
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
異次元のコスト削減。開発者が直面する「推論の経済性」
AI開発の主戦場が変わった。
これまでは「どれだけ賢いか」が全てだった。
今は「どれだけ安く、速く、大量に回せるか」が問われる。
Googleが発表した Gemini 3.5 Flash。
推論コストは最大で 6倍 下がる。
100万トークン あたりの単価が変化した。
AIは「たまに使う便利な道具」から「24時間動き続けるインフラ」へ移行する。
開発者が直面していた「API破産」の恐怖に対し、技術による解決策が提示された。
数字が全てを物語る。
Gemini 3.5 Flash は、前世代の Pro モデルに匹敵する知能を持ちながら、速度は高速だ。
コストは半分以下に抑えられている。
この裏側には、単なるモデルの軽量化ではない技術がある。
KVキャッシュ と呼ばれる「AIの記憶の置き場」を圧縮する技術だ。
しんたろー:
100万トークンの壁が、誤差レベルになりつつある。
毎日 Claude Code で巨大なリポジトリを読み込ませる身として、このコスト低下は気になる。
賢いモデルは十分だ。今は、安くて速い「戦えるモデル」が欲しい。

開発者の常識を塗り替える。新世代モデルと圧縮技術の正体
Googleが放った Gemini 3.5 Flash は、エージェント開発に特化したモデルだ。
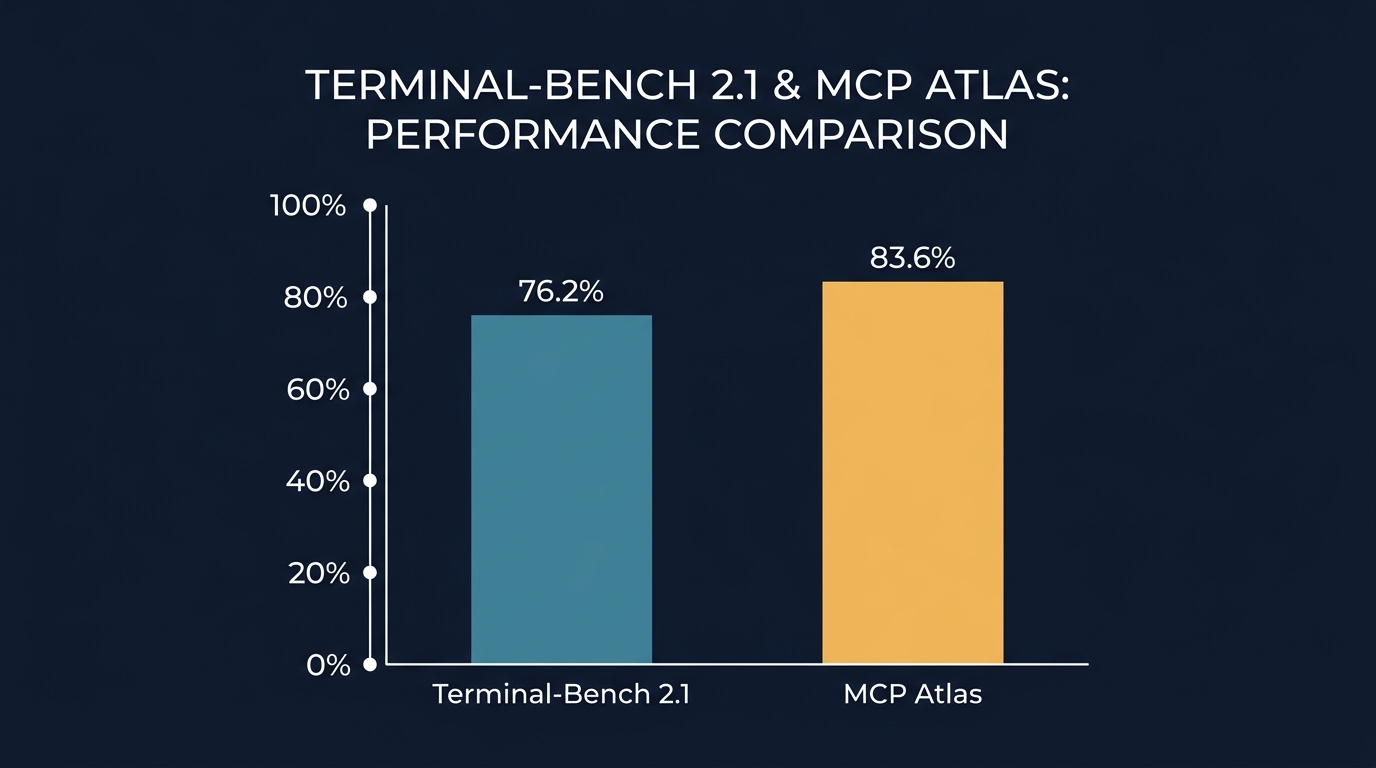
Terminal-Bench 2.1 で 76.2% のスコアを記録し、コード生成やターミナル操作の正確性を示した。
さらに MCP Atlas では 83.6% を記録した。
AIがテキスト生成だけでなく、外部ツールを使いこなし、複雑なタスクを完遂する能力が Pro クラスに到達した。
圧倒的な低レイテンシも実現している。
この爆速化を支える技術の1つが、新しく公開された TurboQuant というアルゴリズムだ。
AIの「作業メモリ」である KVキャッシュ を、精度を維持したまま 6倍以上 圧縮する。
これまで、長大なコンテキストを扱うとメモリが溢れ、推論コストが跳ね上がっていた。
TurboQuant は、このボトルネックを数学的に解決した。
具体的には、PolarQuant と QJL という2つの手法を組み合わせている。
ベクトル量子化という技術を使い、情報の密度を高める。
AIはより多くの情報を、より少ないメモリ空間で保持する。
巨大な図書館の蔵書を、一冊のノートに書き写すような仕組みだ。
一方で、FlashKDA も推論効率化の技術として挙げられる。
これは Kimi Delta Attention という機構を、NVIDIAのハードウェアに最適化させたものだ。
FlashKDA は、従来の Softmax Attention が抱えていた「入力が長くなると計算量が爆発する」という弱点を克服した。
線形アテンションという手法を用い、計算量を入力の長さに比例する形に抑え込んでいる。
その結果、1.72倍から2.22倍 の高速化を実現した。
100万コンテキスト を超える処理において、従来比で 6倍 のスループットを記録する。
これらはAIの運用コストを根本から変える技術だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
TurboQuant の話を聞いたとき、ドラマに出てくる圧縮アルゴリズムを思い出した。
理論上の限界に挑む姿勢に惹かれる。
結局、GPUをどれだけ効率よく回すかの勝負だ。

開発者目線の深掘り。なぜ「KVキャッシュの圧縮」が未来を決めるのか
Googleや Moonshot AI は、KVキャッシュ の削減に注力している。
それは、AIエージェントの「息切れ」を防ぐためだ。
ThreadPost のようなアプリでも、AIに過去の文脈を全て覚えさせようとすると、コストが課題になる。
特に Claude Code のようなコーディングエージェントは、リポジトリ全体の構造を把握し続ける必要がある。
この「把握し続ける状態」を維持するのが、今のAIにとってコストがかかる作業だ。
KVキャッシュ とは、一度計算した「過去の記憶」を保存しておく場所だ。
入力が長くなればなるほど、このキャッシュは肥大化する。
GPUのメモリ(HBM)は高価で、容量も限られている。
キャッシュがメモリを占領すれば、一度に処理できるユーザー数は減り、コストは跳ね上がる。
Googleの TurboQuant は、このキャッシュを 6倍 に縮めた。
同じGPUで 6倍 のユーザーを捌ける、あるいは 6倍 長い文脈を保持できることを意味する。
開発者として無視できない変化だ。
さらに、FlashKDA が採用している線形アテンションの進化もある。
これまでの線形アテンションは、計算は速いが「記憶の精度」が低いという弱点があった。
しかし、FlashKDA はチャンネルごとの細かな制御(ゲート機構)を取り入れることで、この問題を解決している。
「速くて、安くて、ちゃんと覚えている」という状態が手に入りつつある。
AIエージェントが自律的にコードを書き、バグを直し、デプロイまで行う。
その過程で、AIは何度も「思考」を繰り返す。
1回の思考が安くなれば、エージェントはより多くの試行錯誤ができる。
「1回で正解を出せ」というプレッシャーから解放され、「100回試して最適な解を見つけろ」という設計が可能になる。
これが、Gemini 3.5 Flash や TurboQuant がもたらす価値だ。
知能の高さよりも、試行回数の多さが勝利を決めるフェーズに突入した。
Claude Code で「このエラー直して」と投げた時、裏で100回試行錯誤してくれてもコストが1円なら、迷わずそれを選ぶ。
賢い一撃より、泥臭い百撃だ。
開発効率をブーストさせるのは、いつだって「安さ」と「速さ」だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響。僕らは今、何を知っておくべきか
この技術革新は、開発現場に影響を与える。
まず、モデル選定の基準 が変わる。
これまでは「GPT-4oかClaude 3.5 Sonnetか」という、純粋な知能指数の比較が主だった。
これからは、「そのモデルは KVキャッシュ の効率化がなされているか」「長文脈の維持コストがいくらか」が選定基準になる。
具体的には、以下のようなアクションが考えられる。
- インフラの再評価
自前で推論サーバーを立てている場合、vLLM や TensorRT-LLM といった推論バックエンドが、TurboQuant や FlashKDA のような最新の圧縮カーネルをいつサポートするかを注視する。
サポートされた瞬間に、同じハードウェアでスループットが数倍に跳ね上がる可能性がある。
- エージェント設計の転換
「コンテキストを節約するために過去のログを削る」という設計を捨てる準備をする。
圧縮技術によって、数万トークンの履歴を持ち続けることが当たり前になる。
「忘れないAI」を前提とした、より高度なUX設計が可能になる。
- コスト構造の再計算
Gemini 3.5 Flash のようなモデルを使えば、これまで採算が合わなかった「全自動カスタマーサポート」や「コードベースの常時監視」といったサービスが、現実味を帯びる。
自分のプロダクトのどの部分を「AIの垂れ流し」にできるか、洗い出しておく。
ただし、注意点もある。
圧縮技術は、稀に「重箱の隅をつつくような推論」で精度を落とすことがある。
特に、極限まで圧縮された KVキャッシュ は、非常に細かいニュアンスを切り捨てている可能性がある。
要約や一般的なコード生成なら問題ないが、厳密な論理パズルや数学的な証明を求める場合は、従来通り Pro モデルや非圧縮の環境での検証が欠かせない。
AIは「安くて大量に消費するもの」になる。
僕ら開発者は、その溢れる計算資源をどう使いこなすか、そのクリエイティビティを問われている。
コストが下がった分、浮いた予算でさらにエージェントを回すか、それとも利益率を上げるか。
僕は迷わず、エージェントに「もっと考えさせる」方に全振りする。
Claude Code がもっと賢く、もっと速く動く未来が待ち遠しい。
FAQ
Q1: TurboQuantやFlashKDAは、自分のアプリにどう導入すればいいですか?
現時点では、TurboQuant はGoogleの内部インフラでの最適化がメインであり、直接アルゴリズムをいじる機会は少ない。一方で FlashKDA はオープンソースとして公開されている。NVIDIAの H20 や H100 を積んだサーバーを持っているなら、既存の推論ライブラリのバックエンドとして組み込むことが可能だ。個人開発者なら、これらの技術が統合された Gemini API や、最新の vLLM アップデートを待つのが現実的だ。技術を直接触るというより、「長文脈が安くなる」という前提でアプリの設計図を書き換えることが先決だ。
Q2: KVキャッシュの削減は、モデルの精度に影響しませんか?
理論上、圧縮は情報の欠落を伴う。しかし、TurboQuant も FlashKDA も、実用的な範囲での精度維持を最優先に設計されている。特に TurboQuant は、量子化による誤差を最小限に抑えるための学習手法を組み合わせている。日常的に行うコード生成やテキスト要約、チャット応答において、その差を人間が感知するのは難しい。ただし、100万トークンの極限状態で、特定の1行を正確に引用するような「針を探す」タスクでは、ベンチマークをとって慎重に評価する必要がある。
Q3: なぜGoogleは「Flash」モデルにこれほど力を入れるのですか?
AIの普及において、最大の壁は「電気代とチップ代」だからだ。どれだけ賢いモデルを作っても、1回100円かかっていたら一般ユーザーには浸透しない。Googleは検索エンジンで培った「膨大なリクエストを低コストで捌く」というDNAを持っている。Gemini 3.5 Flash を強化し、インフラ層で TurboQuant を走らせることで、競合他社が追随できないレベルの「推論の経済圏」を作ろうとしている。開発者を取り込み、AIエージェントをGoogleのプラットフォーム上で最も安く動かせるようにする。これが彼らの勝ち筋だ。
結論:AIは「賢さ」の先にある「経済」のフェーズへ
Googleの Gemini 3.5 Flash と、それを支える TurboQuant。
そして Moonshot AI の FlashKDA。
これらが示しているのは、AI業界の成熟だ。
モデルが賢いのは当たり前だ。
その上で、どれだけ安く、どれだけ長く、隣で働き続けられるか。
その勝負が始まった。
100万トークン を数円で扱える未来。
そこでは、コードを書くのも、リサーチをするのも、SNSを運用するのも、全てがAIエージェントとの共同作業になる。
開発者は、コストの呪縛から解き放たれ、より本質的な「何を作るか」に集中できる。
推論コストが6倍下がる未来、あなたのAIエージェントはどう進化するか。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
