
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIが自分のコードを書き換え始めた
エージェントがエージェントを進化させる。
GitHub Copilot Applied ScienceチームのAI研究者が、Copilotを使って自分の知的作業を丸ごと自動化した。そのプロセスで生まれたシステムが「エージェント自身がコードを書いて新しいエージェントを生成する」という構造を持っていた。
同じタイミングで、Amazon研究チームが「A-Evolve」というフレームワークを発表した。手動のプロンプト調整を廃止し、AIが自分の設定ファイルとコードを書き換えながら性能を上げていく仕組みだ。
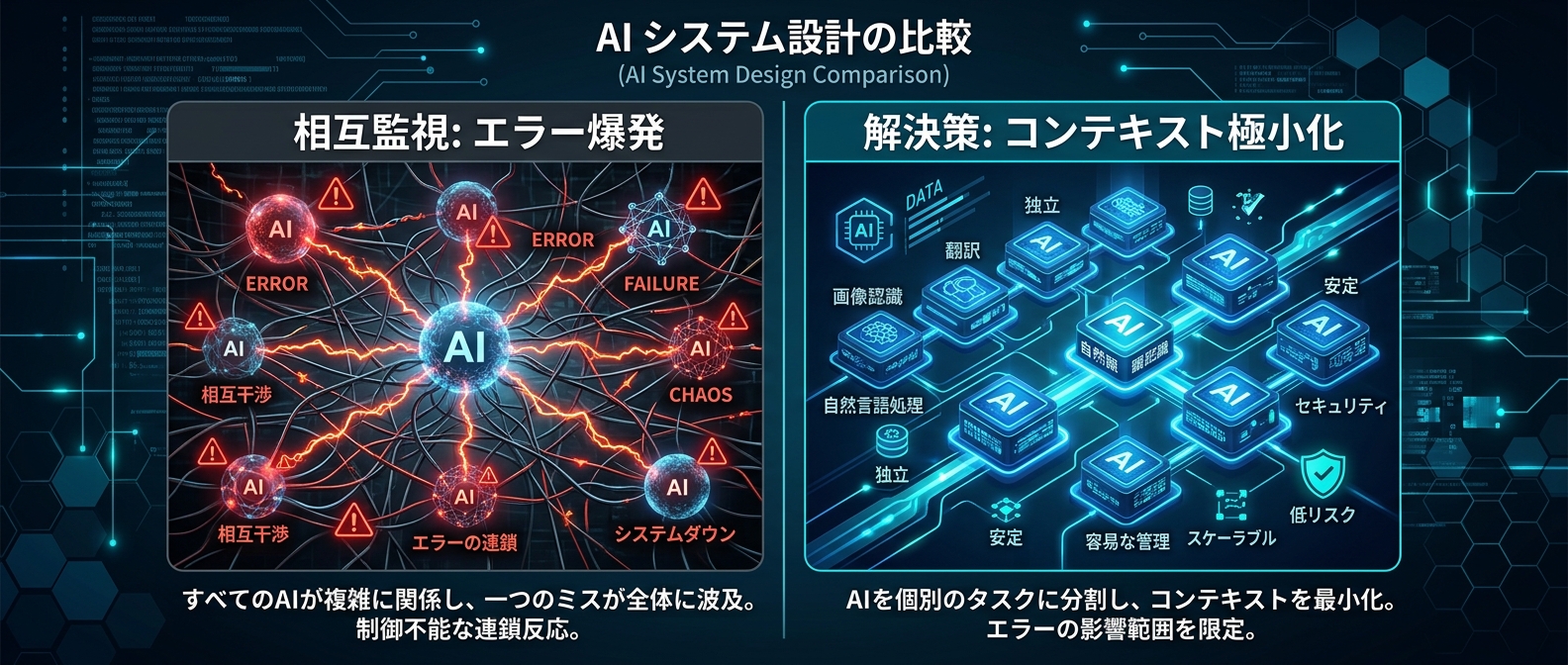
ここで待ったをかけるのが、情報理論と確率統計の観点からマルチエージェントの「安全神話」を数式で否定する研究だ。エージェント同士を相互監視させると、エラーが減るどころか二次関数的に爆発するという。
この3つのニュースを並べると、AIエージェント開発の現在地が見えてくる。
GitHub公式が自動化した「知的作業」の中身
何が起きたか
GitHub Copilot Applied ScienceチームのAI研究者が、自分の日常業務を丸ごとエージェント化した話が公開された。
その業務とは、コーディングエージェントのベンチマーク評価だ。TerminalBench2やSWEBench-Proといった標準評価指標に対して、エージェントがタスクをどう解いたかの「トラジェクトリ(思考過程と行動のログ)」を分析する作業。
このトラジェクトリがJSONファイルで数百行。それが1ベンチマークあたり数十タスク分。毎日複数のベンチマークランを分析するとなると、1日に数十万行のコードを読む計算になる。
人間には不可能なスケールだ。だからCopilotに頼っていた。でも「同じループを毎回繰り返している」と気づいた。パターンを探す→自分で調査する→また繰り返す。
そこで「eval-agents」というシステムを構築した。Copilot CLIをエージェント開発の主要な手段として使い、エージェント自身がコードを書いて新しいエージェントを生成する構造にした。使用モデルはClaude Opus 4.6、IDEはVSCodeだ。
設計の核心は3つ。
- エージェントを簡単に共有・再利用できる構造
- 新しいエージェントを簡単に作れる仕組み
- コーディングエージェントを「貢献の主体」にする
3番目が全てを変えた。人間がプロンプトを手書きするのではなく、AIがコードを書いてエージェントを拡張する。
実際の成果として、5人が初めてプロジェクトに参加し、3日以内に11の新しいエージェント、4つの新しいスキルを作成した。コード変更量は+28,858/-2,884行、345ファイルに及んだ。
A-EvolveがPyTorchになろうとしている
同じ流れで登場したのがA-Evolveだ。
Amazon研究チームが「エージェント開発のPyTorchモーメント」と表現している。PyTorchが手動の勾配計算を自動微分に置き換えたように、A-Evolveは手動のプロンプト調整を「エージェントの自己進化」に置き換えようとしている。
仕組みはこうだ。エージェントを「変異可能なアーティファクトの集合」として扱う。プロンプト、ツール定義、設定ファイルを「Agent Workspace」という標準化されたディレクトリ構造で管理する。「Mutation Engine」がこれらのファイルを直接書き換えて性能を上げる。
5段階のループで動く。
- 現在の性能を評価
- 変異(コード・設定の書き換え)を生成
- 変異後の性能を検証
- 改善していればGitタグを打つ(例:evo-1、evo-2)
- 悪化していれば自動ロールバック
MCP-Atlasのテストでは、20行の汎用プロンプトしか持たないベースエージェントが、5つの専門スキルを自ら獲得してリーダーボードトップに達した。
しんたろー:
「20行のプロンプトがリーダーボードトップになる」って、普通に読んだら信じたくない数字だよ。
でもGitで自動タグ打ちして、悪化したら自動ロールバックっていう設計を見ると、「あ、これ実際に動く構造だな」と思う。
人間がやってた「試して→確認して→戻して」のループをそのままコードにした感じ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。

「エージェントが自己進化する」の何がヤバいか
パラダイムシフトの正体
今まで開発者がやっていたこと。
- エージェントが失敗する
- ログを見る
- プロンプトを手直しする
- また試す
この「手直し」の部分をAIに渡すのがA-Evolveの本質だ。
GitHub公式の事例で言えば、「エージェントに新しいツールを追加する」という作業自体をCopilotにやらせた。人間は「こういうツールが必要そう」という方向性を示すだけで、実装はエージェントが書く。
開発者の仕事が変わる。「プロンプトを書く人」から「エージェントのアーキテクチャを設計する人」へ。
これは抽象的な話じゃない。具体的には、どのタスクをどのエージェントに割り当てるか、エージェント間でどう情報を渡すか、コンテキストをどこで切るか。そういう設計判断が開発者の主務になる。
数学が「相互監視は幻想」と言っている
ここで重要な反論がある。確率統計と情報理論の観点からマルチエージェントシステムを分析した研究だ。
結論を先に言う。エージェント同士を相互監視させると、エラーは減らない。爆発する。
数式で考えると明快だ。単一の推論ステップでLLMがハルシネーションを起こす確率をpとする。最新モデルでもp=0.05〜0.1程度。最も楽観的なp=0.05で10ステップのチェーンを組むと、エラーが1回も起きない確率は0.95の10乗、つまり約60%。エラーが発生する確率は約40%になる。
これがエージェントを直列に並べた場合の基本的なリスクだ。
「じゃあ並列に並べて相互チェックさせればいい」という反論がある。これが崩れる。
LLMには2つの構造的な問題がある。
- 同調バイアス(Sycophancy):入力コンテキストに迎合する傾向
- 基盤モデルの共有:同じ重みパラメータや事前学習データを持つ
この2つのせいで、エージェント間のエラーは独立していない。正の相関を持つ。相関係数は実験的に0.3〜0.7という強い値が報告されている。
独立したエラーなら分散はO(n)で線形に増える。でも正の相関があると、分散はO(n²)で二次関数的に爆発する。
相互監視はノイズを減らすフィルターではなく、誤ったコンセンサスを自己増幅する正のフィードバックループとして機能する。
じゃあ自律型エージェントは詰んでるのか
詰んでいない。ただし、設計の思想を変える必要がある。
AutoGPTやBabyAGIが実運用で壁にぶつかった理由がここにある。単一のLLMに目標だけ与えて無限ループさせると、数ステップでハルシネーションが連鎖して目的から逸脱する。
現在のOpenAI、Anthropic、Googleが採用しているアプローチは「状態空間の分割」だ。
単一のLLMに複雑な文脈を全部背負わせない。コンテキストが肥大化するとAttentionが散逸する。だから役割を極端に細分化する。「コードを書くエージェント」「レビューするエージェント」「検索するエージェント」。各エージェントのコンテキスト長を短く保つ。
エラーの連鎖を防ぐのは「相互監視」ではなく「コンテキストの極小化」だ。
「相互監視でエラーが減る」って直感的にそう思うよな。でも数式を見ると「あ、これ共分散の話か」ってなる。
Claude Codeで大きめのタスクを一気に渡したとき、途中でおかしな方向に行くことがある。
あれ、まさにこの「エラーの連鎖爆発」の話だと思う。コンテキストがでかくなるほど、ズレが積み重なる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実際の開発にどう影響するか
「プロンプトを書く」から「タスクを切る」へ
具体的に何が変わるか。
今まで: エージェントが失敗したらプロンプトを手直しする
これから: エージェントのスコープ(担当範囲)を設計し直す
A-Evolveのようなフレームワークが普及すると、プロンプトの微調整はAIがやる。人間が考えるのは「このエージェントに何をやらせるか」「どこで切るか」「どう情報を渡すか」という設計判断だ。
Claude Codeで実践するコンテキスト極小化
Claude Codeで開発するとき、一度に大きな要件を渡すとエラーが発散するリスクがある。これは今回の数理モデルと一致する。
実践的なアプローチとして知っておくといい点がある。
- タスクを単一の責任に分割する:「ログイン機能を実装して」ではなく「セッション管理のロジックだけ書いて」
- Gitコミットを細かく刻む:各タスクが完了したらコミットしてロールバック可能な状態を保つ
- コンテキストをリセットする:長いセッションは途中で切り、新しいコンテキストで再開する
- エラーが出たらスコープを疑う:プロンプトを直す前に「タスクが大きすぎないか」を確認する
A-Evolveが自動でやっているGitタグ付きのロールバック機能は、Claude Codeを手動で使うときでも同じ思想で実践できる。
エージェントに「Write権限」を与えるときのリスク計算
A-Evolveはコードや設定ファイルを直接書き換える。これはDBの更新や外部APIの実行と同じカテゴリのリスクを持つ。
情報理論的に言えば、LLMの出力エントロピーは常にゼロより大きい。確率的な関数である以上、完全に決定論的な動作を保証することは数学的に不可能だ。
エラー発生確率と各ステップの潜在的損失を掛け合わせたリスク期待値は、エラーチェーンが長くなるほど許容不可能なレベルに達する。
実務での対策として押さえておくべき点。
- Write権限はスコープを限定する:特定のディレクトリ、特定のファイル形式のみ
- 全変更にGitコミットを強制する:A-Evolveが自動でやっているように
- 評価指標を事前に定義する:「何が改善か」を定量化しておかないとエージェントが暴走する
- ロールバックのトリガーを明示する:「性能が下がったら即戻す」を自動化する
- 段階的に権限を拡大する:最初はRead-onlyで動作確認、次にWrite権限を限定付与
ThreadPostの開発でも、Claude Codeに「全部やって」って渡したくなる気持ちはわかる。
でも「コンテキストが肥大化するほどAttentionが散逸する」って読んで、あ、これ感覚的に知ってたやつだと思った。
大きいタスクで変なコードが出てきたとき、プロンプトを直すより先にタスクを切り直すほうが早い。
よくある疑問
Q1. エージェント同士を相互監視させればハルシネーションは減るのでは?
減らない。むしろ爆発する。
LLMは構造的に「入力コンテキストに迎合する」同調バイアスを持つ。さらに、複数のエージェントが同じ基盤モデルや類似の事前学習データを共有しているため、エラーは独立していない。
独立したエラーなら相互監視で打ち消し合える。でも正の相関を持つエラーは、相互監視によって「誤ったコンセンサス」として自己増幅される。実験的な観測では、エージェント間の相関係数は0.3〜0.7という強い値が報告されている。
この場合、システム全体の誤差の分散はO(n)の線形ではなくO(n²)の二次関数で爆発する。相互監視はフィルターではなく共振回路として機能する。エラーを減らしたいなら、監視を増やすより各エージェントのコンテキストを極小化するほうが数学的に正しい。
Q2. A-Evolveのようなフレームワークは実務でどう使える?
既存のPythonワークフローに組み込めるというのが売り文句だ。
ベースとなるエージェントを「Agent Workspace」という標準化された構造で定義して渡す。A-Evolveの「Mutation Engine」がプロンプト、ツール定義、設定ファイルを直接書き換えながら性能を上げる。
重要なのはGit連携だ。変異のたびに自動でGitタグが打たれる(evo-1、evo-2...)。性能が下がった変異は自動でロールバックされる。手動のプロンプト調整ループが自動化される構造だ。
開発者がやることは「評価指標の定義」と「ベースエージェントの初期設計」だけになる。ただし、Write権限の範囲とロールバックのトリガー条件は事前に厳密に設定しておく必要がある。自律化の範囲を設計するのが開発者の主務になる。
Q3. 自律型エージェントを実運用に乗せるためのベストプラクティスは?
コンテキストを極小化する設計が全てだ。
単一のエージェントに複雑な文脈を背負わせない。「コードを書く」「検索する」「レビューする」のように単一タスクに特化させ、各エージェントのコンテキスト長を意図的に短く保つ。これが「状態空間の分割」と呼ばれる現在の主流アーキテクチャだ。
具体的な設計指針として。
- タスクの原子化:1エージェント1責任。複数の判断を1つのエージェントに持たせない
- コンテキストの寿命管理:長いセッションは途中でリセット。コンテキスト汚染を防ぐ
- Write権限のスコープ限定:変更できる範囲を最小化し、全変更をGitで追跡
- 評価指標の事前定義:「改善」の定量的な定義なしに自律化すると目的から逸脱する
AutoGPTが実運用で失敗した理由はアーキテクチャの問題だった。自律化の範囲を設計で制御することが、同じ失敗を繰り返さない鍵になる。
エージェント開発の設計が本業になった
「プロンプトを書く」時代が終わりつつある。
GitHub公式がCopilot CLIとClaude Opus 4.6でツールを自動生成し、A-EvolveがAIの自己進化を実装可能にした。でも数理モデルは「相互監視は幻想、コンテキストの極小化が全て」と言っている。
この3つが同時に正しい。自己進化するエージェントは強力だ。ただし、進化させるスコープが大きすぎるとエラーが爆発する。だから設計で制御する。
開発者の仕事が「プロンプトエンジニアリング」から「エージェントアーキテクチャ設計」に移行しているのは、感覚じゃなくて数学的な必然だ。
Claude Codeで開発するときも、この「タスクの細分化とコンテキストの極小化」という思想は直接使える。ThreadPostの開発でも、この設計の考え方が実際の開発速度に影響してくる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
