
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
推論の常識が変化。マイクロサービスの終焉と「モデル統合」
推論の高速化はモデルの軽量化か、GPUの強化が定石だった。Metaが発表したSilverTorchは、その常識を覆す。
レコメンデーションシステムを構成するマイクロサービスを、一つの巨大なニューラルネットワークに統合した。これをIndex as Modelと呼ぶ。
何百万ものコンテンツから、ユーザーに最適な数千個を絞り込む。この処理を100ミリ秒以内で完結させる。
個別の最適化で限界を感じる開発者にとって、これは一つの回答になる。このアーキテクチャの転換が開発を変える。
しんたろー:
100ミリ秒の壁は開発者がぶつかるラインだ。マイクロサービスの改善ではなく、モデルへの統合で解決する発想。コードを書く時代から、巨大な計算グラフを設計する時代へのシフトを感じる。

SilverTorchが描く「Index as Model」という新パラダイム
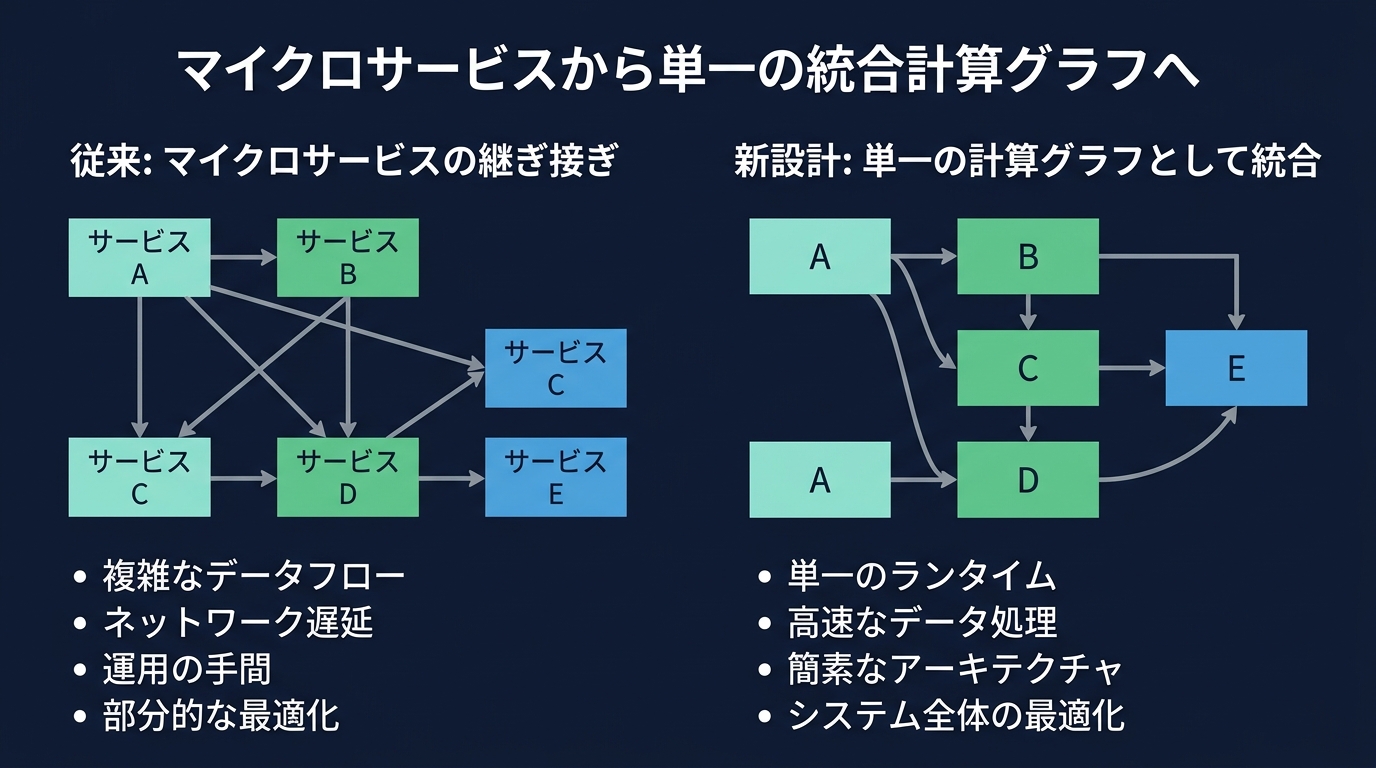
これまでのレコメンデーションシステムは「継ぎ接ぎ」だった。ユーザーの興味をベクトル化するサービス、インデックスサービス、スコアリングサービスが複雑に組み合わさる。
この設計には構造的な限界がある。サービス間の通信オーバーヘッドや、デプロイサイクルの不一致だ。モデルの複雑さを上げるとレイテンシが爆発する。
SilverTorchは、独立していたインデックスやフィルタリングの機能を、モデル内部のテンソルとして定義した。リクエストは一つの計算グラフとして処理される。
検索、フィルタリング、スコアリング、再ランキングが、一つのニューラルネットワークの中で完結する。この統合により、評価候補を増やしながら100ミリ秒の制約を守る。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
知識蒸留とハードウェア最適化の「垂直統合」
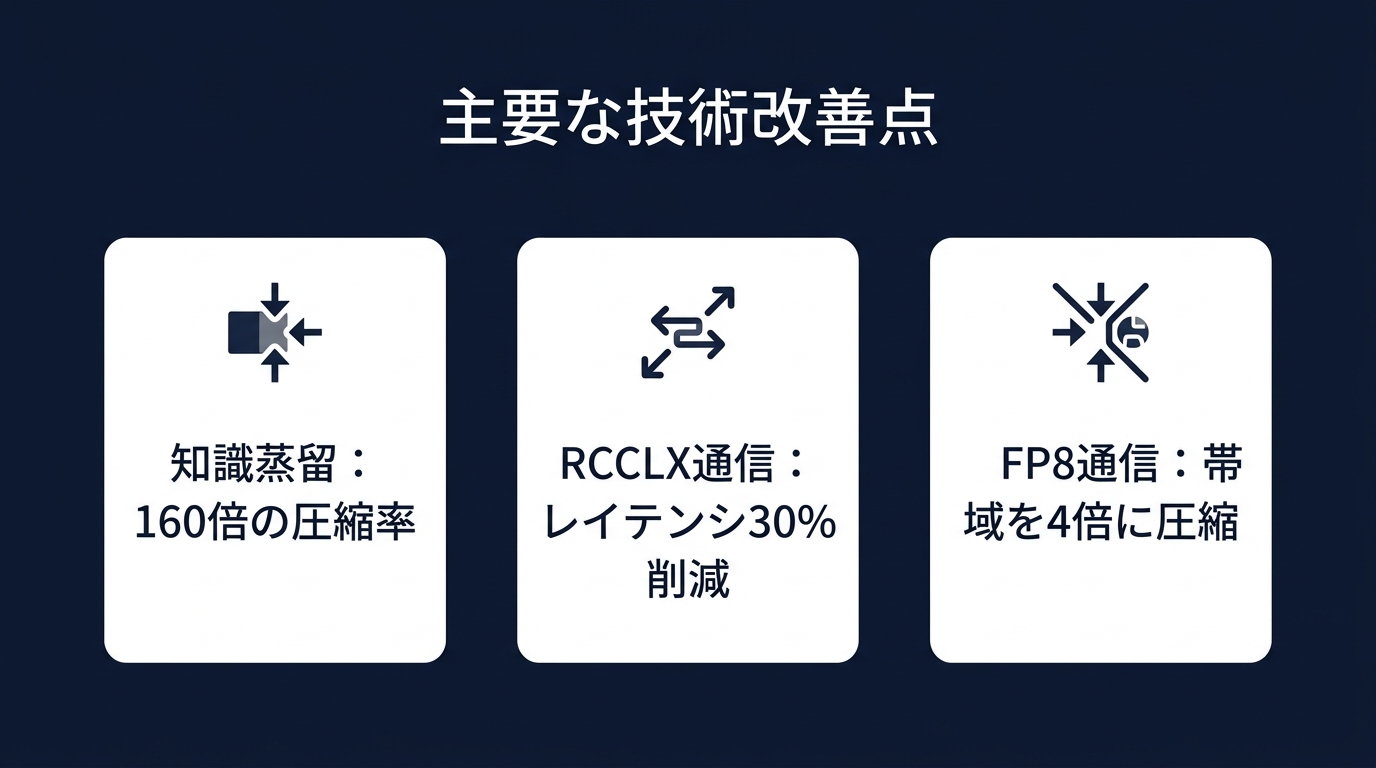
巨大な統合モデルは、ソフトウェアとハードウェアの両面から最適化されている。モデルの圧縮には知識蒸留が使われる。
教師モデルが持つ知能を、小さな学生モデルに継承させる。教師モデルが出力する確率分布の「ゆらぎ」まで学習させる。これにより、160倍の圧縮率を実現している。
ハードウェア層の通信ボトルネックも解消された。RCCLXという通信ライブラリが、GPU間の通信であるAllReduceのレイテンシを最大30%削減する。
FP8通信の導入も行われた。計算は高精度で行い、通信時だけデータを4分の1に圧縮する。帯域の限界を回避しつつ、数値的な安定性を保つ。
160倍の圧縮という数字が気になる。知識蒸留の本質は「情報の密度」を上げることにある。Claude Codeでリファクタリングする時、冗長なロジックを削ぎ落として本質的な計算グラフだけを残す作業と似ている。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
開発者に求められる「モデル中心設計」へのシフト
開発スタイルは大きな転換点を迎えている。これまではAPIを叩いてデータを加工する「糊付け」のエンジニアリングが主流だった。
これからは推論パイプライン全体を一つの計算グラフとして定義する能力が問われる。マイクロサービスの境界線で悩む時間は減り、テンソル操作としてロジックを記述する時間が増える。
通信効率、計算グラフの統合、量子化耐性が次世代のエンジニアの共通言語になる。SNSの投稿生成や解析を、個別のプロンプトで繋ぐのではなく、一つの推論フローとして最適化する。
Claude Codeを使って、複雑なロジックを一つの効率的なコードベースに統合していくプロセスは、この「統合」のミニチュア版だ。
マイクロサービスの管理は開発者にとって負荷が高い。ネットワークエラー、バージョンの不一致、リソースの無駄。それらを全部「モデル」の中に閉じ込めることができれば、パフォーマンスが向上する。
これからの推論基盤で知っておくべきこと
以下の3点は推論基盤を考える上で欠かせない。
第一に、通信は最大の敵だ。GPUの計算速度が上がるほど、データ移動が相対的に遅くなる。DDA(Direct Data Access)のような、ハードウェアを直接叩く通信アルゴリズムが推論の勝敗を分ける。
第二に、「精度」と「効率」はトレードオフではない。知識蒸留を適切に使えば、軽量なモデルでも巨大なモデルの振る舞いを模倣できる。いかに知能を凝縮させるかに知恵を絞る。
第三に、量子化のダイナミックな活用だ。常にフル精度で動かす必要はない。通信時はFP8、計算時はFP32と、状況に応じてデータの精度を使い分ける設計がインフラコストを下げる。
FAQ
Q1: 「Index as Model」は小規模なプロダクトでも導入すべきか?
検索対象が数百万件を超え、かつ100ミリ秒以下のレイテンシが収益に直結するような、大規模システム向けの解決策だ。小規模なプロダクトでは、マイクロサービス構成の方が保守性やデプロイの柔軟性が高い。既存の構成が物理的な限界に達した時に検討する。
Q2: 知識蒸留を行う際、精度低下を最小限に抑えるコツは?
教師モデルが出力する確率分布(Soft Target)を最大限に活用することだ。特に温度スケーリング(Temperature Scaling)の調整が重要になる。教師モデルが持つクラス間の類似性という知識まで学生モデルに伝えることで、高い性能を再現できる。
Q3: FP8通信は精度にどの程度影響するのか?
計算自体はFP32などの高精度で行い、通信時のみFP8に量子化する手法なら、精度への影響は軽微だ。このアプローチにより、数値的な安定性を維持したまま、通信帯域を最大4倍に圧縮できる。モデルの重みが極端に小さい場合や、量子化に弱い構造では精度が落ちることもある。
まとめ:境界線が消える時代の開発
MetaのSilverTorchは、ソフトウェアとハードウェア、モデルとシステムの境界線が消えていく未来を示す。マイクロサービスという箱の中にAIを閉じ込めるのではなく、システムそのものをAI化する。
Claude Codeでコードを書きながら、この「統合」を意識する。バラバラの機能を繋ぐのではなく、一つの洗練された「知能」としてプロダクトを構成する。
継ぎ接ぎの開発を卒業する時が来ている。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】最強LLM比較7選|GPT-5.5・Claude・Qwenの使い分けを徹底解説

Gemini 3.5でAI開発はどう変わるか。ReasoningBankによる失敗の学習と自律エージェント構築を徹底解説

なぜClaude Codeが開発効率を変えるのか。AIによるインフラ管理のガイド

Gemini OmniとFlashでAI開発はどう変わるか。Google新戦略を徹底解説

【2026年版】AIエージェント開発の設計原則10選|ツール定義と評価の最適化手法
