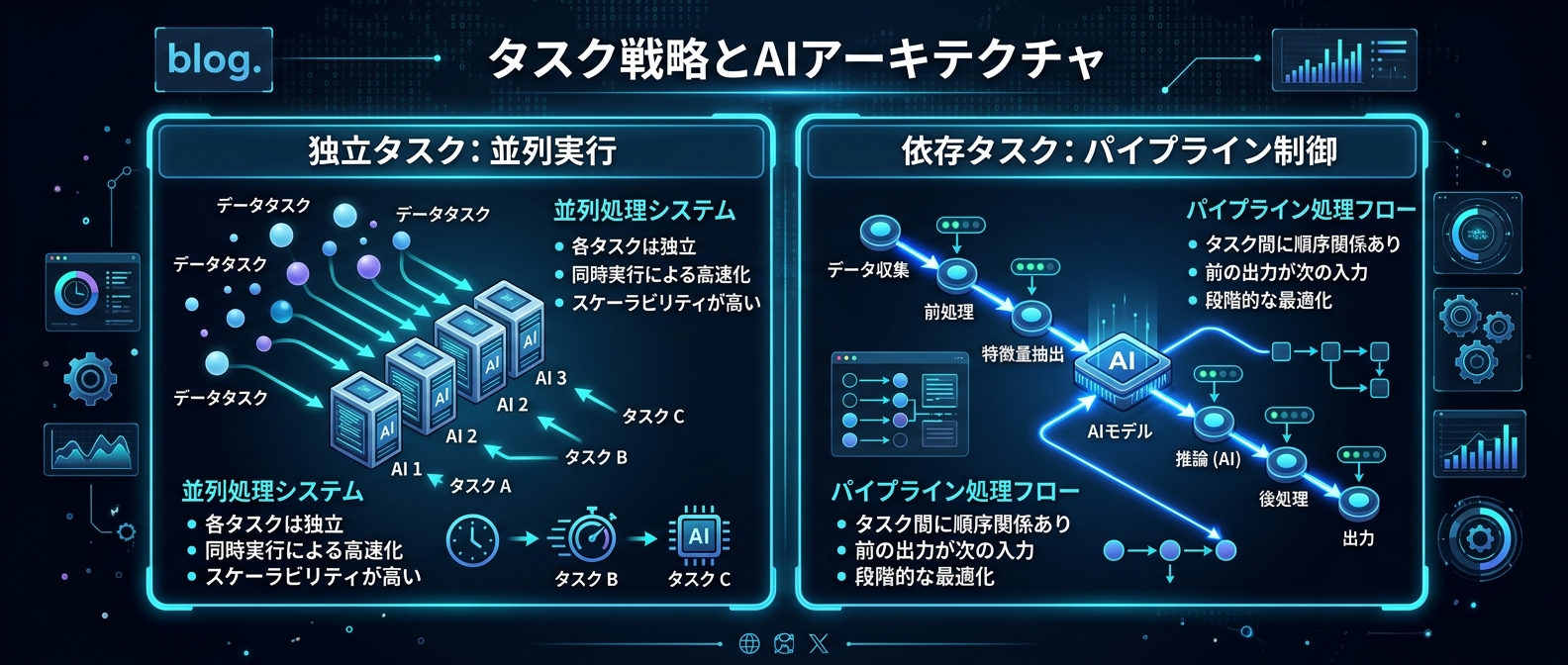
AIの数を増やす「水平スケール」は、タスクが完全に独立している場合にしか機能しない。
API制限の壁にもすぐにぶち当たる。
僕らの開発で本当に必要なのは、AIの「出力の質」を制御する仕組みだ。
ここでClaude Codeのカスタムスキルの出番になる。
1つのセッションの中で、必要な時だけサブプロセスを並列で走らせる。
フェーズごとに専門分業させ、結果を次のフェーズに渡す「垂直パイプライン」を作る。
例えばリサーチフェーズでは、複数の検索タスクを並列で実行させる。
最高評価のコンテンツと、評価が急落するラインを分析させる。
この「天井」と「床」の分析結果を、次の生成フェーズの入力として使うのだ。
既存記事がカバーしていない「ギャップ」を見つけ出す。
本文で使える具体的な数値や事例を「弾薬」として収集する。
これらを1つのエージェント内で完結させる。
しんたろー:
複数エージェントの並列化はデモ動画で見るとめちゃくちゃカッコいい。
でも、実際に自分のプロジェクトに突っ込むと、後始末のコードレビューで泣きを見るんだよな。
結局、1体のAIの手綱をしっかり握る方が実務では圧倒的に早い。
一番重要なのは「品質ゲート」の設計だ。
AIにタスクを投げっぱなしにしてはいけない。
生成されたコードや文章に対して、必ず自己採点させるフェーズを挟む。
新規性や実用度、あるいはプロジェクト規約への準拠度を10点満点で評価させる。
両方の軸で基準点を満たした場合のみ、次のフェーズに進める。
ただし、ここで大きな罠がある。
LLMは自己評価が異常に甘い。
適当なコードを書いておいて平気で「9点です」と返してくる。
これを防ぐためのハックが、「なぜ落ちたか」を3行で言語化させることだ。
基準点に満たない場合、不合格の理由を明文化させる。
これにより、AI自身が自分の出力の弱点を強制的に認識する。
その後の書き直し(差し戻し)の質が劇的に上がるのだ。
この言語化プロセスを挟むだけで、AIの出力は別物になる。
単なる要約ではなく、具体的なアクションアイテムを含む出力に変化する。
ファイルパス、実行コマンド、コピペ可能なテンプレート。
これらが欠けていることをAI自身に気づかせる仕組みだ。
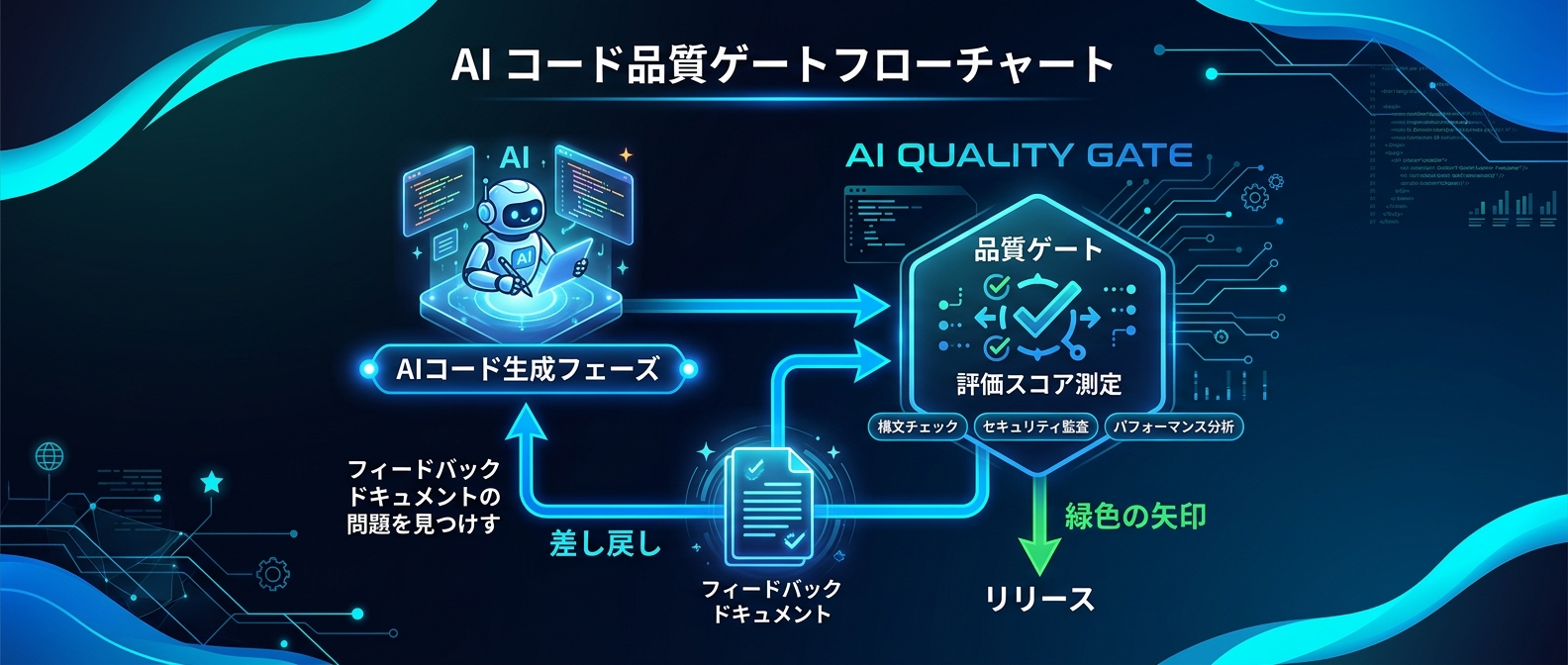
さらに踏み込むと、AutoHarnessの仕組みが開発体験を根底から変える。
プロジェクトごとのローカルルールをAIに守らせるのは骨が折れる。
特定のライブラリのバージョン、金額計算の厳密な型指定、エラーハンドリングの作法。
これらをすべて手動でドキュメント化してAIに読み込ませるのは現実的ではない。
ルールを書くのは結局人間であり、メンテナンスコストが高すぎる。
AutoHarnessは、このルール生成を完全に自動化する。
プロジェクト内の設定ファイル群を解析し、初期ルールを勝手に作る。
パッケージ管理ファイルや静的解析の設定から、プロジェクトの傾向を読み取る。
コード生成時に型エラーが出たり、テストが落ちたりしたシグナルを検知する。
開発者が「この書き方はダメだ」とフィードバックした履歴も蓄積する。
これらの環境フィードバックを自動収集し、AIが自律的にプロジェクトのルールファイルと検証スクリプトを更新していくのだ。
繰り返すほどプロジェクト固有のルールが育つ。
AutoHarnessの考え方はマジで賢い。
毎回「金額計算は専用の型を使えって言っただろ!」ってAIにキレる時間がなくなる。
ルールを教え込むんじゃなくて、AIにエラーから学習してルールを作らせる逆転の発想だ。
この「制約(ハーネス)」による単一エージェントの高度化は、並列化によるスケールとは対極にある。
しかし、出力の安定性と開発効率の向上という点では、はるかに実用的だ。
タスクを細分化し、それぞれに明確な合格基準と検証スクリプトを用意する。
このパイプラインを構築する力こそが、これからの開発者に求められるスキルになる。
エージェントに自由を与えすぎず、適切なレールを敷くことが重要だ。
評価結果のデータを見ると、その効果は一目瞭然だ。
特定のモジュールの使用率がゼロだった状態から、ハーネス導入で100%に跳ね上がる。
指示文に明記しなくても、AIが勝手にルールを守るようになる。
機能追加やバグ修正など、タスクの種類によってハーネスの効き方は異なる。
ロジックの正確性はハーネスなしでも達成できる場合がある。
しかし、コーディング規約の遵守や型アノテーションの追加は、ハーネスの明示的なルールが不可欠だ。
テスト要件が明記されることで、生成されるテストの数も自然と増える。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響
で、僕らの開発にどう影響するの?という話だ。
結論から言うと、タスクの性質によって「量」と「質」のアプローチを使い分けるフェーズに入った。
単純なリサーチや、独立した複数の環境構築など、コンテキストが交差しないタスク。
これらには、新しい開発環境の並列エージェント機能をフル活用すべきだ。
圧倒的なスピードで作業を終わらせることができる。
複数のリポジトリを同時に操作するような大規模な変更には最適だ。
フロントエンドとバックエンドの改修を別々のエージェントに同時進行させる。
こうした使い方は、並列化の恩恵をダイレクトに受けられる。
一方で、コアロジックの実装や、既存コードのリファクタリング。
こうしたコンテキストの依存関係が強いタスクに、複数エージェントの並列実行は向かない。
ここでは、Claude Codeのカスタムスキルを使った厳格なパイプライン制御に切り替える。
単一のエージェントにサブプロセスを回させ、品質ゲートを通ったものだけをマージする。
特に、機能追加やバグ修正のタスクでは、プロジェクトの規約に準拠しているかが命になる。
具体的なアクションとしては、まず自分のプロジェクトの「品質ゲート」を定義することだ。
AIにコードを書かせた後、何を基準に合格とするか。
テストの通過率か、特定の型アノテーションの有無か、パフォーマンス指標か。
これを明確にし、AI自身に自己評価と理由の言語化を行わせるプロンプトを組む。
自己申告の採点だけでなく、静的解析ツールの実行結果をゲートに組み込むのも有効だ。
次に、AutoHarnessの概念をプロジェクトに導入する。
完璧なルールブックを最初から作ろうとしなくていい。
まずは設定ファイルから読み取れる最低限のルールをAIに抽出させる。
その後は、開発中のエラーや修正履歴をフックにして、ルールを自動更新する仕組みを作る。
これにより、プロジェクト固有の暗黙知が徐々に明文化され、AIの出力精度が勝手に上がっていく。
手動で明示的にルール更新のコマンドを叩く運用から始めるのが現実的だ。
ThreadPostの自動生成パイプラインでも、この品質ゲートの考え方はかなり効きそう。
SNSの投稿文を生成する時、AIに「エンゲージメントが下がる理由」を自己分析させてから書き直させたら、出力の質が全然違ってくるはず。
単純な並列化より、こういう泥臭い制御の方が結局ビジネスの数字に直結するんだよな。
AIエージェントの数は、もはや重要ではない。
重要なのは、そのエージェントがどのようなパイプラインと制約の中で動いているかだ。
強力な並列処理能力と、厳格な品質管理の仕組み。
この2つを適材適所で組み合わせるアーキテクチャ設計が、今後のAI開発の主戦場になる。
開発者の役割は、コードを書くことから、AIの評価基準を設計することへとシフトしている。
この変化に適応できた者だけが、次の次元の開発スピードを手に入れる。
AIの出力を鵜呑みにせず、システムで制御する。
これが2026年の最前線の戦い方だ。
FAQ
Q1: 新しい開発環境の並列エージェントとClaude CodeのAgentツールの違いは何ですか?
前者は、複数の独立したエージェントを立ち上げ、異なるリポジトリや環境で同時にタスクを処理させる「水平スケール」に優れている。
後者のClaude CodeのAgentツールは、1つのタスクの中でリサーチや執筆などのサブプロセスを並列実行し、品質ゲートを通して最終出力をまとめる「垂直統合・パイプライン化」に向いている。
用途が全く異なる。
Q2: 品質ゲートでAIに自己採点させると甘くなりませんか?
単純に点数をつけさせるだけでは確実に甘くなる。
重要なのは、基準点に満たない場合に「なぜ落ちたか」を3行で言語化させることだ。
不合格の理由を明文化させることで、LLMが自身の出力の弱点を強制的に認識する。
このプロセスを挟むだけで、次の生成(書き直し)の質が劇的に向上する。
Q3: AutoHarnessはどのようにプロジェクトのルールを学習するのですか?
プロジェクト内の設定ファイル群を解析して初期ルールを自動生成する。
さらに、コード生成時の型エラーやテスト失敗、開発者からの修正指示などのフィードバックを検知する。
これらのシグナルをもとに、自律的にルールファイルと検証スクリプトを更新・洗練させていく。
開発者が手動でルールを書き続ける必要がなくなる。
まとめ
エージェントの並列化による力技と、品質ゲートによる厳格な制御。
2026年のAI開発は、この2つのアプローチをどう組み合わせるかで出力の質が全く変わってくる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
