
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AI開発のフェーズは次の次元へ移行した
AI開発のフェーズが変わった。
モデルの精度向上やプロンプトの微調整で喜ぶ時代は終わった。
今、最前線で議論されているのは「非決定論的なシステムをいかに制御するか」だ。
数十億人規模のインフラを支える企業は、監視とロールバックを自動化している。
複数のAIエージェントが飛び交う開発現場では、仕様の推測ズレが起きる。
AIに振り回されて開発速度が低下する事態を防ぐ。
単なるバグ修正から脱却し、システム全体を制御する運用基盤を構築する。
ニュースの概要:巨大インフラから個人開発まで共通する課題
大規模なシステムの運用において、設定変更の安全なロールアウトは課題だ。
最新のインフラ運用動向では、カナリアリリースと段階的な展開が徹底されている。
ヘルスチェックと監視シグナルを組み合わせ、リグレッションを早期に検知する。
インシデントの振り返りは、人を責めるのではなくシステムを改善するために行われる。
データとAIを活用してアラートのノイズを減らし、問題発生時の二分探索を高速化する。
これは運用改善だ。
確率的に動くシステムを安全に制御するための、基盤構築だ。
巨大テック企業は、AIを「監視する側」と「監視される側」の両方に組み込んでいる。

リアルタイム音声AIパイプラインの運用現場からも、知見が報告されている。
AIを「正しい答えを返す存在」として扱うと、失敗する。
個別の誤認識を直しても、別の変更で壊れる。
問題の傾向が絶えず変化する。
前に直したはずの箇所が、関係ないアップデートで再びバグる。
AIは「推論エンジン」だ。
入力に対して最も確からしい出力を確率的に生成している。
出力を観測し、検証し、修正する前提でシステムを設計する。
最終出力だけを見てプロンプトを調整しても、解決にはならない。
どこで間違えたのかを追跡する仕組みが、改善ループを回す。
複数のAIエージェントが稼働する開発環境でも、問題が起きている。
開発者Aのエージェントと、開発者Bのエージェントが、同じAPIに対して異なるインターフェースを推測する。
コードベースを個別に読み込み、孤立した環境でコードを生成する。
組み合わせた瞬間にシステムが崩壊する。
エージェントの数が増えるほど、この統合コストは指数関数的に悪化する。
各エージェントのコンテキストはセッション単位で途切れる。
これに対する解決策として、エージェント間で仕様を同期する仕組みが注目されている。
人間がドキュメントを書くのではない。
エージェント自身が仕様を読み、コードを書き、仕様を更新する。
この「生きた仕様」の共有こそが、複数エージェント時代の開発パラダイムだ。
一部のツールでは、コマンド一つでサーバーから最新の仕様を取得し、変更を同期する機能が実装されている。
AIがプロジェクトの全体像を把握し、矛盾のないコードを生成する。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線の解説:非決定論的システムとの戦い方
決定論的システムから、非決定論的システムへの移行。
これが今のAI開発で起きている地殻変動だ。
従来のソフトウェアは、同じ入力に対して同じ出力を返す。
バグがあれば原因を特定し、コードを修正する。
しかしAIシステムは違う。
本質的に確率的であり、非決定論的だ。
同じプロンプトを投げても、毎回微妙に違う答えが返ってくる。
これを従来の感覚で「バグ」として扱うと、モグラ叩きになる。
問題を構造的に捉えて改善を回す仕組みが必要だ。
観測する。検出する。分類する。改善する。再観測する。
このループを回し続けることで、システム全体の品質は安定する。
ここで重要なのが「中間状態の保存」だ。
最終的な出力だけを見ていても、どこで間違えたのかはわからない。
各ステージの中間状態をすべて記録する。
これにより、どのレイヤーで問題が起きたのかを追跡できる。
* 入力データの生ログ: ユーザーが何を送信したか
* 前処理の結果: ノイズ除去やフォーマット変換後の状態
* AIモデルの生出力: パース前の生のJSONやテキスト
* 後処理の結果: アプリケーション側で補正をかけた最終データ
これらのデータポイントを押さえることで、「原因の切り分け」が可能になる。
最終出力だけ見てプロンプトをいじるのは効率が悪い。
AIの非決定論的挙動は、様々な形でシステムを破壊する。
JSONフォーマットの崩れ。
予期せぬキーの追加。
勝手なデータ型の変換。
これらはプロンプトエンジニアリングだけでは防げない。
出力が壊れることを前提に、バリデーションとフォールバックの仕組みを張り巡らせる。
システム全体を「AIの気まぐれを吸収する緩衝材」として設計する。
しんたろー:
Claude Codeで開発していると、「中間状態が見えない恐怖」に直面する。
APIのレスポンスがどこでパース失敗したのか、ログがないと追えない。
エラーが出てからプロンプトをいじるのは、時間のロスだと感じる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
複数エージェント時代の仕様同期パラダイム
複数エージェントの連携問題。
Claude Codeのような自律型エージェントを使えば、一人で何人分ものコードが書ける。
しかし、エージェントはプロジェクト全体の「最新の意図」を把握しているわけではない。
コードベースから自分なりに推測して実装を進める。
この「推測」が曲者だ。
認証APIのレスポンスをあるエージェントはキャメルケースで実装し、別のエージェントはスネークケースで呼び出す。
人間が書いたドキュメントは、コードの変更に追従できず腐る。
READMEが最新である保証はない。
エージェントごとに異なる「脳内仕様」を持っている状態だ。
フロントエンド担当のエージェントと、バックエンド担当のエージェント。
両者が同時に動くと、データの受け渡しで矛盾が生じる。
片方がGraphQLを想定し、もう片方がREST APIを想定する。
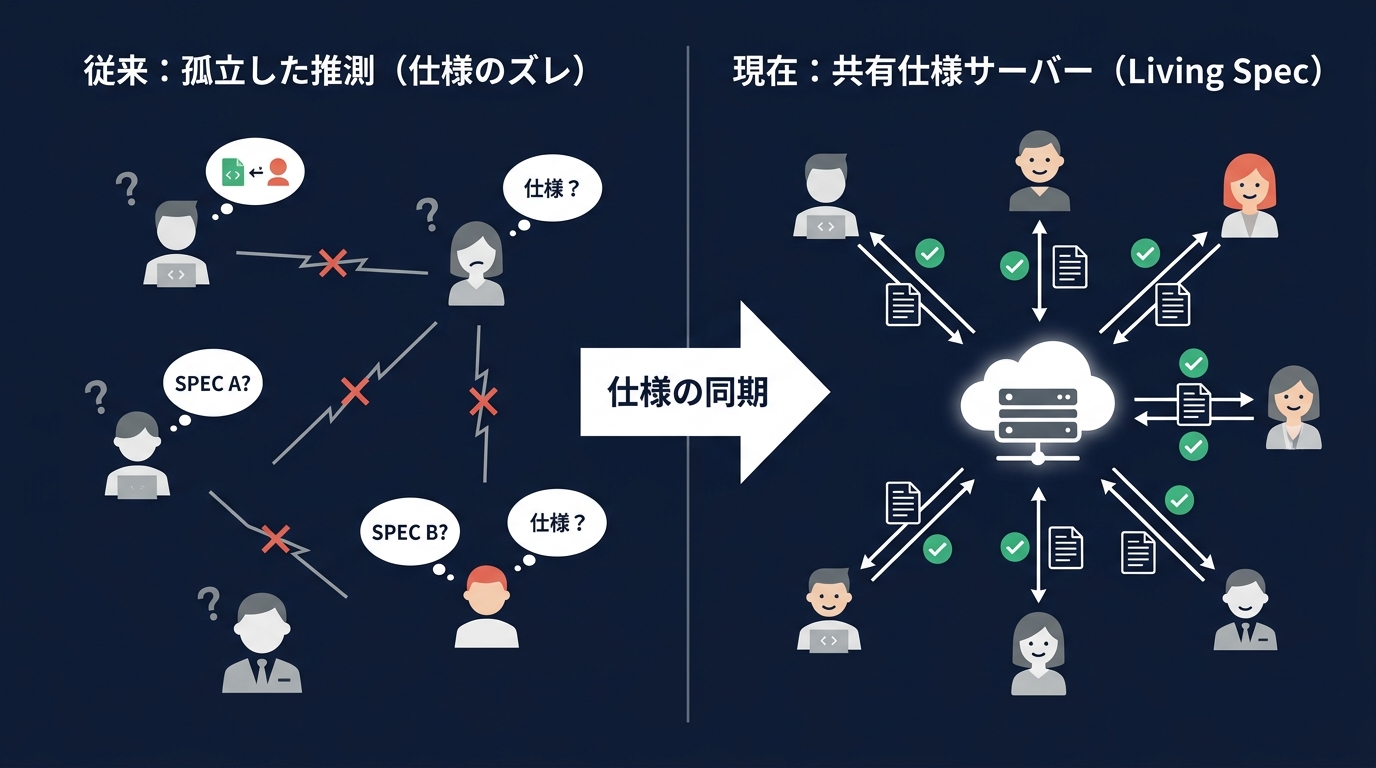
解決策は、サーバー同期による「生きた仕様」の共有だ。
エージェントがコーディングを始める前に、最新の仕様をプルする。
仕様に準拠してコードを書く。
インターフェースを変更したら、エージェント自身に仕様書を更新させる。
そしてサーバーに同期する。
このルールをプロンプトに1行仕込むだけで、エージェントの挙動は変わる。
人間が管理するのではなく、AIに仕様を管理させる。
これが仕様駆動開発の形だ。
孤立した推測を排除し、共有された事実に基づいて開発を進める。
非決定論的なシステムを制御するには、決定論的な仕様の同期メカニズムが不可欠だ。
エージェントに自由を与えすぎると、プロジェクトはカオスに陥る。
強力な制約と、単一の真実の源泉(Single Source of Truth)を用意することが、AIチーム開発の条件になる。
複数エージェントの推測ズレは、笑えない問題だ。
一人でClaude Codeを回していても、昨日のセッションと今日のセッションで前提が変わってバグることがある。
仕様の同期ツールは、環境に導入したい仕組みだ。
実務への影響:明日から現場で何をすべきか
開発への影響を考える。
AIの出力を無条件で信用するのをやめる。
AIは間違える。推測を外す。勝手に仕様を変える。
それを前提とした防御的なアーキテクチャを組む。
まずは、パイプラインの中間状態を可視化する。
ストレージコストをケチってログを消すのは避けるべき判断だ。
原因特定にかかる開発者の時間は、コストに直結する。
すべてを永続保存する必要はない。
直近数日分や、信頼度スコアが低いデータだけをサンプリングして残す。
* 信頼度スコアによるフィルタリング: AIの自信がない出力だけを保存する
* ガードレールの発火ログ: NGワードや形式エラーに引っかかったものを記録する
* 変更率の監視: 入力と出力でデータが大きく変質したものを検知する
* 処理時間のトラッキング: 特定のプロンプトで異常に時間がかかっていないか監視する
中間状態がないと、AIがなぜその回答を出したのか追跡できない。
場当たり的なプロンプト修正を繰り返し、開発コストが跳ね上がる。
ログ基盤の構築は、AI機能の実装よりも優先するタスクだ。
次に、エージェント間の仕様同期の仕組みを取り入れる。
チーム開発はもちろん、1人開発でもセッション間のコンテキスト維持に効果がある。
共有仕様サーバーのようなツールは、試す価値がある。
エージェントのシステムプロンプトに「必ず仕様を読んでから実装しろ」と指示する。
変更があったらドキュメントも更新させ、コミットに含める。
このワークフローを強制することで、コードとドキュメントの乖離を構造的に防ぐことができる。
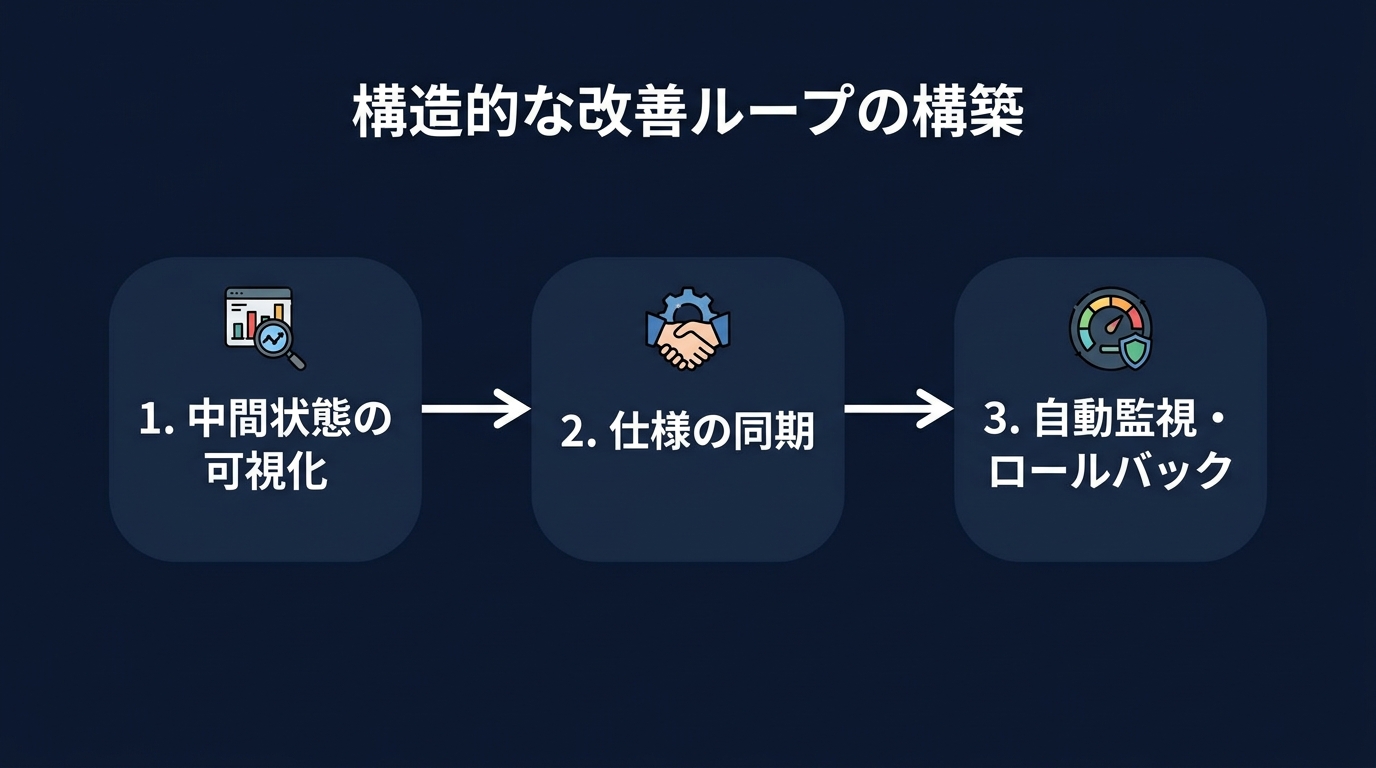
自動化された監視とロールバックの仕組みを構築する。
カナリアリリースや段階的ロールアウトは、巨大インフラだけのものではない。
AI機能のアップデートは、リグレッションのリスクを伴う。
一部のユーザーでテストし、エラーレートや監視シグナルに異常があれば切り戻す。
トラフィックの1%だけを新しいモデルに流し、安全を確認してから徐々に広げる。
この判断を人間に委ねない。
データとAIを活用してアラートを精査し、自動でロールバックする仕組みを作る。
非決定論的なシステムと付き合うには、壊れることを前提とした運用基盤が必須だ。
コードを書く時間よりも、システムを観測し、制御する仕組み作りに時間を投資する。
これが次世代の開発者のスタンダードになる。
AIにコードを書かせること自体は、差別化にならない。
AIが書いたコードと生成したデータを、いかに安全に運用し続けるかが勝負の分かれ目だ。
ログのサンプリング保存は、個人開発でも必須のテクニックだ。
クラウドのストレージ代は月数百円であり、バグ調査で休日を潰すより効率的だ。
壊れる前提で組むことは、AI時代のエンジニアの基本マインドになりつつある。
FAQ
AIパイプラインで中間状態を保存するとストレージコストが増大しませんか?
コストよりも原因特定にかかる時間を優先する。すべてのログを永続保存する必要はない。直近の数日分や、信頼度スコアが低いデータのみをサンプリングして保存する運用が現実的だ。中間状態がないと、AIがなぜその回答を出したのかを追跡できず、場当たり的なプロンプト修正を繰り返すことになる。結果として、開発コストが跳ね上がり、プロジェクトが頓挫する。
共有仕様の導入は、ドキュメントの更新忘れを防げますか?
人間が手動で更新する限り防げない。重要なのは、エージェントがコードを書く際に仕様を参照し、必要に応じて仕様を更新するというワークフローを強制することだ。エージェントのプロンプトに仕様更新のルールを自動追記し、コミット時に仕様書も更新させる仕組みを組み込む。これにより、ドキュメントとコードの乖離を構造的に防ぐことができる。AIに管理させるのが有効だ。
カナリアリリースのような仕組みは個人開発でも必要ですか?
AI機能を組み込んでいるなら必要だ。プロンプトやモデルの変更は、予想外の副作用を引き起こす確率が高い。全ユーザーに一斉展開してシステムがダウンすれば、復旧に多大な時間を奪われる。最初は特定のテストアカウントのみで新機能を動かし、エラーログやレスポンスタイムを監視する。異常があれば一瞬で旧バージョンに戻せるフラグ管理を実装しておく。
非決定論的なAIを制御する仕組み化がすべて
非決定論的なAIを制御するには、徹底した仕組み化と運用基盤の構築しかない。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
