
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
巨大な単一モデルの時代が終わる。分散と協調が作る新しいAIインフラ
AI開発の常識が変わる。
これまで「巨大なGPUクラスタで1つの巨大モデルを同期学習する」手法が主流だった。
Google DeepMindが発表したDecoupled DiLoCoは、その前提を覆す。
Moonshot AIは最大300エージェントを並列実行できるオープンウェイトモデルを公開した。
ローカルで動く強力なMoEモデルの推論手法も確立されている。
AIは「単一の巨大な脳」から「分散された自律エージェントの群れ」へと移行する。
これは開発者のアーキテクチャ設計を根本から変える動きだ。
止まらない学習と300の自律エージェント。最新AIが示す分散化の全貌
複数の技術動向から「計算リソースとタスクの徹底的な分散化」というトレンドが浮かび上がる。
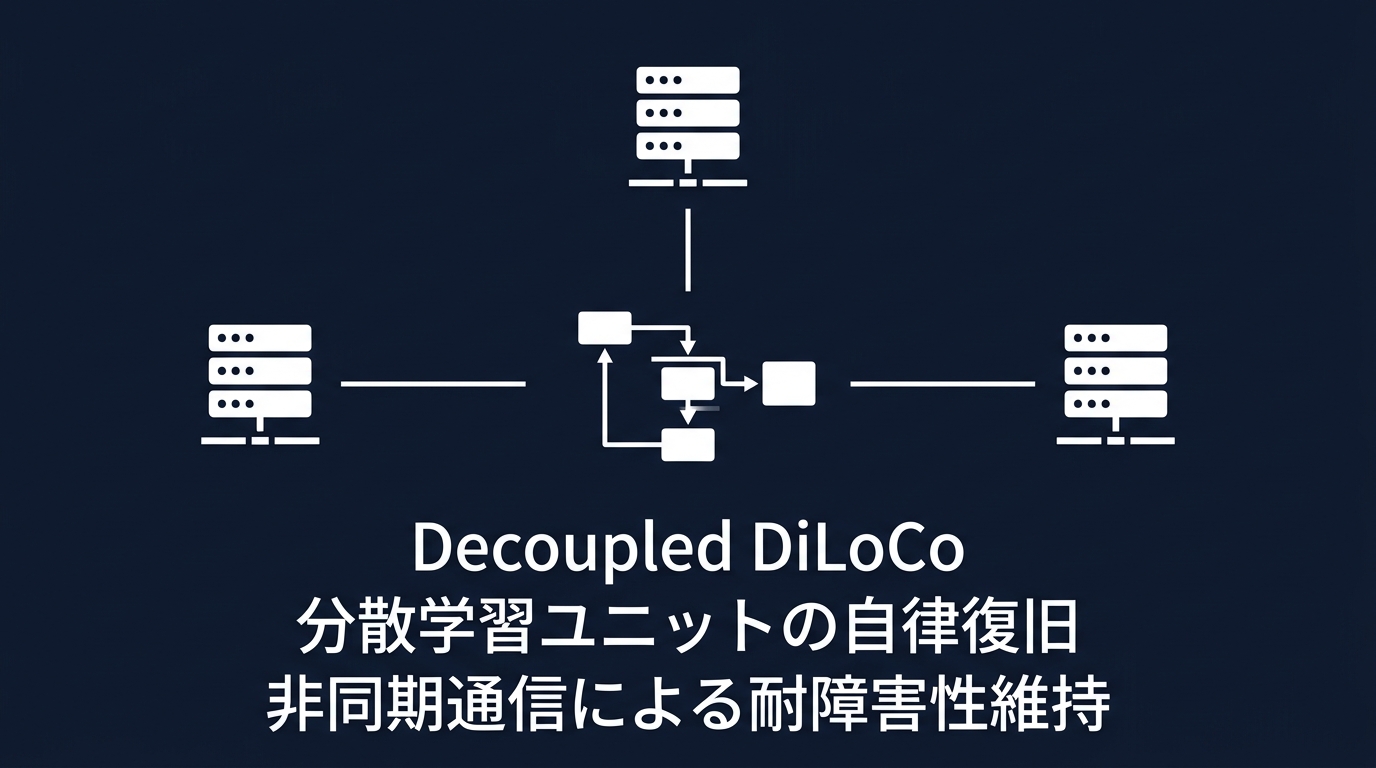
まず、Google DeepMindが発表したDecoupled DiLoCo(Distributed Low-Communication)だ。
これは、物理的に離れたデータセンター間で、巨大なAIモデルを非同期に分散学習させるアーキテクチャだ。
従来の学習は、何千ものGPUが同期する必要があり、1つのチップの故障が全体を停止させていた。
Decoupled DiLoCoは、計算リソースを独立した「島(learner units)」に分割する。
各島が非同期にデータをやり取りするため、一部のハードウェアがダウンしても、他の島は学習を継続する。
カオスエンジニアリングを用いたテストでは、学習ユニット全体をダウンさせても、システムは学習を止めず、復旧後にシームレスに再統合された。
次に、アプリケーション層での分散化だ。
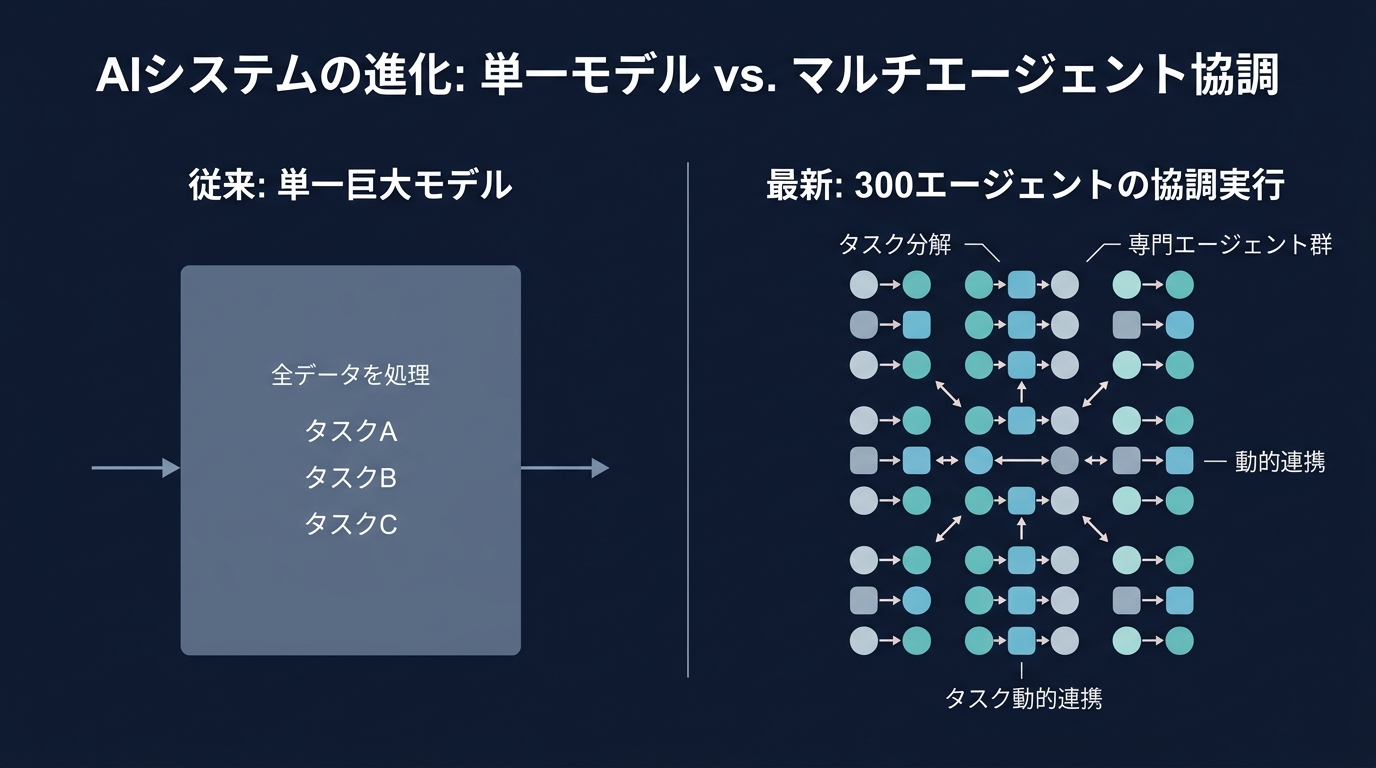
Moonshot AIが公開したオープンウェイトモデルKimi K2.6は、推論プロセスを分散化する。
最大の目玉はAgent Swarm機能だ。
最大300のサブエージェントを同時に走らせ、それぞれが4,000ステップのタスクを自律的にこなす。
ユーザーが指示を出すと、システムがタスクを分割する。
ウェブ調査、ドキュメント分析、コード生成といった専門スキルを持つエージェントに役割を割り振り、最終的な成果物を1回の実行でまとめ上げる。
ベンチマークでは、SWE-Bench Proで58.6、BrowseCompで83.2を記録した。
RustやGo、Pythonの環境で12時間以上連続稼働し、4,000回以上のツール呼び出しを連鎖させる耐久性も備える。
さらに、強力なモデルを分散環境やローカルで動かす技術も実用化されている。
Qwen 3.6-35B-A3BのようなマルチモーダルMoE(Mixture of Experts)モデルの推論環境構築に関する検証結果も公開されている。
VRAM 75GB以上の環境ではbf16精度でフル稼働し、40GB以上ならint8量子化で動作する。
それ以下のコンシューマー向けGPUでも、int4量子化とNF4(Normalized Float 4)フォーマットを活用すれば推論が可能だ。
思考プロセスの分離、ストリーミング生成、JSON構造化出力といった機能がローカル環境で制御できる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
エージェント協調と耐障害性が競争力になる。開発者から見た分散化の衝撃
これらの技術は、AI開発における「単一障害点の排除」を意味する。
これまでは、モデルのパラメータ数を増やし、巨大なGPUクラスタに押し込む手法が主流だった。
しかし、そのアプローチは物理的な限界とコストの壁に直面している。
Decoupled DiLoCoの非同期・分散学習は、インフラの制約をソフトウェアで解決する。
通信帯域が狭くても、遅延があっても、ハードウェアが壊れても学習が進む。
将来的に、世界中の余っているGPUリソースを安価に繋ぎ合わせて、巨大モデルを学習できる世界線を示唆する。
高価なサーバーを1カ所に集めなくても、分散した安価なGPU群で同等の成果が出せる。
しんたろー:
クラウドのGPUインスタンスが確保できなくて開発が止まる状況が気になる。
この分散学習がOSS化されて、安いスポットインスタンスを束ねて学習を回せるようになれば、インフラ代が下がるのではないかと思った。
そして、Kimi K2.6のAgent Swarmは、開発者のアプリケーション設計に影響を与える。
これまで開発者は、外部ライブラリを使って、エージェントのルーティングやタスク分割をコードで書いていた。
だが、Kimi K2.6はモデル自体がその構造をネイティブに理解している。
モデルにタスクを投げれば、内部で勝手にエージェントを立ち上げ、失敗したら別のエージェントがカバーする。
1つのプロンプトから、サインアップ機能、データベース操作、セッション管理を含むフルスタックのウェブサイトを構築し、画像生成ツールまで連携させてビジュアルを整える。
人間がオーケストレーションのコードを書く必要が減っていく。
Claude Codeを使ってコードを書いている身からすると、この「自律的なエラー修復とタスク分割」の進化は大きい。
Claude Codeもタスクを分割して自律的にファイルを探し、コードを修正するが、300エージェントの並列実行となれば次元が違う。
単一のAIに「完璧な答え」を求めるのではなく、複数のAIが「相談しながら、失敗を前提に修正を繰り返す」アーキテクチャが標準になる。
さらに、Qwen 3.6のようなMoEモデルのローカル推論技術が洗練されている点も見逃せない。
APIのレイテンシや制限に縛られず、手元のGPUで思考プロセスを制御できる。
推論の予算を動的に調整し、簡単なタスクは即座に返し、複雑なタスクにはリソースを割く。
このコントロール権が開発者の手元に戻ってくる意義は大きい。
APIのレートリミットに怯えながらバッチ処理を回す状況が気になる。
ローカルでint4量子化のMoEを動かして、単純なデータ整形は全部そっちに逃がす構成を組んでみたいと思った。
インフラの耐障害性、タスク実行の並列化、推論コストの最適化。
これらは「AIシステム全体の分散化と自律化」という1つのうねりだ。
単一の巨大モデルに依存するのではなく、小さな専門家の群れを束ねる設計力が、これからの開発者に求められる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
APIを叩くだけの時代は終わる。次世代AIアーキテクチャに向けた具体的な備え
開発への影響を考えると、「AIへのタスクの投げ方」と「システムアーキテクチャ」を見直す時期が来ている。
まず、エージェント指向の設計へのシフトだ。
これまでは「プロンプトエンジニアリング」で1回の回答精度を高める努力をしてきた。
だがこれからは、タスクをどう分割し、どのエージェントに割り当てるかの「オーケストレーション設計」が求められる。
Kimi K2.6のようにモデル側で自動分割してくれる機能は強力だが、大枠の設計は人間がやる必要がある。
以下のポイントを意識した設計が求められる。
* タスクの細分化: 1つの巨大なプロンプトを捨てる
* 役割の明確化: リサーチ、コーディング、レビューなど、エージェントの責務を分離する
* 非同期処理の前提: エージェント間の通信待ちや再試行を許容するシステム設計
* フェイルセーフ: 1つのエージェントが失敗しても、全体が止まらないリカバリーフローの構築
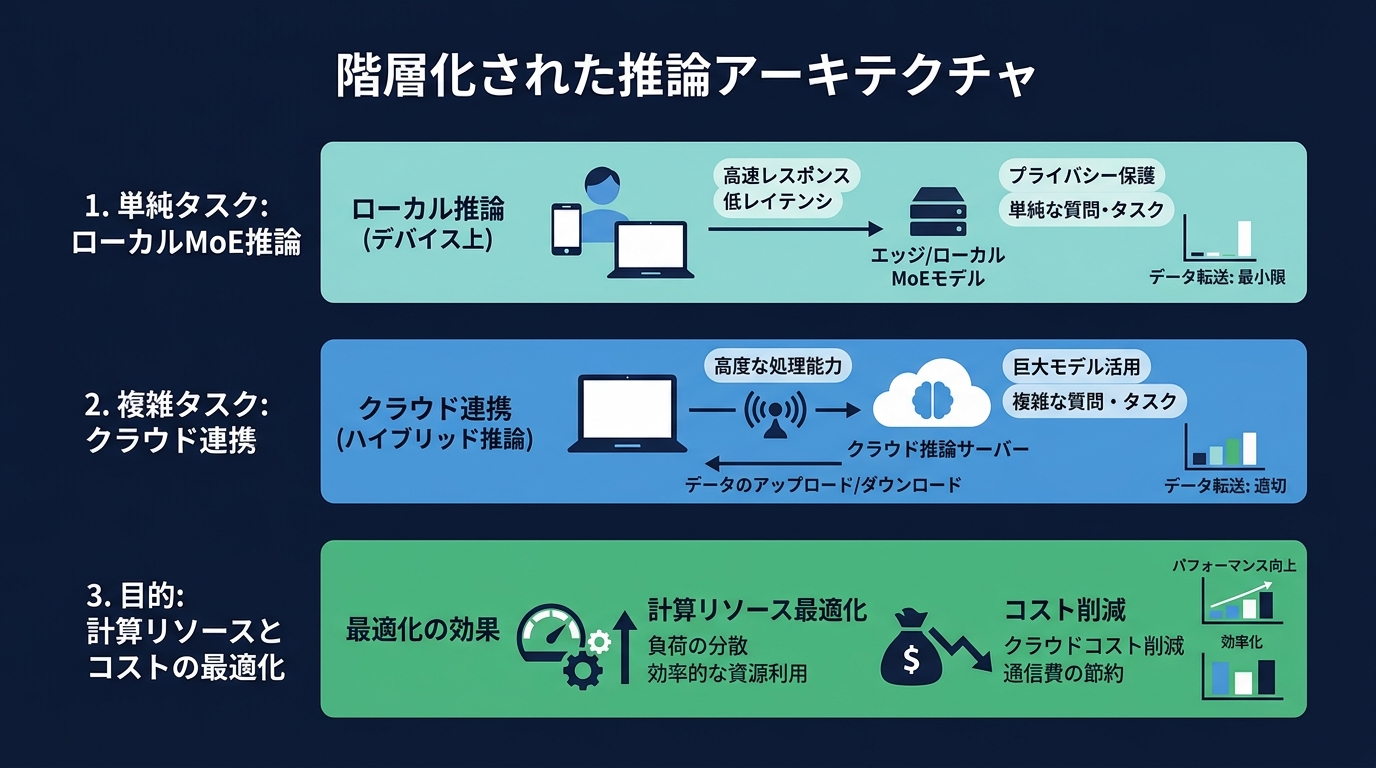
次に、モデルの使い分けとハイブリッド構成だ。
すべての処理を最新のクラウドAPIに投げるのは、コストもレイテンシも無駄が多い。
Qwen 3.6の検証が示す通り、ローカルや自前サーバーで動くMoEモデルの実用性は高い。
タスクの難易度に応じて、ルーティングを動的に変えるアーキテクチャが必要になる。
* フロントエンドの軽量処理: ローカルの量子化モデルで高速に捌く
* 複雑な推論やコード生成: クラウドの強力なモデルに投げる
* 思考予算の管理: タスクの重要度に応じて、AIに与える計算リソースを動的に調整する
ThreadPostの裏側でも、テキスト生成とハッシュタグ抽出でモデルを分けたい。
全部クラウドの強力なモデルに投げるとコストが嵩むため、単純作業はローカルのMoEにルーティングするゲートウェイの設計を考えたいと思った。
そして最も重要なのが、システム全体の耐障害性だ。
Decoupled DiLoCoが学習インフラで証明したように、これからのシステムは「壊れること」を前提に設計しなければならない。
APIのタイムアウト、幻覚による予期せぬ出力、エージェントの無限ループ。
これらを想定し、システムが自律的に回復する仕組みを組み込む。
単にエラーを吐いて止まるのではなく、別のエージェントがエラーログを読み込み、自己修復を試みるフローだ。
開発者は、AIを「便利な関数」として扱うフェーズから卒業しなければならない。
複数の自律的なシステムが非同期に連携し、最終的な成果物を生み出す「組織」を設計するフェーズに入った。
この分散と協調のパラダイムに適応した者が、次の時代の開発スピードを制する。
よくある質問(FAQ)
Q1: Decoupled DiLoCoのような分散学習は、小規模な開発チームでも利用可能ですか?
現時点では大規模な学習環境を想定した研究段階の技術だ。
しかし、この「非同期で分散学習する」という概念は、将来的に複数のクラウドリージョンやオンプレミス環境を安価に繋ぎ合わせるフレームワークとしてOSS化される可能性がある。
実現すれば、小規模チームでもスポットインスタンスを束ねて、低コストで独自モデルの学習やファインチューニングが可能になる。
Q2: Kimi K2.6のAgent Swarmは、既存のオーケストレーションツールと何が違いますか?
最大の違いは、モデル自体が「タスクの自動分割」と「エージェントの役割分担」をネイティブに理解している点だ。
外部のコードでエージェント間のデータの受け渡しや状態管理を制御する必要がない。
モデルの推論プロセスそのものにエージェント管理が組み込まれている。
そのためオーバーヘッドが少なく、4,000ステップを超えるような複雑なタスクの自動実行を、より安定してこなすことができる。
Q3: Qwen 3.6-35B-A3Bのようなモデルをローカルで動かすための推奨スペックは?
フルスペックのbf16精度で動かすにはVRAM 75GB以上が必要だ。
ハイエンドなサーバー環境が望ましい。
しかし、int8量子化なら40GB以上で動作し、int4量子化を活用すれば、VRAM 24GBクラスのコンシューマー向けハイエンドGPUでも推論自体は可能だ。
実務で使うなら、用途に合わせて量子化レベルを落とし、思考プロセスを明示的に制御して精度を補うアプローチが現実的だ。
まとめ:分散化がもたらす「止まらないシステム」の未来
巨大な単一モデルに依存する時代は終わり、分散学習とエージェント協調の時代が幕を開けた。
インフラもアプリケーションも、単一障害点をなくし、自律的にエラーを修復するアーキテクチャへと進化している。
このパラダイムシフトを理解し、自分の開発環境にどう組み込むかが、今後のエンジニアの価値を決める。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
