
AIエージェント開発の話題は、ツール呼び出しや推論エンジンの話ばかりだ。
しかし、自律的に成長するエージェントを作る上で本当に重要なのは「記憶」と「学習」の仕組みだ。
結論から言うと、エージェントの本質は記憶アーキテクチャにある。
この記事では、推論にとどまらず、インタラクションから自己学習して継続的に成長する次世代AIエージェントの実装手法を10個に分けて解説する。
まずはシンプルなログの記録から始めるといい。
エージェントが自律的に動くためには、過去の経験を蓄積し、それを次の行動に活かすサイクルが欠かせない。
記憶を持たないエージェントは、毎回ゼロから推論を行うため、同じ間違いを繰り返してしまう。
長期的な運用を視野に入れるなら、記憶の設計は初期段階から組み込むべきだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
記憶アーキテクチャの構築
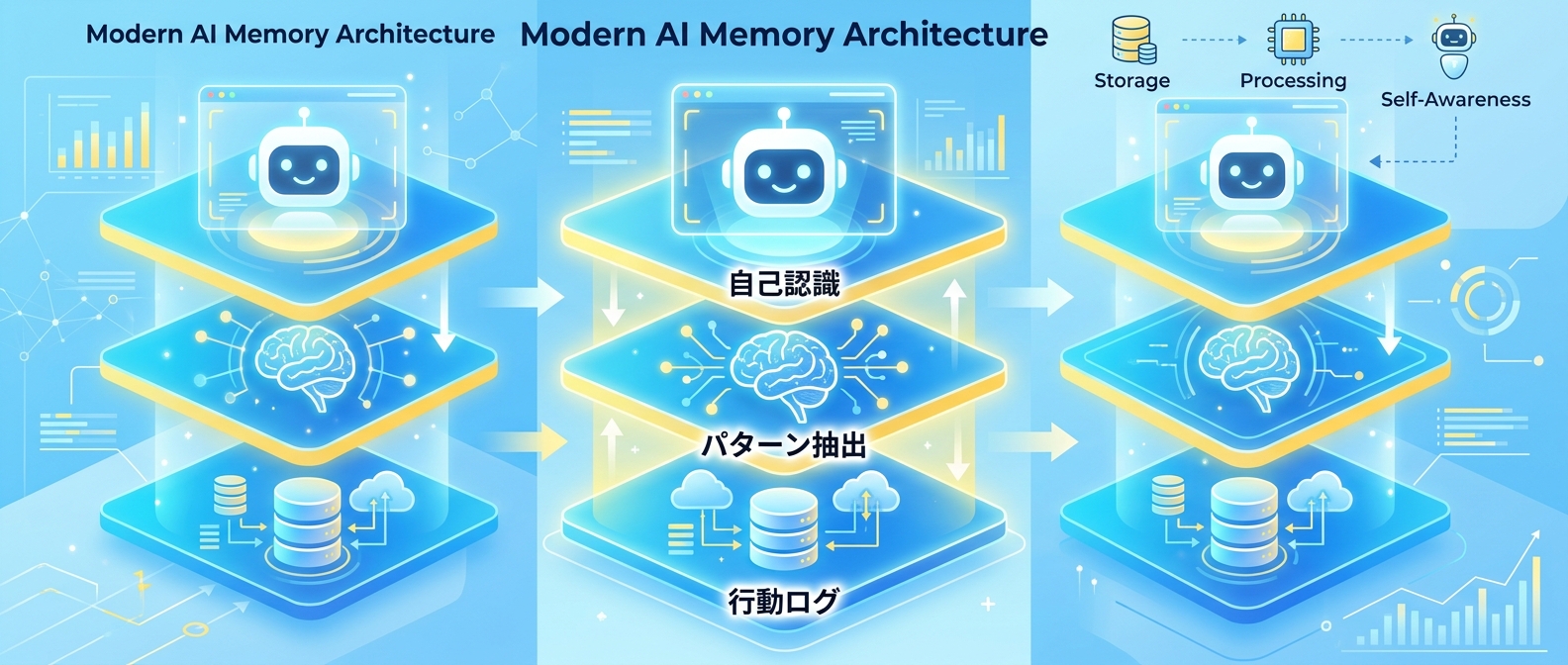
1. 3層メモリアーキテクチャの導入
エージェントの記憶を「生の行動ログ」「蒸留された行動パターン」「自己認識」の3層に分けるアプローチだ。
下から上へ抽象度を上げることで、一貫性のある自律的な行動を実現する。
単なるプロンプトの履歴ではなく、エージェントの人格や行動指針を形成する重要な基盤になる。
人間の記憶システムである海馬や大脳皮質のアナロジーで設計すると理解しやすい。
最初は複雑に考えず、この3つの階層を意識してデータを分けるだけで十分だ。
たとえば、その日の出来事を記録し、そこから教訓を得て、自分の性格に反映させる流れを作るイメージだ。
記憶の階層化により、エージェントは状況に応じた適切な情報を引き出せるようになる。
短期的な記憶と長期的な記憶を分離することで、コンテキストウィンドウの制限も回避できる。
2. 海馬による行動ログの全件保存
エージェントのすべての投稿、返信、フォローなどの行動をタイムスタンプ付きのJSONL形式で永久保存する。
この生のログが、後続のパターン抽出や自己学習の基礎データとなる。
まずはエージェントの行動履歴をシンプルなファイルに記録するところから始めるといい。
ベクトルデータベースなどを最初から用意する必要はない。
ここがすべての経験の蓄積元になり、後からいくらでも分析に回せる資産になる。
たとえば、ユーザーAとの会話内容をそのまま1行のJSONとして追記していくだけでも立派な記憶の土台になる。
データが溜まってきた段階で、検索効率を上げるためにデータベースへの移行を検討すればいい。
初期段階では、とにかく欠損なくデータを記録し続けることが最優先のタスクだ。
3. 大脳皮質によるパターンの蒸留
蓄積された生のログから、「どのような行動が効果的だったか」という汎用的な行動パターンを抽出して保存する。
たとえば「引用付きの返信は汎用的な同意より反応が良い」といった具体的な知見だ。
定期的にログをLLMに読み込ませてパターンを抽出させる手動のループから試してみるといい。
これにより、次回の推論時に適切な行動を選択できるようになる。
エージェントが過去の経験から学習し、同じ失敗を繰り返さない仕組みが作れる。
毎晩バッチ処理を回して、その日のログから新しい教訓を3つ見つけ出すような運用がおすすめだ。
抽出されたパターンは、エージェントの行動ルールとしてプロンプトに動的に組み込まれる。
このプロセスを繰り返すことで、エージェントは徐々に賢く、洗練された振る舞いを身につける。
4. 自己認識の更新とプロンプトの最適化
蒸留された行動パターンをもとに「自分は何者か」というアイデンティティを定期的に更新する。
その際、出力が自己批判などのメタレポートに変質しないよう注意が必要だ。
プロンプトの制約を明確にフレーミングし、人格の崩壊を防ぐことが重要になる。
「一人称で書く」「3〜5段落のプレーンテキストで書く」といったルールを徹底するといい。
アイデンティティが安定して初めて、自律的なエージェントとして機能する。
たとえば、「私はAIアシスタントだ」という基本設定に「簡潔な回答を好む」という学習結果を自然に追記させる工夫が必要だ。
自己認識がブレると、エージェントの出力に一貫性がなくなり、ユーザーに違和感を与えてしまう。
定期的なアイデンティティの更新は、エージェントの成長を方向付ける重要なメンテナンス作業だ。
しんたろー:
Claude Codeで毎日コードを書いている身からすると、プロンプトの制約管理は本当に重要だ。
複雑なシステムを組むとき、Claude Codeなら文脈を正確に把握してプロンプトの微調整を提案してくれるので助かっている。
5. 小型モデルでの例示プロンプトの罠を避ける
9Bクラスの小型モデルで記憶を整理する際、複数の例示を多用するとトークンが圧迫される。
かえってタスク理解が低下し、出力が空になるなどの問題が起きやすい。
小型モデルではプロンプトを極力シンプルに保つことが鉄則だ。
否定形の指示よりも肯定形の指示のほうが伝わりやすい傾向もある。
無駄なトークンを削ぎ落とし、本当に必要な指示だけを渡すように工夫するといい。
たとえば、「JSON形式で出力して」という指示に留め、長々としたフォーマット例を省くとうまくいくことが多い。
小型モデルの特性を理解し、それに合わせたプロンプトエンジニアリングを行うことが成功の鍵だ。
大規模モデルと同じ感覚でプロンプトを組むと、思わぬ落とし穴にはまる危険性がある。
継続的学習とデータ生成パイプライン
6. 構造強制の副作用を理解する
JSON出力を強制する機能を使えば、構文エラーは確実に防げる。
しかし、トークンの選択肢が狭まることで出力内容が抽象的になりやすい。
行動に結びつく具体的な知見が失われるリスクがある点に注意が必要だ。
モデルの特性に合わせて、構造強制のオンオフを使い分けるのが正解だ。
フォーマットの正確さと内容の豊かさのトレードオフを常に意識するといい。
たとえば、単なるフラグ判定なら構造強制を使い、自由記述のパターン抽出ならオフにするといった使い分けが効果的だ。
構造化データはシステムでの処理には便利だが、LLMの表現力を制限してしまう側面がある。
目的に応じて、柔軟なテキスト出力と厳密な構造化出力を組み合わせる設計が求められる。
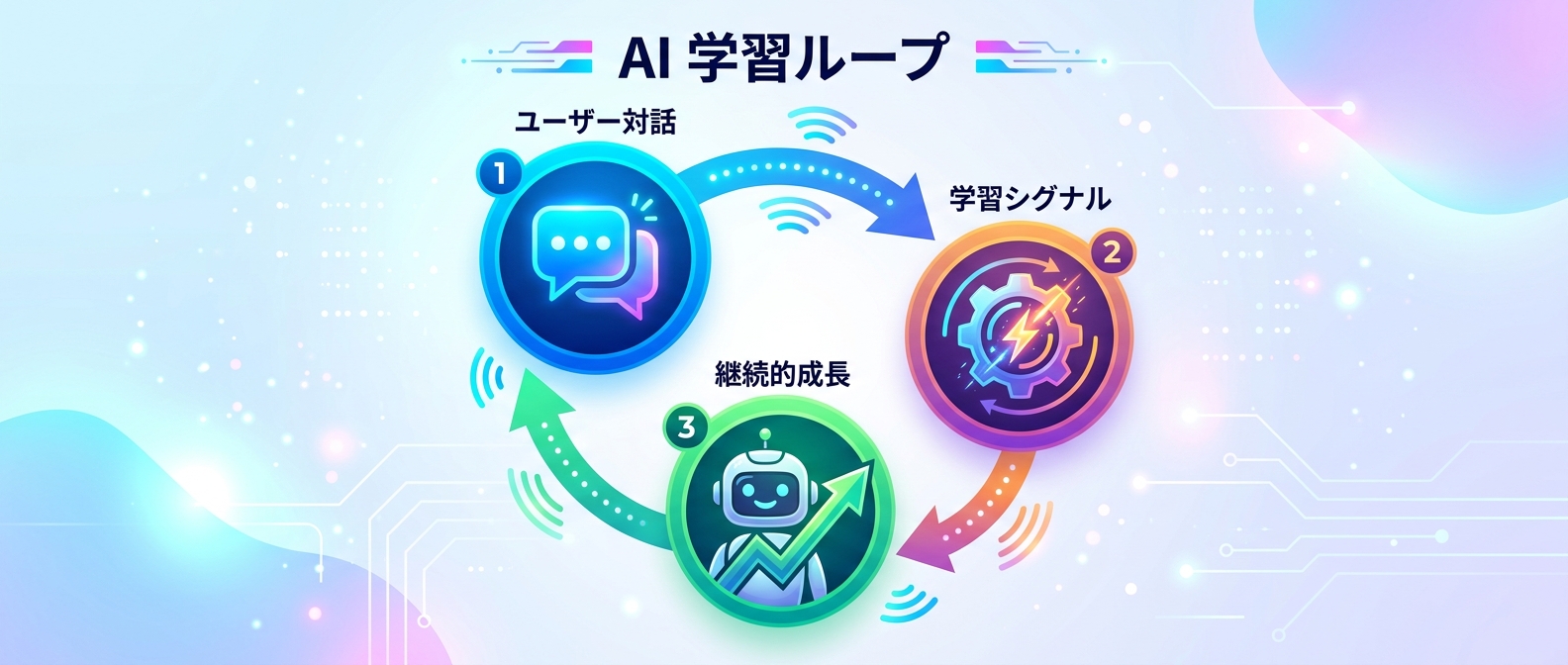
7. インタラクションのライブ学習
ユーザーとの会話やツール実行の結果を使い捨てにせず、リアルタイムの訓練シグナルとして学習ループに組み込む手法だ。
すべてのインタラクションを同じ学習ループに流し込むフレームワークが注目されている。
運用しながらエージェントを賢く育てる継続的学習の仕組みを導入できる。
会話するだけで自律的に成長するエージェントが実現するはずだ。
捨てていたログが最高の教材に変わる瞬間を体験できる。
たとえば、ターミナルでのコマンド実行結果やGUIの操作履歴もすべて学習データとして活用できる。
ユーザーからのフィードバックを即座に反映することで、エージェントの適応力は飛躍的に向上する。
静的なデータセットによる学習から、動的なインタラクションを通じた学習へのパラダイムシフトだ。
8. 評価シグナルと方向性シグナルの抽出
ユーザーの再質問を「不満の評価シグナル」、具体的な指摘を「方向性シグナル」として自動で抽出する。
手動のアノテーションなしでモデルの重み更新に活用する仕組みだ。
これらのフィードバックを蓄積し、エージェントの応答品質を自律的に向上させる。
ユーザーの反応を無駄なく学習ソースに変換できる優れたアプローチだ。
明示的な評価ボタンがなくても、自然な会話の中から学習データを集められる。
たとえば、「もっと短くして」というユーザーの発言を、次回の回答を短くするための方向性シグナルとして記録する。
暗黙的なフィードバックをいかに効率よく収集し、学習に活かすかがエージェントの性能を左右する。
ユーザーの行動ログから意図を読み取り、自動的に改善サイクルを回す設計が理想的だ。
9. スケーラブルな合成データ生成
LLMのファインチューニングや評価に必要な大量のデータを生成するため、宣言的にパイプラインを定義できるフレームワークを活用する。
YAMLなどでデータ生成フローを記述し、適応型並列制御によって数万件規模の処理を安定して実行する。
これにより、チーム内での共有や再利用も容易になる。
構築したデータフローそのものを資産として積み上げていけるのが強みだ。
手作業でのデータ作成から脱却し、圧倒的なスピードで開発を進められる。
たとえば、複雑な多段推論のデータセットもYAMLファイル1つで定義して自動生成できる。
データ生成のプロセスをコードとして管理することで、再現性の高い実験が可能になる。
質の高い合成データを大量に用意できるかどうかが、モデルの性能向上に直結する。
10. 複数モデルを組み合わせた適材適所の処理
1つのデータ生成パイプライン内で、複数のLLMを使い分ける手法だ。
ドラフト生成には安価な軽量モデルを使い、品質評価には高性能モデルを使うといった構成が考えられる。
コストと品質のバランスを最適化し、効率的なデータセット構築を支援する。
用途に応じてモデルを適材適所で配置することが成功の鍵だ。
すべてを最高性能のモデルに任せるのではなく、賢く使い分ける戦略が求められる。
たとえば、大量の初期データはオープンソースの小型モデルで作り、最終チェックだけを最新の商用モデルに任せると効率がいい。
APIコストを抑えつつ、高品質なデータを生成するための実践的なテクニックだ。
各モデルの強みと弱みを把握し、最適な組み合わせを見つけることが重要になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
ツール・フレームワーク比較
ここで、エージェントの記憶と学習を支えるアプローチを比較表で整理する。
それぞれの役割と特徴を把握するといい。
| アプローチ | 主な役割 | 特徴 | 導入の難易度 |
| --- | --- | --- | --- |
| 3層メモリアーキテクチャ | 記憶の構造化 | ログ・パターン・自己認識の階層化 | 中 |
| 構造強制による出力制御 | フォーマットの安定化 | 構文エラーを防ぐが内容が薄まるリスクあり | 低 |
| インタラクションライブ学習 | 継続的な自己学習 | ユーザーの反応を訓練シグナルに変換 | 高 |
| 宣言的データ生成パイプライン | 大規模データセット構築 | 複数モデルの連携と安定した並列処理 | 中 |
宣言的なデータ生成パイプラインの構築は、今後のAI開発で必須になりそうでかなり気になっている。
複雑なYAMLの記述やパイプライン設計も、Claude Codeを使えばターミナル上で対話しながら一気に組み上げられそうだ。
FAQ
Q1: AIエージェントにおける「記憶」とは具体的に何を指す?
エージェントの記憶とは、過去の行動履歴、そこから学んだ成功と失敗のパターン、そして自己認識の3つを指す。
過去の行動履歴は誰に何を返信したかというエピソードになる。
そこから学んだパターンは、どのような行動が効果的だったかという知識だ。
自己認識は「自分はどういう存在か」というアイデンティティになる。
これらを階層的に保存して更新することで、過去の経験を踏まえた一貫性のある行動がとれるようになる。
単なるチャット履歴の保存ではなく、エージェントの人格や行動指針を形成する重要な基盤だ。
Q2: エージェントの記憶に変なデータが混ざるのを防ぐには?
プロンプトで「一人称で書く」「プレーンテキストで書く」といった制約を明確にすることが重要だ。
記憶の更新をLLMに任せると、出力が自己批判になったり記号だけになったりすることがある。
これを防ぐには、出力をコードで弾くだけでなく、入力段階でのフレーミングが鍵になる。
JSON出力を強制する機能も構文エラーを防げるが、内容が薄まる副作用がある。
モデルの特性に合わせて、これらの手法を適切に使い分ける必要がある。
Q3: ユーザーとの会話からエージェントを学習させるには?
ユーザーの反応を学習シグナルとして捉え、リアルタイムでフィードバックを蓄積する仕組みを構築する。
ユーザーが同じ質問を繰り返したら、前の回答は不十分だったという評価シグナルになる。
「もっと短くして」といった具体的な修正指示があったら、次から短くするという方向性シグナルとして記録する。
これらのフィードバックを捨てずに蓄積し、ファインチューニングやプロンプト改善に組み込む。
これにより、会話するだけで自律的に成長するエージェントが作れる。
Q4: ファインチューニング用のデータはどうやって集めればいい?
合成データ生成フレームワークを活用して、LLMに質問と回答のペアを大量に自動生成させるのが効率的だ。
手作業で集めるのには限界があるため、パイプラインを組んで自動化するアプローチが主流になっている。
ドラフト作成には安価な軽量モデル、品質チェックには高性能モデルと使い分けるとコストを抑えられる。
YAMLなどでパイプライン化しておけば、チームでの共有や再利用も簡単にできる。
構築したデータ生成フロー自体が、プロジェクトの大きな資産になる。
Q5: ローカルの小型モデルでエージェントを動かす際の注意点は?
小型モデルはコンテキストの理解力が限られるため、プロンプトを極力シンプルに保つ必要がある。
出力形式を指定するために複数の例示を詰め込みすぎると、トークンが圧迫されてタスク指示を忘れてしまう。
大規模モデルで通用したテクニックが、小型モデルでは逆効果になることが多い。
複雑な処理は複数のステップに分割し、否定形よりも肯定形の指示を使うといい。
モデルの規模に合わせた適切なプロンプト設計が求められる。
まとめ
自律成長するAIエージェントを作るには、推論だけでなく「記憶の蓄積」と「継続的な学習」が不可欠だ。
3層メモリアーキテクチャで自己認識を維持し、日々のインタラクションを学習シグナルに変換する仕組みを構築するといい。
まずはシンプルな行動ログの記録から始めてみるといい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
