
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIエージェントは「指示する」より「設計する」ものになった
AIコーディングエージェントの使い方が変化している。
「自然言語でお願いする」フェーズは終了した。今は権限を絞り、入出力を構造化し、トークンを削ぎ落とすという三位一体の最適化が、開発効率を左右する。
Codexがローカル環境でどのフォルダにアクセスできるかを制御する仕組みを持ち、プロンプトの丁寧語を削るだけでAIの稼働時間が倍以上変わり、出力をJSON形式で定義するだけで再現性が向上する。
これは「AIを上手く使うコツ」の話ではない。エンジニアリングの話だ。

Codexのローカル操作、何が起きているのか
「フォルダ」という境界線
OpenAI Codexのデスクトップアプリは、プロジェクトを「コンピュータ上の特定フォルダ」に紐付けて動作する。
この設計が重要だ。Codexはデフォルトではコンピュータ全体にアクセスできない。指定したフォルダの中だけで動作する。
構成はシンプルだ。「Codex」という名前の親フォルダを作り、その中にプロジェクトごとのサブフォルダを置く。Codexに触らせたいファイルはそこに入れる。触らせたくないものは入れない。
権限は3段階で考える
Codexを起動してプロジェクトを開くと、入力欄の下に「Work locally」という表示が出る。「このフォルダの中だけで、選択したツールだけを使って動く」という意味だ。
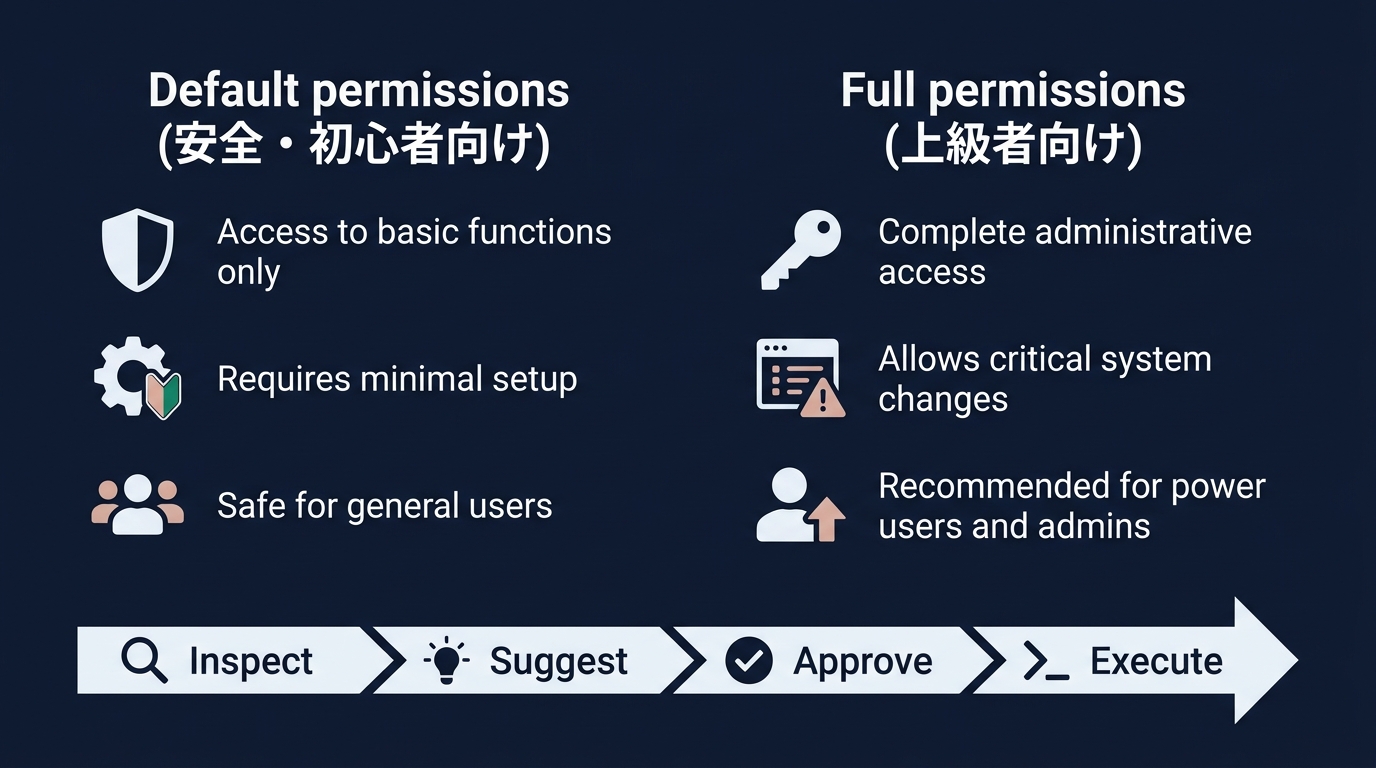
権限の設定はDefault permissionsとFull permissionsの2択がある。
- Default permissions: 初心者向け。Codexの行動が制限される。
- Full permissions: 上級者向け。Codexの行動範囲が広がる。リスクも伴う。
公式の推奨は明確だ。「何をやっているか完全に理解できていて、管理者に確認済みの場合のみFull permissionsを使え」。
最初のプロンプトは「調査から始めろ」
Codexを初めて使う場合、公式が推奨する最初のプロンプトがある。
「このフォルダを調べて、何があるか教えてほしい。安全に完了できる小さなタスクを1つ提案してほしい。変更を加える前に承認を待ってほしい。」
この構造が示しているのは、AIエージェントとの信頼構築は段階的であるということだ。Inspect(調査)→ Suggest(提案)→ Approve(承認)→ Execute(実行)というフローを守る。
タスクの難易度に応じてモデルの推論レベルも調整する。簡単なタスクはデフォルトモデル。複雑なタスクは推論を強化する。
トークンの話:丁寧語は電気代だった
ここからが興味深い。日本語でAIに指示を出すとき、「こんにちは」だけで3〜4トークン消費する。英語の「Hello」は1トークンだ。
日本語は「分かち書き」がないため、AIのトークナイザーが文章をどこで区切るか判断しにくい。「今日は」が「きょうは」なのか「こんにちは」なのか、文脈から判断するためにリソースを使う。
丁寧語・敬語・独り言を削るだけで、Claude Codeの5時間利用ウィンドウが1時間半から3時間半以上に延びるというデータがある。
世界中のユーザーが「ありがとう」「お願いします」とAIに返事をしている。その電気代は年間数千万ドル規模に達するという試算もある。
これは感情の話ではない。インフラコストの話だ。
再現性の話:プロンプトは「関数」だ
もう一つの軸が「再現性」だ。
「SNSで見た最強プロンプトをコピペしたのに、全然同じ結果にならない」という経験は一般的だ。これはAIが確率的なモデルだからだ。同じ入力でも、毎回同じ出力が保証されない。
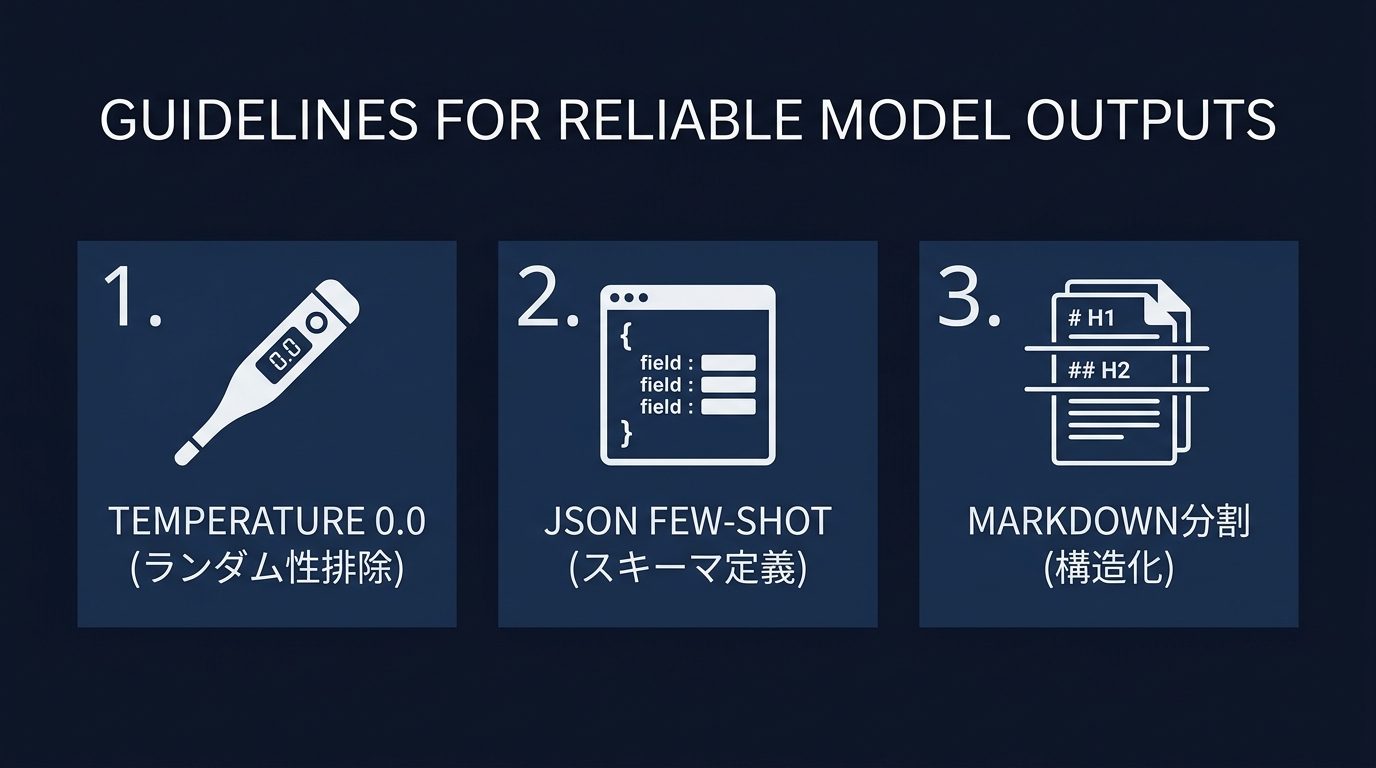
再現性を高めるための設計は3つに集約される。
- Temperatureを0.0に設定する: 出力のランダム性を最小化する
- Few-shot exampleを構造化データで提示する: 期待する入出力のペアをJSON形式で例示する
- Markdownタグでセクションを区切る: AIが指示の構造を正確に認識できるようにする
プロンプトを「お願い文」ではなく「関数定義」として設計する。入力と出力のスキーマを明確にする。そうするとAIの確率的な挙動が「制御可能なシステム」に変わる。
しんたろー:
これを読んで「あ、やっぱりそういうことか」と思った。Claude Codeで毎日コードを書いていると、丁寧に話しかけた日と、コマンドのように短く指示した日で、体感が違う。気のせいではなかった。
「了解やれ」で黙々とこなしてくれるなら、それで十分だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線で読み解く「三位一体の最適化」
安全・効率・再現性は別々の話じゃない
今回の話を整理すると、3つのレイヤーが存在する。
- Codexの権限管理: 「どのファイルに触れるか」を制御する安全レイヤー
- トークン効率化: 「どれだけ無駄なく指示するか」を最適化する効率レイヤー
- 構造化プロンプト: 「どれだけ安定して期待通りの出力を得るか」を設計する再現性レイヤー
これらは独立した話に見えて、実は同じ思想から来ている。
AIエージェントを「チャット相手」として扱うのをやめる。「特定のフォルダを操作する関数」として扱う。
関数には入力と出力がある。スコープがある。副作用を最小化する設計がある。それがCodexの権限管理であり、構造化プロンプトであり、トークン最適化だ。
Claude Codeとの比較で見えること
Claude Codeも同じ思想で動いている。
Claude Codeはプロジェクトのルートディレクトリを起点に動く。勝手にそれ以外の場所を触りに行くことはない。ファイルを変更する前に確認を求めてくる。これはCodexの「Default permissions + Inspect first」と構造的に同じだ。
Claude CodeでThreadPostの開発をしていると、指示が曖昧なときほどAIが「確認を求めてくる」頻度が上がる。これは無駄なやり取りに見えて、実はAIが不確実性を表明しているサインだ。
指示を構造化すると確認の頻度が下がる。タスクが一発で完了する割合が上がる。JSON形式で期待する出力を例示した指示と「いい感じにやって」という指示では、結果の質が異なる。
「丁寧語を削る」の本当の意味
「AIに丁寧に話しかけるのをやめよう」という話は、感情論ではない。
AIは確率的なモデルだ。「お願いします」という単語が含まれていても、AIはそこから「感謝されている」とは解釈しない。ただ、その単語を処理するためにトークンを消費し、推論リソースを使う。
「了解やれ」と「ありがとうございます、それではお願いします」は、AIにとって同じ意味だ。ただしコストが違う。
これを理解すると、プロンプト設計の視点が変わる。「何を伝えるか」だけでなく「何を省くか」が設計の核になる。
日本語の場合、特に注意が必要な点がある。
- 「今日は〜しましょう」の「今日は」: 「きょうは」か「こんにちは」か曖昧。削る。
- 「〜のファイルの中の〜の部分を」: ファイル名と見出し名を直接指定すれば、AIはgrepでそこだけ読む。
- 「〜してください」「〜お願いします」: 動詞だけでいい。「実装」「修正」「削除」。
プロンプトを「関数」として設計する実践
再現性の設計で最も効果が高いのはFew-shot exampleのJSON化だ。
「いい感じに要約して」ではなく、「以下のJSON形式で出力せよ。入力例と出力例を示す。」と書く。
具体的には、入力テキストと期待する出力のペアを2〜3セット提示する。出力のフィールド名、データ型、値の形式まで例示する。そうするとAIは「期待されるスキーマ」を正確に把握し、フォーマット崩れが減少する。
Temperature 0.0の設定も組み合わせる。これだけで出力のブレが減る。GPT-4系のモデルでは0.0でも完全に決定論的にはならないが、それでも「再現性を高めるための第一歩」としては効果が高い。
ThreadPostの開発で、AIへの指示を「関数定義」として書くようにしてから、「昨日と違う出力が来た」という事故が減った。Temperatureの設定は固定しておく。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響:今日から変えられること
権限管理:最小権限から始める
Codexを使い始めるなら、Default permissionsから始めること。
Full permissionsは「AIが何をするか完全に把握できている」状態でのみ使う。初回タスクは必ず「調査→提案→承認→実行」の順で進める。
Claude Codeも同じだ。「このファイルを変更してもいいか?」という確認が来たとき、「はい」を押す前に何が変わるかを確認する。これを習慣にするだけで、意図しないファイル変更による事故が減少する。
具体的なフォルダ管理の方針:
- プロジェクトごとにフォルダを分ける: AIに触らせる範囲を明確に定義する
- 機密ファイルはAIのスコープ外に置く: 環境変数ファイル、認証情報は別フォルダに
- 変更前にGitでコミットしておく: AIが何かやらかしても即座にロールバックできる状態を維持する
トークン効率化:今日から削れるもの
日本語プロンプトで今すぐ削れるもの:
- 「こんにちは」「よろしくお願いします」「ありがとうございます」→ 全削除
- 「〜してください」「〜をお願いします」→ 動詞だけ残す(「実装」「修正」「確認」)
- 「〜の中の〜のところを」→ ファイル名と見出し名を直接指定
- 「いい感じに」「適切に」「うまく」→ 具体的な条件に置き換える
英語で書けるなら英語で書く。 「こんにちは」が3〜4トークンで、「Hello」が1トークンなら、英語の方が効率がいい。DeepLやGeminiで翻訳してからプロンプトに貼る方法も有効だ。
AIが返してくる「考え事・独り言」も削らせる。 「あなたの考え事と独り言は不要。最低限の言葉だけで返せ。」と最初に宣言するだけで、AIの出力トークンも減る。
再現性設計:プロンプトをバージョン管理する
プロンプトを「一回使い捨て」で書くのをやめる。
再現性の高いプロンプトはコードと同じようにバージョン管理する。 どのモデルで、どのTemperatureで、どのFew-shot exampleで動いたかを記録する。
最低限やるべきことのリスト:
- Temperatureを0.0に固定する: 出力のランダム性を最小化
- 出力形式をJSON等の構造化データで例示する: 「いい感じに」を排除
- Markdownタグでセクションを区切る: AIが指示の構造を正確に認識できるようにする
- プロンプトをテキストファイルで保存する: 再利用・改善のサイクルを回す
- 「動いた」「動かなかった」を記録する: 主観ではなく事実で評価する
「プロンプトのバージョン管理」は重要だ。「昨日まで動いてたのに今日動かない」を「なんでだろう」で終わらせず、コードと同じように管理する。
FAQ
Q1. AIエージェントに「丁寧な言葉」を使わないと精度が落ちませんか?
結論:精度は落ちない。むしろ上がる。
AIにとって「丁寧語」や「独り言」はノイズだ。トークンを浪費するだけでなく、指示の核心をぼやかす。AIは確率的なモデルであり、感情を理解しているわけではない。
「了解やれ」と「ありがとうございます、それではお願いします」はAIにとって同じ意味だ。ただしコストが違う。
「丁寧語を省く」はエンジニアリング上の最適化であって、AIへの態度の問題ではない。 推論リソースをタスク遂行に集中させるための合理的な設計だ。
実際に、AIへの指示の冒頭に「敬語・丁寧語は不要。考え事・独り言は不要。最低限の言葉で返せ。」と宣言するだけで、利用可能なトークンウィンドウが倍以上に延びるというデータがある。
Q2. プロンプトの再現性を高めるために、まず何をすべきですか?
2つだけやれ。
① Temperatureを0.0に設定する。 これで出力のランダム性を最小化できる。GPT-4系では0.0でも完全に決定論的にはならないが、再現性向上への効果は大きい。
② 期待する出力形式をJSON等の構造化データで例示する(Few-shot)。 「いい感じに要約して」ではなく、入力と出力のペアを具体的に2〜3セット提示する。出力のフィールド名、データ型、値の形式まで例示する。これだけでフォーマット崩れが劇的に減少する。
加えて、Markdownタグでセクションを区切ることで、AIが指示の構造を正確に認識できるようになる。「### 入力」「### 期待する出力」「### 制約条件」のように区切る。
Q3. Codexなどのローカルエージェントで「Full permissions」を与えるべきタイミングは?
基本的には与えない。与えるなら条件が3つ揃ったときだけだ。
- Default permissionsではタスクが完結しないことが確実な場合
- AIがどのファイルにどのような変更を加えるかを完全に把握できている場合
- 管理者に確認済みの場合(チーム開発の場合)
安全な進め方はInspect(調査)から始めることだ。「このフォルダを調べて、何があるか教えてほしい。変更を加える前に承認を待ってほしい。」という最初のプロンプトで、AIの挙動を観察する。信頼できると判断した段階で、必要最小限の権限を付与する。
Full permissionsは「AIに任せる」ではなく「AIを信頼できる根拠がある」状態でのみ使う。
まとめ:AIエージェントは「設計するもの」になった
権限を絞る。トークンを削る。出力を構造化する。
この3つを組み合わせると、AIエージェントは「確率的にいい感じのことをしてくれる道具」から「制御可能なシステム」に変わる。
「指示出し」から「エンジニアリング」へ。これが今のAIエージェント活用の現在地だ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
