
OpenAIが開催した Parameter Golf の結果が公開された。
16MB という極小のサイズ制限と、H100を8枚 使用し 10分 で学習を終えるという制約だ。
この極限状態で勝敗を分けたのは、人間が書くコードの美しさではない。
AIエージェントを使い倒し、試行錯誤を自動化したか が鍵となった。
開発者の主戦場は「コードを書くこと」から「AIの評価を設計すること」へ移行している。

SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
極限の制約が生んだAI開発の新しい形
コンペには 1,000人以上 が参加し、2,000以上 のサブミッションが提出された。
ルールはモデルの重みと学習コードを 16MB 以内に収め、損失を最小化することだ。
このサイズ制限は、巨大化するLLMトレンドへのアンチテーゼとして機能した。
参加者はオプティマイザのチューニングや量子化、テスト時トレーニングを総動員した。
トップ層は AIエージェント を活用して実験を回している。
AIがコードを書き、AIが結果を分析し、AIが次のパラメータを提案する。
人間は「ループの設計」と「最終的な判断」に専念する。
エージェントの活用で実験コストが下がり、参加のハードルが下がった。
主催者側は「AIが書いたコード」の評価と帰属特定という課題に直面した。
これはソフトウェア開発の未来の縮図だ。
しんたろー:
16MB は昔のフロッピーディスク数枚分だ。
その中にモデルとコードを詰め込むのは魔法のように見える。
勝者が「エージェントを使いこなした者」である事実に時代を感じる。
評価と改善のループを自動化する新概念
エージェントの機能は Brain(考える)、Hands(動く)、Session(覚える) の3層に分離される。
「セッションの外部化」により、AIは永続的な記憶を持つ。
記憶を積み上げるだけではノイズが増える。
そこで Dreaming(ドリーミング) という概念が登場した。
エージェントはセッションの合間に自律的にログを見直す。
「何がうまくいったか」「どこで失敗したか」を言語化し、次の仕事に活かす。
法律AIの事例では、この仕組みによりタスク完了率が 約6倍 に向上した。
セッション内の品質制御には Outcomes(アウトカム) が使われる。
ユーザーが「完成とはこういう状態だ」という ルーブリック(評価基準) を定義する。
エージェントはその基準を満たすまで、自律的に作業と修正を繰り返す。
「評価基準の言語化」がエンジニアのスキルとなる。

Dreaming という名前が気になる。
深夜にコードを書いて朝起きたらバグだらけという経験がある。
AIが寝ている間にログを整理して修正してくれるなら助かる。
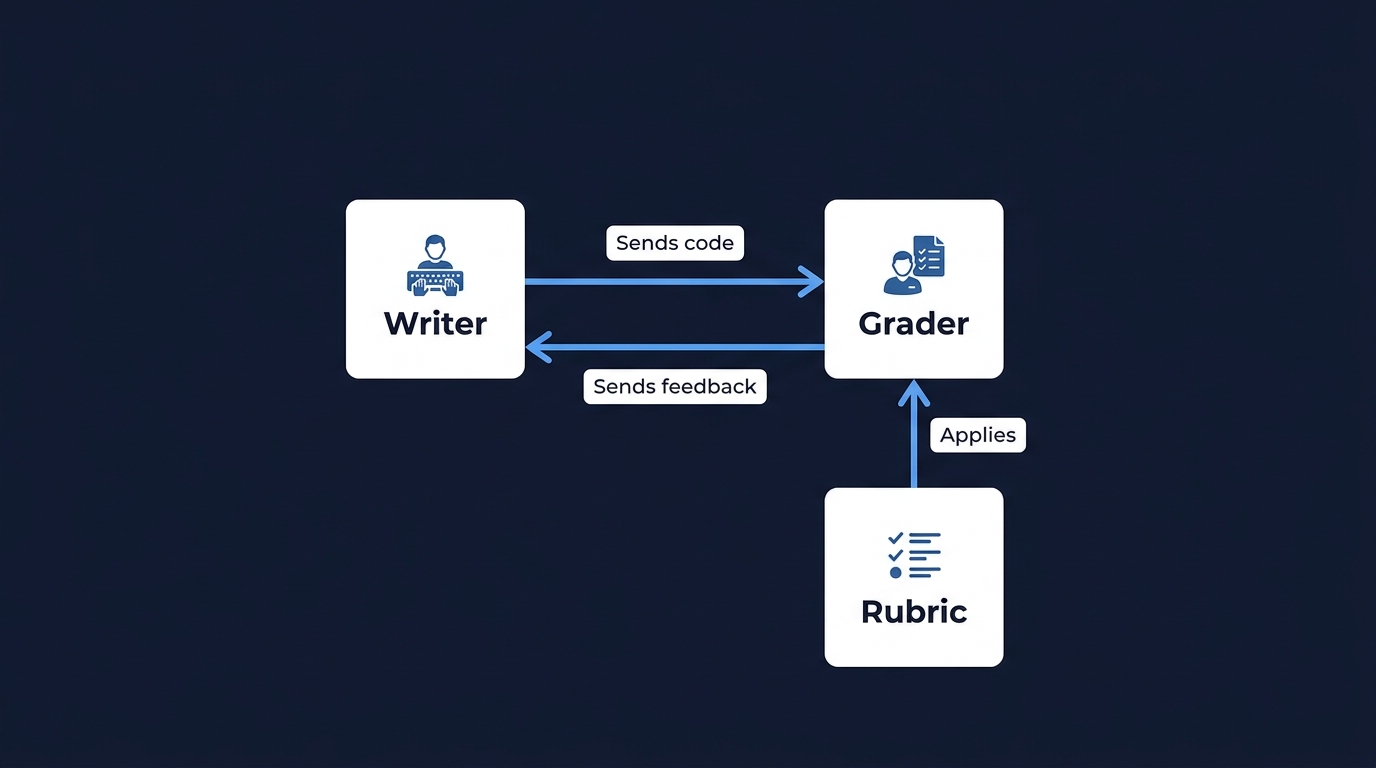
開発者の役割はコード執筆から評価設計へ
AIエージェント内で Writer(執筆者) と Grader(採点者) の役割分担が明確になった。
GraderはWriterとは 完全に別のコンテキストウィンドウ で動く。
自分の書いたコードを自分で評価させると、AIはミスを正当化する。
別の視点から客観的に評価させることで、品質が安定する。
この LLM-as-a-Judge は開発のスタンダードだ。
開発者は「コードをどう書くか」ではなく「どういう基準で採点するか」を設計する。
数学的な推論コンペでも同様の知見がある。
単なる「正解か不正解か」という バイナリ報酬 だけでは学習は進まない。
「考え方のプロセスは正しい」といった 部分点 を与えることで、学習の勾配が安定する。
「部分点の設計」がエンジニアの腕の見せ所だ。
AIが「これで完璧だ」と壊れたコードを出すことがある。
「このテストケースを通るまでやり直せ」という ルーブリック を提示できるかが分かれ道だ。
エンジニアの仕事は「審美眼の言語化」に集約される。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響と具体的なアクションアイテム
「評価設計への移行」は日常的な開発に影響する。
「〜のコードを書いて」という依頼は原始的だ。
「10個のチェックリストをすべてパスするまで試行錯誤を繰り返せ」という指示が基本になる。
以下の3つのポイントを意識する。
第一に、ルーブリックのバイナリ化 だ。
「データが正しく見える」といった曖昧な基準はAIには意味がない。
「CSVに特定のカラムが存在するか」といった、機械的に判定可能なレベルまで基準を落とし込む。
第二に、フィードバックループの多層化 だ。
中間成果物を評価する小さなループをいくつも作る。
複数の回答候補を生成させ、相対的に優れたものを選ばせる設計も有効だ。
第三に、AIエージェントの「睡眠」時間を設計に組み込むこと。
バックグラウンドで過去の失敗から学習するバッチ処理を実装する。
これがシステム全体の精度を向上させる。
未来のエンジニアに求められる市場価値
今後は、モデルのパラメータを調整できるエンジニアよりも、エージェントの評価関数を設計できるエンジニア の価値が上がる。
「良質な学習データ」と「厳格な評価基準」を準備できるかが勝負を分ける。
数学推論のコンペでは、ツール活用が不安定だったという報告もある。
その不安定さを「評価ループ」でカバーするのがアプリケーション開発者の役割だ。
失敗を許容し、その失敗から自動で立ち直るシステムを構築する。
それがAI活用における正解だ。
FAQ
Q1: LLM-as-a-Judgeを導入する際、評価のバイアスをどう防ぐべきか?
評価用LLM(Grader)のプロンプトに、具体的なルーブリック(チェックリスト)を明示する。
「正しく見えるか」ではなく、「CSVに特定のカラムがあるか」といったバイナリ判定可能な基準を定義する。
GraderをWriterとは別のコンテキストウィンドウで動かすことで、客観的な評価が可能になる。
Q2: 強化学習で部分点を与えるメリットは何か?
バイナリ報酬だけでは、不正解のデータが「価値ゼロ」として扱われ、モデルがどこで間違えたかの勾配情報が得られない。
LLMで推論過程を評価し部分点を与えることで、モデルは「推論の方向性は正しい」という中間的なフィードバックを受け取れる。
これにより学習が安定し、試行錯誤の回数を減らしつつ精度を向上させることが可能になる。
Q3: エージェントのツール活用が不安定な場合、どう対処すべきか?
ツール生成が安定しないのは、モデルの事前学習におけるコード比率や指示追従能力の限界であることが多い。
単一の回答に頼らず、多数決投票(Majority Voting)を採用する。
1つの問題に対して回答候補を生成させ、最も頻出する回答を選択するパイプラインを組むことで、個別の生成の不安定さを統計的にカバーできる。
まとめ
OpenAIの Parameter Golf は、16MB という極限状態でもAIエージェントが開発をリードできることを示した。
Anthropicの Dreaming や Outcomes は、エージェントを制御するための「評価設計」の重要性を裏付けている。
開発者は「コードの書き手」から、AIという部下を管理する「評価の設計者」へ変わる。
このシフトを受け入れた者だけが、これからのAI時代を生き残る。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
