
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
思考プロセスの使い捨てが終わる
次世代エージェントモデルが一斉にリリースされた。GPT-5.5の登場だ。
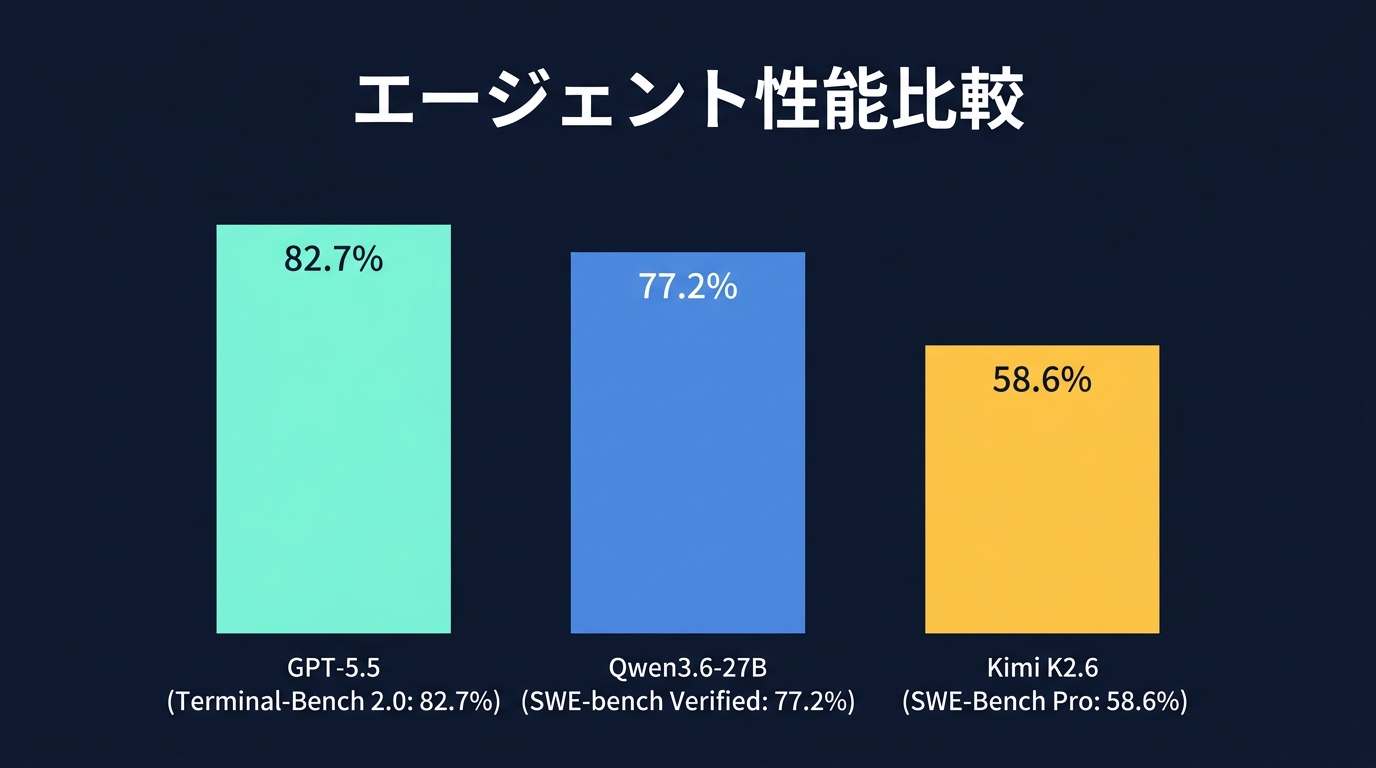
SWE-Bench Proのスコアは58.6%を記録した。単一モデルの正解率を競う時代は終わった。
主戦場は「エージェントとしての持続的推論」と「思考履歴の保持」にシフトしている。開発者はプロンプトを投げるだけの設計から脱却する。
エージェント特化型モデルの動向
最新の動向からAI開発のトレンドが変化している。異なるアプローチでエージェント性能の限界を突破した。
GPT-5.5の自律実行能力
GPT-5.5は複雑なタスクの自律実行に特化している。コーディングやデータ分析において、複数のツールをまたいで作業を完結させる能力が向上した。
前世代と同等のレイテンシを維持し、知能レベルを引き上げている。消費トークン数も削減され、長時間の自律実行におけるコスト効率が改善された。
ベンチマークではエージェント性能の高さが示されている。Terminal-Bench 2.0で82.7%、BrowseCompで84.4%を記録した。
サイバーセキュリティのCyberGymでも81.8%を記録した。マルチパートなタスクを計画し、自律的に実行する能力が数字に表れている。
開発者目線で見る「思考履歴の保持」
一人の開発者としてこれらの動向を見る。アプリ設計の前提が覆る変化だ。
思考履歴の保持が変えるコンテキスト管理
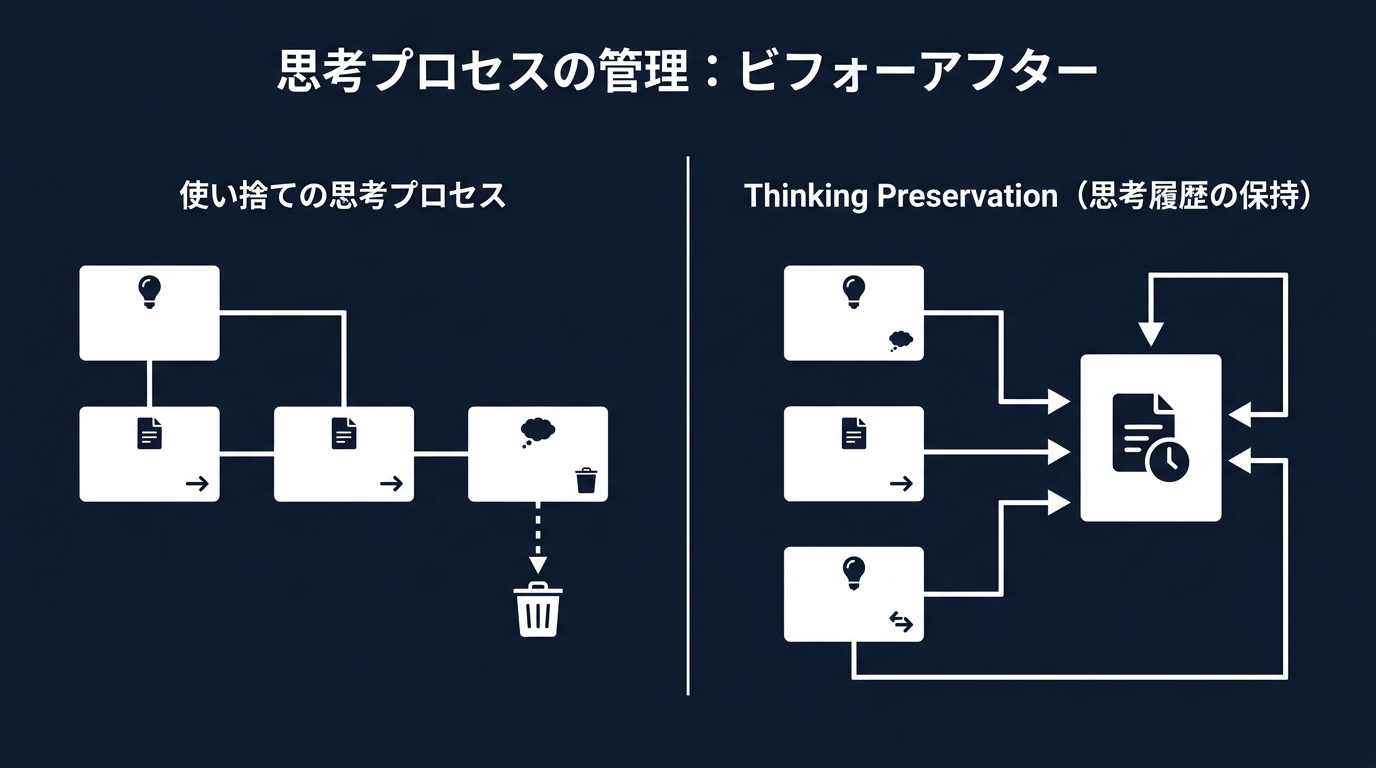
LLMはターンごとに推論プロセスを生成し、破棄していた。エージェントが複雑なバグ修正を行う際、同じ問題の分析をやり直す無駄が発生していた。
過去の思考トレースを保持すれば、前回の推論の続きから思考を再開できる。長時間の自律タスクにおけるトークン消費の削減と、精度の向上を同時に実現する。
毎回ゼロから思考させるのではなく、思考の「状態」を持たせるアーキテクチャだ。APIのパラメータで思考の保持を有効にするだけで機能する。
しんたろー:
Claude Codeで長時間のデバッグをさせると、同じミスを繰り返すことがある。思考履歴をネイティブで保持してくれるなら、無駄な再推論が減ってAPI代も浮きそうで気になる。
巨大モデルと実務性能
SWE-Bench Proのスコアが58.6%である事実は、現在のアーキテクチャにおける単一モデルのエージェント性能を示唆している。
ここから先は、モデル単体の性能向上よりも、エージェントフレームワークの実装力が問われる。エラー時のリカバリー、ツールの選択、そして「思考の持続性」をシステムに組み込む。
ベンチマークの数字だけを追いかけても、実務で使えるエージェントは作れない。持続的なコンテキスト管理と、タスクのルーティングが勝負の分かれ目になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
次世代エージェント開発における実務への影響
進化を踏まえて、開発現場への影響を整理する。APIの向き先を変えるだけでは、最新モデルの真価は引き出せない。
思考トレースの管理
アプリ側にLLMの思考トレースを管理する仕組みが必要になる。ユーザーへの応答テキストだけでなく、モデルが生成した推論プロセスもデータベースに保存する。
次のターンでプロンプトを構築する際、過去の思考トレースをコンテキストとして注入する。これに対応できない古いアーキテクチャのアプリは、推論コストと精度の両面で競争力を失う。
ステートレスなAPI呼び出しから、ステートフルなエージェントセッションへの移行が必須だ。思考の履歴を効率的にキャッシュし、必要な部分だけを引き出す。
タスク分解とルーティングの最適化
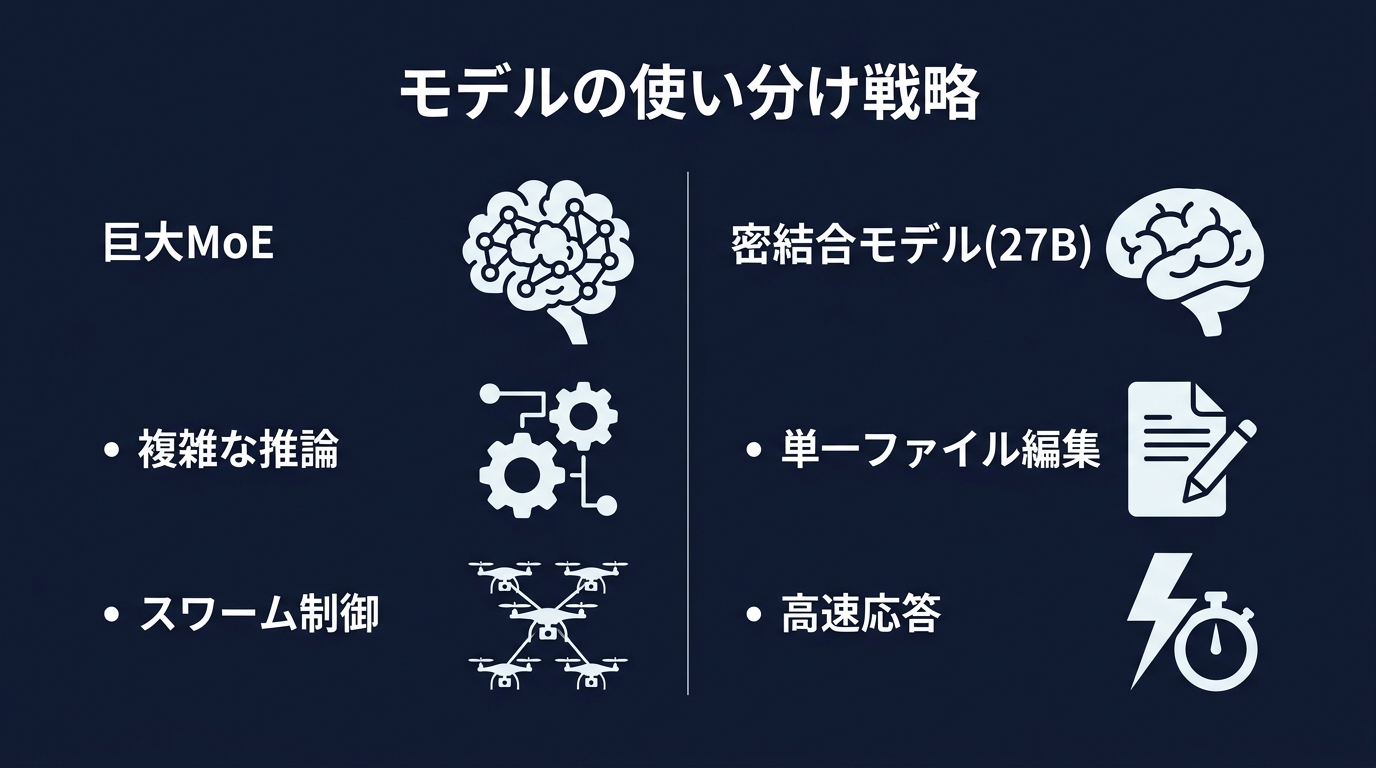
複雑なタスクを、単一のプロンプトで解決しようとするアプローチは捨てる。ユーザーの入力を受け取ったら、まず「計画エージェント」がタスクを複数のサブタスクに分解する。
それぞれのサブタスクを、最適なモデルにルーティングする。高知能モデルに計画を立てさせ、軽量モデルに実作業をさせる。
マルチモデル・マルチエージェント構成が、標準的な開発パターンになる。エージェント間の通信プロトコルや、状態の同期メカニズムの設計が、開発者の仕事になる。
自律実行を前提としたエラーハンドリング
エージェントが自律的に長時間稼働するようになると、エラーハンドリングの考え方が変わる。システムがクラッシュしないことよりも、エージェントがエラーから自力で回復できるかが重要だ。
実行結果の検証ステップを組み込み、失敗した場合はその結果を思考コンテキストに含めて再試行させる。最新のモデルは自らの作業をチェックし、曖昧さをナビゲートする能力を持つ。
開発者は、エージェントが迷子にならないためのガードレールと、タイムアウト処理を実装する。完全に放置するのではなく、要所で人間の承認を求める設計も検討する。
エージェントが無限ループに入ってAPI課金が爆発するのは避けたい。思考履歴を保持するなら、同じ推論を繰り返していないか監視するリミッターの実装は必須になる。
よくある質問
Q1: エージェント開発において、モデルのサイズは重要か?
現在は「エージェントとしての振る舞い」を最適化したモデルが、高い成果を出している。開発者はモデルのパラメータ数よりも、SWE-Bench等のエージェント特化型ベンチマークや、コンテキスト管理機能の有無を重視する。
Q2: 思考履歴の保持(Thinking Preservation)とは具体的に何をする機能か?
LLMが推論を行う際、通常は現在のターンのみで思考プロセスが完結し、過去の思考は破棄される。思考履歴の保持は、過去の思考トレースを保持し、次のターンで再利用可能にする機能だ。これにより、エージェントが同じ問題を何度も再推論する無駄を省き、複雑なタスクを継続的に実行する際の精度向上とトークンコストの削減を同時に実現する。
Q3: 複数のサブエージェントを協調させるメリットは何か?
単一のモデルに複雑なタスクを全て任せると、コンテキストウィンドウの圧迫や推論の破綻が起きやすくなる。タスクを細分化し、専門エージェントに割り当てることで、各エージェントの精度が向上する。また、タスクの難易度に応じて、高コストな巨大モデルと低コストな軽量モデルを使い分けることで、システム全体のコストを最適化できる。
まとめ
AIの進化は「単体での賢さ」から「持続的な思考とエージェント群の協調」というフェーズに移行した。思考履歴を管理し、複数のモデルを適材適所で使い分けるアーキテクチャへの対応が、今後の開発を左右する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
