
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
推論が生成を追い越した。AI開発の新しい常識
AIがもっともらしい答えを出す時代は終わった。これからは考えてから動くのが当たり前になる。
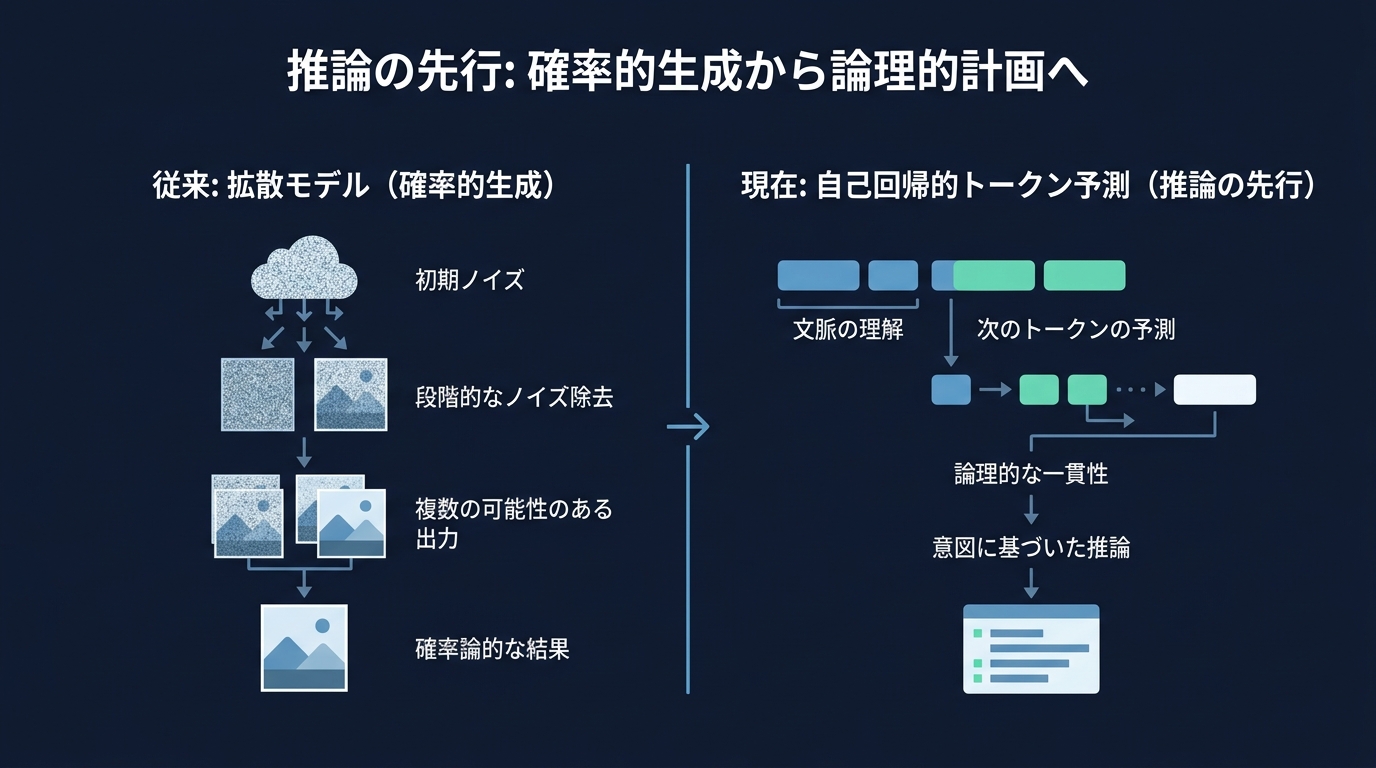
2026年。AIモデルの進化はアーキテクチャの転換点を迎えた。これまでの動画生成は確率的にピクセルを配置する拡散モデルが主流だった。
最新のモデルは違う。生成する前に何を作るべきかを論理的に計画する推論フェーズを組み込んでいる。
開発者が直面しているのは、この推論の先行をどう自分のプロダクトに組み込むかという問いだ。情報のスピードが速く、ただ追っているだけでは置いていかれる。
僕も毎日Claude Codeを叩きながらSaaSを作っている。この変化は開発の優先順位を根底から変える。
統合される知能と、分離される実行。最新AIモデルの全体像
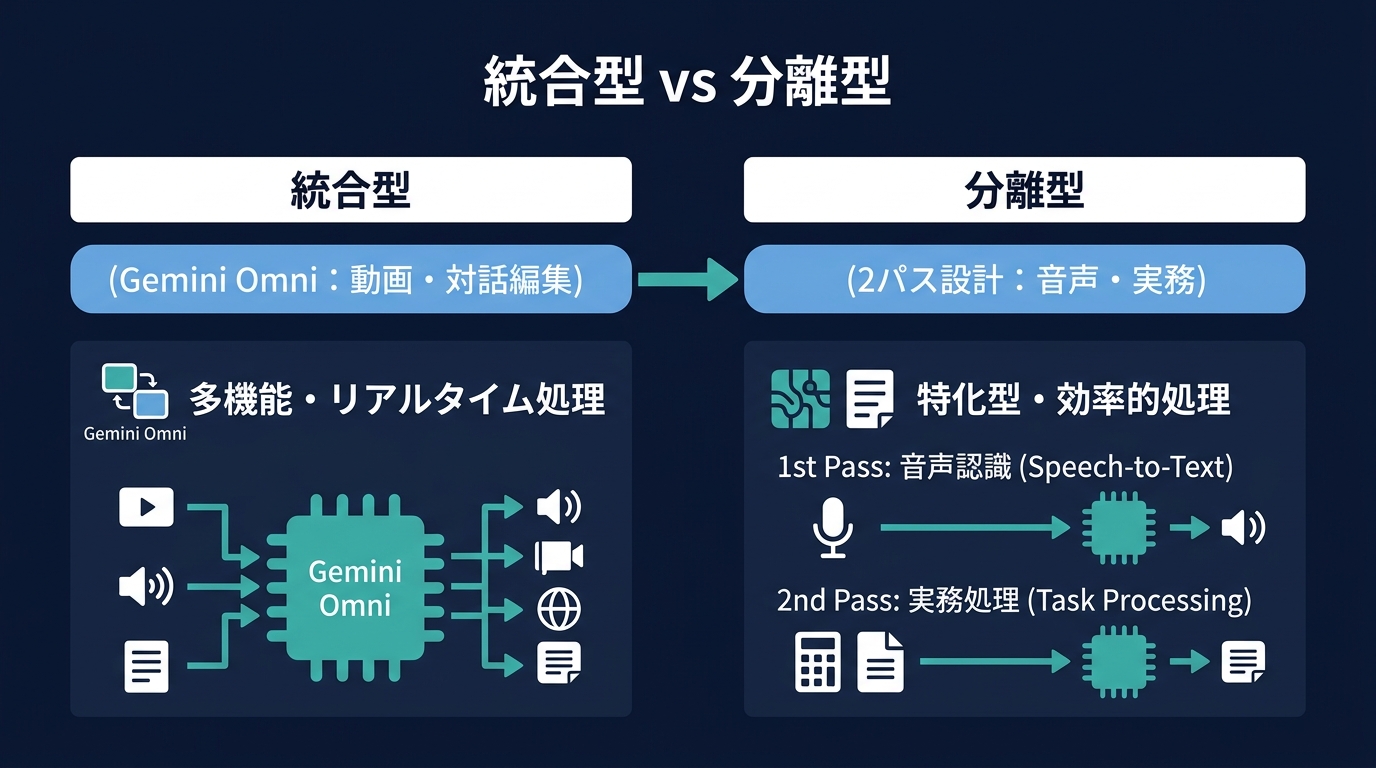
最新のAI動向は2つの方向に分かれている。あらゆる情報を一つのモデルで処理する統合型と、特定のタスクを効率よく回すモジュール型だ。
動画生成と編集の概念を塗り替えた新しいマルチモーダルモデルが登場した。テキスト、画像、音声、動画を同じ土俵で扱う。
動画を生成するだけでなく会話を通じて編集できる。これまでの動画生成は一度出力されたらやり直しが必要だった。
最新の推論エンジンを積んだモデルは物理法則や空間の整合性を理解する。彫刻を泡で作ってと指示すれば、シーンの文脈を維持したまま素材だけを論理的に書き換える。
一方でエージェント開発に特化したモデルの進化も進んでいる。3.5 Flashのようなモデルは長期的なタスクの実行に最適化されている。
開発者が求めるのはアクションだ。コードを書き、ツールを呼び出し、目的を達成する。この実行力において、推論の深さとスピードのバランスが高められている。
画像生成の分野でもパラダイムシフトが起きている。デノイジングによる生成から、デコーダー専用の自己回帰トランスフォーマーへの移行だ。画像もテキストと同じトークンとして扱う。
この方式のメリットは生成の前に意図を推論するステップを挟めることだ。右側に配置してといった空間的な論理を、次のトークンを予測するプロセスの中で解決する。
対照的な動きを見せているのがエンタープライズやエッジ環境向けのモデルだ。巨大で何でもできることよりも、小さくて特定のことが完璧にできることが重視される。
音声認識と翻訳に特化したモデルは、あえて推論と実行を分離する2パス設計を採用している。まず音声をテキストに起こし、その後に言語モデルが処理する。
計算リソースを節約でき、遅延を最小限に抑えられる。開発者が自由にカスタマイズできる土壌も整っている。
しんたろー:
全部入りモデルの進化もすごい。個人的には軽量モデルの2パス設計が気になる。全部を一つの巨大な脳みそでやろうとするとAPIコストもかかる。機能を切り分けて必要なところだけ最新の推論エンジンを呼ぶ方が扱いやすい。
開発者の視点:なぜ「推論の先行」が僕らのコードを変えるのか
推論してから生成するという流れは、僕らが書くコードの構造に影響を与える。これまでのAI連携はプロンプトを投げて結果をパースする泥臭いものだった。
モデル自体が意図のギャップを埋める能力を持ち始めると設計が変わる。画像や動画生成において空間的な論理をモデルが自律的に計画する。
UIのデザインを生成させる際、ボタンの配置や階層構造を論理的に納得した上で描画する。自己回帰型モデルはテキストと画像を交互に並べたシーケンスとして処理する。
前のフレームで起きたことを記憶し、次の意味的な塊を予測する。この意味の予測が開発で求めていた一貫性の正体だ。
僕が開発しているThreadPostのようなエージェント型ツールでもこの考え方は応用できる。複雑なタスクを依頼したとき、まずどう実行するかというプランをトークンとして出力させる。
ベンチマークの指標も変化している。見栄えだけでなく、論理的な制約をどれだけ守れているかを測るRISEBenchのような指標が重視されている。
画像理解と生成を同時に行うことで視覚的な認知能力が向上するというデータもある。作ることは理解することだという格言がAIの世界でも証明されている。
インフラ側の視点も忘れてはいけない。日本語の音声認識で高い精度を出すモデルがオープンソースで提供される意味は重い。
高価なクラウドGPUを使わなくても、ローカルやエッジデバイスで考えて動くAIを実装できる。統合型の巨大モデルをAPI経由で叩く中央集権型と、軽量モデルを組み合わせる分散型の二極化が進む。
Claude Codeを使っていると、AIが今からこのファイルを書き換えますと宣言してから動く心地よさがよくわかる。画像生成や動画生成も、この宣言に近い推論プロセスが内蔵されたことで道具として信頼できるレベルになった。昔のガチャを回すような感覚は古い開発スタイルだ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響:僕らが今すぐ見直すべき開発パイプライン
この変化を受けて、開発者は統合型への丸投げとモジュール型の使い分けの境界線を再定義する。クリエイティブな表現や直感的な編集機能を備えたアプリなら、最新の統合型モデルに全振りする。
会話形式で動画を編集できるようなインターフェースは、自前でパイプラインを組むよりもモデルの推論能力に乗っかったほうが品質も高い。物理法則の維持やキャラクターの一貫性はモデル内部の深い推論に頼る。
一方でビジネスロジックが複雑な業務システムや、低遅延が求められるツールなら話は別だ。あえて推論と実行を切り離す設計を検討する。
最新の軽量音声モデルを使って何が話されたかを確定させ、別のモデルでどう返答すべきかを論理的に判断させる。この2パスの設計はデバッグのしやすさとコストパフォーマンスにおいて選択肢となる。
Apache 2.0のような自由度の高いライセンスで提供されるモデルの活用に注目する。商用利用の制限を気にせず、自分のプロダクトのコアに組み込める。
最新の軽量モデルは以前の巨大モデルに匹敵する精度を、わずか数分の一のリソースで実現している。とりあえず最大手のAPIという思考から脱却し、タスクの性質に応じてモデルを選定するスキルがエンジニアの価値を分ける。
エージェント開発においては長期間のコンテキスト維持が鍵になる。3.5 Flashのようなモデルは複雑な手順が必要なタスクにおいて、途中で目的を見失わずに推論を継続できる。
僕らの開発パイプラインも、単発の命令ではなく一連の流れをどう管理するかに焦点を当てる。
AI開発は設計の勝負に戻ってきた。モデルが勝手に考えてくれるから楽になるのではなく、モデルにどこまで考えさせるかを決めるのが僕らの仕事だ。ThreadPostの開発でも推論のステップを明示的に分けることで安定して動くようになった。魔法を信じるのをやめて論理を組むのが近道だ。

FAQ
Q1: 動画生成において、なぜ「推論」が重要なのか?
従来の拡散モデルはピクセルの確率分布を計算するため、物理法則や空間的な整合性を理解するのが困難でした。最新の推論先行型モデルは、まずシーンの構造や意図を論理的に計画してから描画するため、一貫性が向上します。これにより、プロンプトを工夫しなくても自然言語での複雑な指示や編集が可能になります。
Q2: エッジAI開発で軽量な音声モデルを選ぶメリットは?
最大のメリットはモジュール性と効率です。統合型の巨大モデルは推論コストが高く、特定のタスクには過剰な計算資源を消費します。最新の軽量モデルは音声認識と言語モデルの推論を分離できる2パス設計を採用しており、不要な処理を省けます。商用利用が容易なライセンスで提供されていることが多く、自社製品への組み込みが容易です。
Q3: 3.5 FlashとOmni、開発者はどう使い分けるべき?
目的がアクションの実行かコンテンツの創造かで分かれます。3.5 Flashはコード生成や複雑なツールの操作、長期的なタスクの完遂といったエージェント的な動きに最適化されています。一方、Omniは動画、画像、音声を組み合わせた高度なマルチモーダル生成や、会話を通じた直感的なメディア編集に向いています。
推論の時代を、どう生き残るか
AIの進化は生成から推論へとシフトした。綺麗な絵が出るとか、自然な文章が書けるといったレベルで驚いている場合ではない。
大事なのは、その推論をどう自分のプロダクトの価値に変えるかだ。巨大な知能にすべてを委ねるのか、それとも軽量なモデルを組み合わせて自分だけのパイプラインを作るのか。
モデルが考えていることを前提に、僕らも設計を考え直す必要がある。僕もClaude Codeを使い倒しながら、この新しい時代の開発スタイルを模索し続けている。毎日が試行錯誤だ。
君の開発パイプラインは、この変化に対応できているか。生成の先にある推論の力をどう使いこなすか。その答えが次のヒットプロダクトを生む。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

なぜClaude Codeは自律的な同僚になるのか。Opus 4.8で変わる開発の現場と信頼の完全ガイド

なぜAnthropicの巨額調達が開発の分かれ道になるのか。Claude Codeの実装と次世代モデルの選択を徹底解説

【2026年版】Claude Codeの神機能10選|生産性を限界まで引き上げる最適化術

なぜAI開発はGUIを捨てCLIへ回帰するのか。Claude Codeが示す自動化の最適解

Google AI Studioでコード不要に。なぜ開発者は設計能力が問われるのか徹底解説
