
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
冒頭フック
Midjourneyは精度を落としてでも速度とコストを4倍改善した新スタイルリファレンスを投入した。
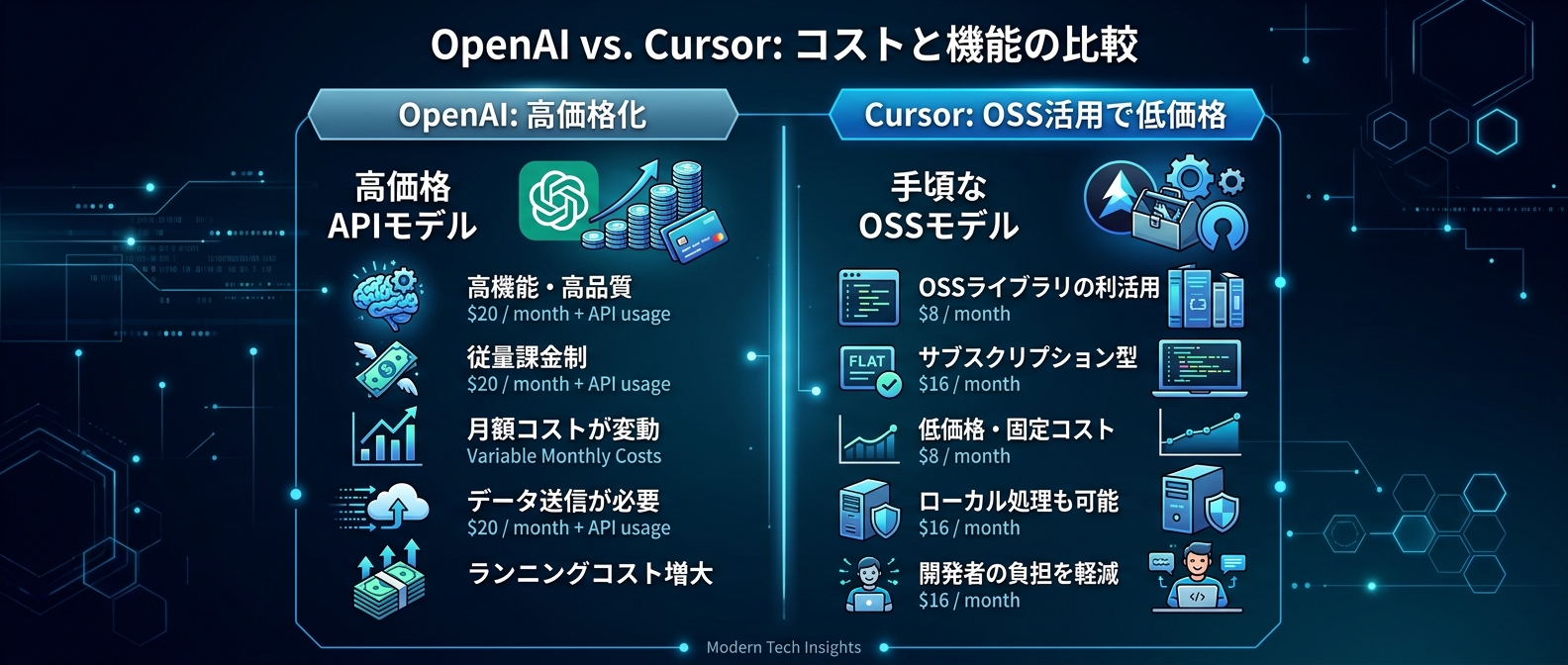
OpenAIは小型モデルの価格を前世代比3倍に設定する強気な姿勢を見せている。
Cursorはオープンソースベースの特化モデルを破格の安さで投入した。
高価なフロンティアモデルに肉薄する性能を叩き出し、プロプライエタリAPIの価格優位性を揺るがしている。
ニュースの概要
MidjourneyがV8 Alphaのアップデートを実施した。
標準プラン以上の全ユーザー向けにリラックスモードが開放された。
注目すべきは新しいスタイルリファレンス機能の実装だ。
以前のバージョンより精度は若干落ちるものの、4倍速く安価に生成できる。
この新バージョンは高解像度を指定するパラメータをサポートしている。
さらにスタイル強度やプロンプトの重み付けなど、他のパラメータともより良く機能するよう最適化された。
これがV8 Alphaのデフォルト設定として採用されている。
旧バージョンを使いたい場合は、プロンプトの末尾にバージョン指定を追加する。
開発チームは現在、V8の次なる大規模な学習ランに取り組んでいる。
デフォルトの美学や一貫性、画像プロンプトの改善を目指している。
目標解像度をデフォルトで2Kに引き上げることも視野に入れている。
数週間後には現在のアルファ版が置き換わる予定だ。

一方でOpenAIは新しい小型モデルのGPT-5.4 miniとnanoをリリースした。
コーディングアシスタントやサブエージェント向けのモデルだ。
GPT-5.4 miniはコーディングベンチマークのSWE-Bench Proで54.4%を記録した。
フルモデルのGPT-5.4が出した57.7%に肉薄している。
コンピュータ操作を測るOSWorld-Verifiedでも72.1%を叩き出した。
フルモデルの75.0%に迫る数値だ。
しかし価格は大幅に引き上げられた。
入力100万トークンあたり0.75ドル、出力4.50ドルに設定されている。
前世代のGPT-5 miniと比較して入力で3倍、出力で2.25倍の値上げとなる。
両モデルとも40万トークンのコンテキストウィンドウをサポートしている。
別の動きとして、Cursorが新しいコーディング特化モデルのComposer 2を投入した。
入力100万トークンあたり0.50ドル、出力1.50ドルという破格の設定だ。
社内ベンチマークでは61.3を記録した。
Claude Opus 4.6の58.2を上回り、GPT-5.4 Thinkingの63.9に迫るスコアだ。
このモデルは中国のオープンソースモデルをベースにファインチューニングされている。
プレトレーニングの約4分の1がベースモデル由来だ。
独自のファインチューニングと継続学習でコーディング性能を極限まで引き上げている。
高価なプロプライエタリAPIを使わなくても、特化型なら同等以上の性能が出せることを示した。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線の解説
この3つの動きから読み取れるのは、明確なパラダイムシフトだ。
すべてのタスクを単一の巨大モデルに投げつけるアーキテクチャは完全に時代遅れになった。
Midjourneyの選択は非常に示唆に富んでいる。
ユーザーは常に「最高画質」や「最高精度」を求めているわけではない。
アイデアの探索段階では、精度よりも生成速度と試行回数が圧倒的に重要になる。
4倍速く安価に生成できる新モデルをデフォルトにしたのは、実務のワークフローを深く理解している証拠だ。
完璧な出力を10秒待たせるより、80点の出力を2秒で返すほうが、結果的にユーザーの満足度は高くなる。
このトレードオフの判断が、プロダクト設計の核心だ。
しんたろー:
毎日Claude Codeで開発してると、ちょっとした変数名の変更に巨大モデルが動くのは無駄だと感じる。
精度が80点でも爆速で返してくるモデルのほうが、開発体験は圧倒的に良いんだよね。
OpenAIの戦略は「小型モデルの高性能化と高価格化」だ。
彼らが推奨するサブエージェント構成は理にかなっている。
巨大モデルが計画立案と最終評価を担当する。
そして並列化可能なタスクを小型モデルに振り分ける。
コードベースの検索や巨大ファイルの走査は、小型モデルで十分だ。
これにより、全体のAPIコストを約3分の1に抑えられると彼らは説明している。
しかし、OpenAIの価格設定には疑問が残る。
性能が上がったとはいえ、小型モデルで前世代の3倍の価格だ。
ここでCursorのアプローチが強烈なカウンターになっている。
彼らはオープンソースの強力なベースモデルを特定タスク向けに鍛え上げた。
結果として、OpenAIの小型モデルよりも安い価格で、フロンティアモデル級のコーディング性能を実現した。
巨大な汎用モデルをゼロから学習させるには数十億ドルの資金が必要だ。
しかし、優秀なオープンソースモデルをファインチューニングするだけなら、はるかに少ないコストで済む。
特定領域に絞れば、汎用モデルを凌駕することすら可能だ。
Cursorの事例は、プロプライエタリAPIの価格優位性が崩れ始めていることを明確に示している。
用途に合わせて最適なモデルを選べる選択肢が爆発的に増えた。
Claude Codeのようなツールを使えば、この恩恵を直接受けられる。
複雑なアーキテクチャ設計は推論能力の高いモデルに任せる。
単純なリファクタリングやテストコードの生成は、安価な特化モデルに回す。
こういう使い分けが、これからのAI開発のスタンダードになる。
特定タスクに特化したモデルは、プロンプトの解釈も早い。
余計な知識を持っていない分、ハルシネーションのリスクも下がる。
ThreadPostのバックエンド処理を組むとき、全部のタスクを最高性能のモデルに投げたらAPI代で破産する。
タスクの難易度を見極めてモデルを切り替えるルーティング処理こそが、今のAI開発のキモだと思う。
AI業界全体が「単一モデルでの最高性能の追求」から焦点を移している。
「実用的なコストパフォーマンスとタスク分割」への移行は止まらない。
この流れを理解していないと、無駄なAPIコストを払い続けることになる。
モデルの進化だけでなく、価格設定の裏にある意図を読み解くことが開発者の競争力になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響
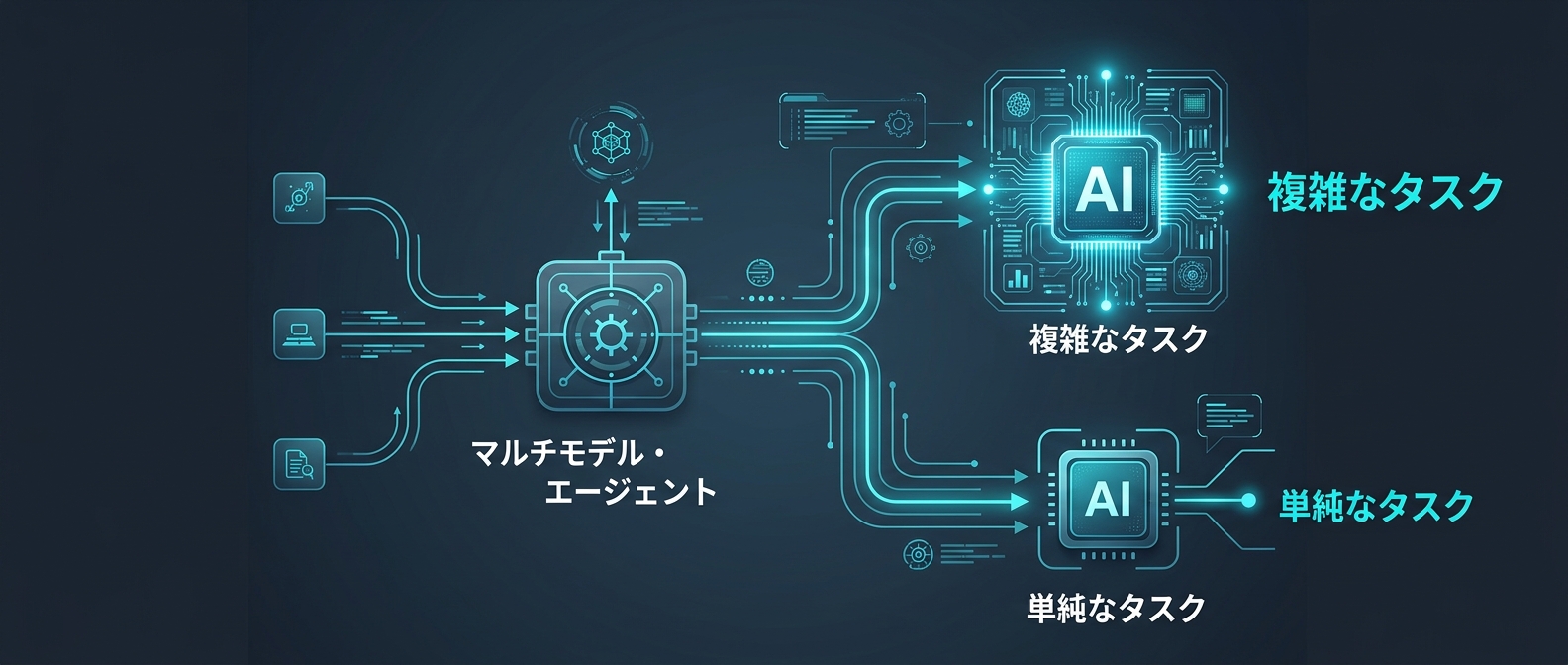
日々の開発への影響は「マルチモデル・エージェントアーキテクチャ」の設計が必須になることだ。
APIにリクエストを投げる前に、そのタスクの難易度を評価する仕組みが必要だ。
システム全体を「計画」「探索」「実行」「評価」のフェーズに分割する。
全体像の設計や複雑なバグの特定は、推論能力の高い高価なモデルに任せる。
ログの解析やドキュメントの抽出は、安価で高速な小型モデルに委譲する。
このサブエージェント化の徹底が、ランニングコストを大幅に下げる。
次に、オープンソースベースの特化モデルの導入検討だ。
汎用的なチャットAIとしては物足りなくても、特定タスクでは驚異的な性能を発揮するモデルが増えている。
コーディング、翻訳、データ整形など、領域を絞れば選択肢は無数にある。
高価なAPIを叩く前に、ローカルや安価なクラウドで動く特化モデルで代替できないか検証する価値がある。
Midjourneyの事例から学べることもある。
ユーザー体験において、処理速度は出力の精度と同じくらい重要だ。
バックグラウンドで動くバッチ処理なら、時間をかけてでも高精度なモデルを使う。
しかし、ユーザーを待たせるリアルタイム処理なら、精度を少し妥協してでも高速なモデルを選ぶ。
このトレードオフを意識したシステム設計が求められる。
AIのレイテンシは、そのままプロダクトの離脱率に直結する。
AIの進化が早すぎて単一のモデルに依存するのはリスクが高すぎる。
いつでも別のモデルに差し替えられるように、プロンプトとビジネスロジックは完全に分離しておかないと痛い目を見る。
Claude Codeのようなエージェント型ツールは、複数のモデルを内部で使い分ける方向に進化していく。
「どのモデルを使うか」ではなく「どうタスクを定義するか」に集中するようになる。
AIへの指示出しの精度が、そのままプロダクトの品質とコストに直結する。
コンテキストウィンドウの管理も見落とせない。
40万トークンが扱えるからといって、無駄な情報を詰め込めばコストは跳ね上がる。
必要な情報だけを抽出し、圧縮して渡す技術が問われる。
ベクトルデータベースやRAGの活用は、コスト最適化の観点からも必須の技術だ。
エラーハンドリングとフォールバック戦略も再考が必要だ。
安価なモデルが失敗したときだけ、高価なモデルに切り替える仕組みを用意する。
これにより、平均的な処理コストを下げつつ、システムの安定性を担保できる。
よくある質問
Q1: GPT-5.4 miniは前のminiモデルと比べてどれくらい高くなったのですか?
GPT-5.4 miniは入力100万トークンあたり0.75ドル、出力4.50ドルに設定されている。
前世代のGPT-5 miniは入力0.25ドル、出力2.00ドルだった。
入力で3倍、出力で2.25倍の大幅な価格引き上げとなっている。
コーディングベンチマークのSWE-Bench Proで54.4%を記録するなど、推論性能がフルモデルに肉薄するレベルまで向上したことが、この強気な値上げの背景にある。
Q2: CursorのComposer 2はGPT-5.4と比べてコストメリットはありますか?
Composer 2は入力100万トークンあたり0.50ドル、出力1.50ドルだ。
GPT-5.4の入力2.50ドル、出力15.00ドルと比較すると圧倒的に安価で、GPT-5.4 miniの入力0.75ドル、出力4.50ドルよりも安い。
社内ベンチマークでは61.3を記録し、高価なフロンティアモデルに匹敵するスコアを叩き出している。
コーディング特化という絞り込みが、コストと性能の両立を実現した。
Q3: Midjourney V8の新しいスタイルリファレンスの特徴は何ですか?
以前のバージョンと比較して、4倍速く安価に画像生成できるのが最大の特徴だ。
精度の面では若干の妥協があるが、試行回数を増やせるメリットが上回る。
高解像度パラメータやスタイル強度など他のパラメータとの相性が大幅に改善された。
実用性とコストパフォーマンスの高さから、V8 Alphaのデフォルト設定として採用されている。
まとめ
AI開発は「最強のモデルを探すゲーム」から「最適なモデルを組み合わせるゲーム」に完全に移行した。
高価なAPIと安価な特化モデルをどう使い分けるか、開発者の設計力がそのままプロダクトの競争力になる。
複数モデルを適材適所で組み合わせる最新のAI開発アーキテクチャについて、ThreadPostで議論しませんか?

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
