
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
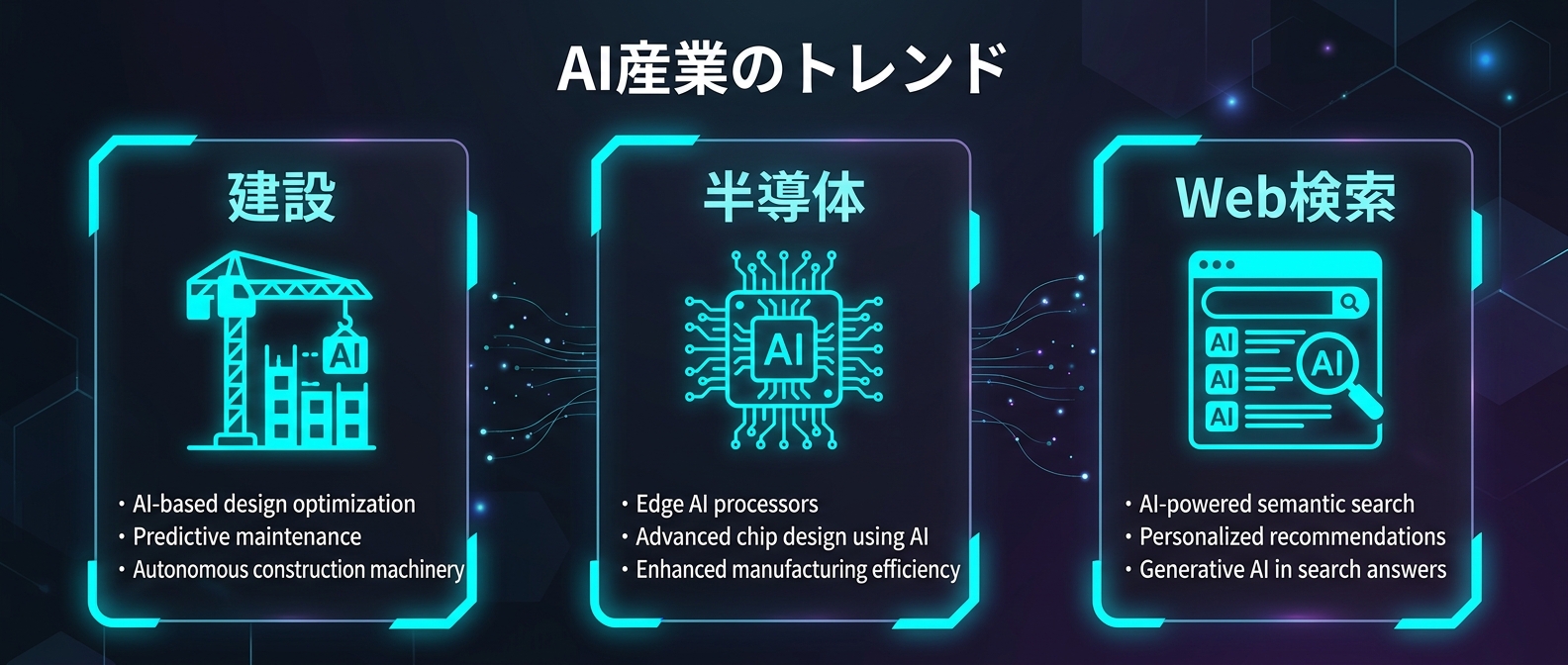
激変するAI開発の主戦場
出た。Metaがコンクリートの配合を設計するAIモデルをオープンソースで公開した。
建設現場の職人が持つ「勘」を、完全にデータ化する試みだ。
一方で、半導体製造の現場では全く別の動きが起きている。
完全オフラインの環境で、独自のローカルLLMを稼働させるプロジェクトが急増しているのだ。
さらにWeb開発の世界では、AI検索エンジン向けの最適化が急務になっている。
一見すると全く関係のない3つのニュースだ。
だが、根底にあるテーマは完全に一致している。
AI開発の最大のボトルネックは、モデルの性能ではなくなった。
現場の「暗黙知」や「非構造化データ」を、いかにAIが解釈できる形式に変換するか。
この「データの構造化」が、開発者の新たな主戦場だ。
現場の暗黙知をデータ化する3つの潮流
米国は年間4億立方ヤードものコンクリートを消費している。
地球を何周もする高速道路を舗装できるほどの圧倒的な量だ。
しかし、その原料となるセメントの約23〜25%は輸入に依存している。
これを国内産で代替し、サプライチェーンを強靭化するためのプロジェクトが動いている。
そこでMetaが公開したのが、コンクリート配合設計AI「BOxCrete(Bayesian Optimization for Concrete)」だ。
ベイズ最適化という手法を用いて、職人の長年の経験と勘をアルゴリズムに落とし込んでいる。
コンクリートの設計は、強度、コスト、乾燥速度など、相反する要件のトレードオフだ。
これまでは研究所での泥臭い試行錯誤と、ベテランの直感に頼りきっていた。
この属人的なプロセスを、AIが再利用可能なデータセットに変換したのだ。
全く同じ現象が、半導体製造の現場でも起きている。
半導体工場の故障解析は、製造工程の中で最も属人的な作業だ。
不良チップが出た際、電気テストから根本原因の特定まで、ベテランエンジニアが経験でフローを回している。
新人が一人前になるには5年かかる世界だ。
この解析フロー全体を、LLMベースのエージェントに計画させる提案が次々と出てきている。
しかし、ここで巨大な壁にぶつかる。
過去の解析レポートは、WordやPDFの形式で社内に散在しているのだ。
企業秘密の塊であるこれらのデータを、クラウドのAPIに投げることは絶対に許されない。
結果として、エッジサーバーに軽量なオープンモデルを載せ、完全オフラインでRAGを構築する泥臭い作業が必要になっている。
そしてWeb開発の領域でも、データの構造化が最大の焦点になっている。
AI検索エンジンに自分のコンテンツを引用させるための最適化手法が急速に普及しているのだ。
従来の検索エンジン対策で1位を取っていても、AIには完全に無視される現象が起きている。
AIは、HTMLの構造を雰囲気で読んでくれない。
明示的に構造化されたデータと、信頼性の高いソースだけを優先的に取得する。
これら3つの領域の動きは、AI活用における一つの現実を突きつけている。
どれだけ強力なAIモデルを用意しても、入力するデータが整理されていなければ全く機能しない。
現場の非構造化データを、AIが読める形に変換する土台作りが先決だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
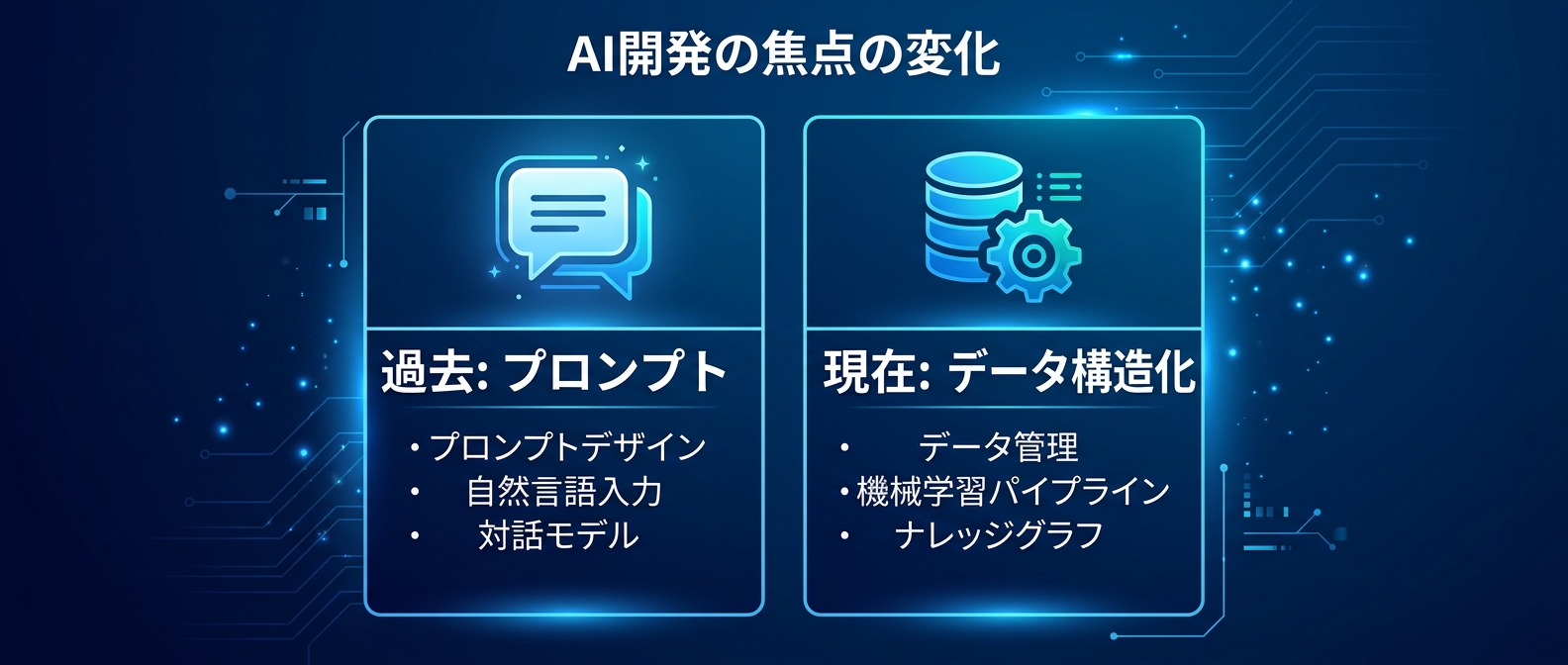
データ構造化がすべてを決める時代
AI開発のフェーズは完全に次の段階に移行した。
少し前までは、いかに巧妙なプロンプトを書くかが持てはやされていた。
今は違う。
AIに読み込ませる「データパイプラインの構築」が、出力の品質を決定づける。
半導体工場の故障解析の例が、この現実を最も如実に表している。
LLMに故障の物理メカニズムを理解させるのは無理筋だ。
しかし、「過去に類似の不良が出た際、チームがどのような手順で調査したか」を検索させることはできる。
これはRAGとLLMの最も得意とする領域だ。
問題は、その検索対象となるナレッジベースが存在しないことだ。
現場のデータは汚い。
フォーマットの異なるレポート、手書きのメモ、装置のログデータ。
これらを統合し、ベクトルデータベースに格納可能な形式にクレンジングする作業が必要になる。
美しいAIエージェントを構築する前に、泥臭いデータ整備に2年を費やすのが現実だ。
しかも、これらのデータは外部に出せない。
数十億パラメータの軽量モデルを、限られたGPUメモリで動かすローカル環境の構築スキルが求められる。
クラウドAPIを叩くだけの開発とは、全く異なる次元の知識が必要だ。
しんたろー:
クラウド依存のアーキテクチャは、エンタープライズ領域では限界が見え始めている。
機密データを扱う案件の要件定義を見ると、ローカルLLMの稼働実績を問われることが増えた気がする。
軽量モデルの推論速度と精度のバランスをどう見極めるか、これは気になっているテーマだ。
MetaのBOxCreteも、本質的なアプローチは同じだ。
「水とセメントの比率」という職人の暗黙知を、機械学習が処理できるパラメータに変換している。
物理世界の試行錯誤を、デジタル空間のデータ構造にマッピングする作業だ。
この「ドメイン固有の知識を構造化する」というプロセスが、AIの真の価値を生み出す。
Web開発の現場でも、この構造化の波は容赦なく押し寄せている。
ブログ記事や企業情報をただHTMLで記述する時代は終わった。
AI検索エンジンに対して、「ここは記事のタイトル」「ここは著者」「ここはよくある質問」と明示する必要がある。
これを実現するのが、特定のフォーマットに従った構造化データだ。
AIは人間のように画面のレイアウトから文脈を推測してくれない。
機械的にパース可能なJSON形式のデータを探し求めているのだ。
Claude Codeを使って日々の開発をしていると、この「構造化」の重要性を痛感する。
AIにコードの修正を依頼する際、雑なテキストで指示を出しても期待した結果は返ってこない。
現在のシステムの仕様、変更したい箇所、満たすべき要件。
これらを論理的に構造化して渡すことで、初めて精度の高いコードが生成される。
AIは魔法の杖ではない。
入力されたデータの構造を解釈し、確率的に最も妥当な結果を出力するだけの計算機だ。
汎用モデルの性能向上を口を開けて待つのではなく、手元のデータを徹底的に構造化する。
特定のドメインに特化した小規模なAIを、圧倒的に質の高いデータで構築する。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
BOxCreteが示す「ベイズ最適化×現場データ」の破壊力
BOxCreteの公開と同時に、Metaはミネソタ州ローズマウントのデータセンターで実際に使用したコンクリート配合の基礎データセットも公開した。
これは単なるモデルの公開ではなく、「再現可能な試行錯誤の記録」を丸ごと渡すという意味を持つ。
Metaはこの取り組みで複数の賞を受賞している。
2025年 Building Innovation Award(Best Partnership部門)、2025年 Slag Cement Award(Sustainable Concrete Project of the Year)、いずれもAmrizeおよびイリノイ大学アーバナ・シャンペーン校との共同受賞だ。
パートナーのAmrizeは北米最大のセメント・コンクリートメーカーだ。
セメント工場18拠点、セメントターミナル141拠点、生コンクリートサイト269拠点を北米全土で運営している。
Amrizeは2026年に約10億ドルの設備投資を発表し、国内セメント生産の拡大に動いている。
「Made in America」セメントラベルも立ち上げ、米国基準・米国製造を保証するブランド戦略を展開中だ。
セメント・コンクリートセクターは米国経済に年間1,300億ドル超を貢献し、約60万人の雇用を支えている。
それでも輸入が国内需要の約23%を占めている現状が、このプロジェクトの背景にある。
BOxCreteの技術的な改善点は明確だ。
Metaの前世代モデルと比較して、ノイズの多いデータへの耐性向上と、コンクリートのスランプ(作業性の重要指標)を予測する新機能の追加が実装されている。
僕らの開発プロセスはどう変わるか
この環境の中で、開発者の実務はどう変わっていくのか。
最も大きな変化は、時間の使い方のシフトだ。
プロンプトの微調整に時間を溶かすのは、もうやめた方がいい。
代わりに、データの構造化とパイプラインの構築に大半のリソースを割くことになる。
社内向けのAIツールを開発するなら、まずは既存ドキュメントのパースから逃げられない。
PDFからテキストを正確に抽出し、意味のあるチャンクに分割する。
この地味で面倒な前処理の精度が、RAGの回答品質の大半を決める。
最新のLLMを使っても、ゴミデータを検索させればゴミしか出力されない。
WebサービスやSaaSの開発でも、根本的な設計思想を変える必要がある。
ユーザーが入力した自由記述のテキストを、そのままデータベースに突っ込むのは危険だ。
裏側でAIを噛ませて、システムが処理しやすい構造化データに変換してから保存する。
この「入力時のデータ整形」が、後々のAI機能の拡張性を大きく左右する。
ユーザーの雑多な入力をどう扱うか、これはSaaS開発の永遠の課題だ。
ThreadPostのアーキテクチャを考える上でも、裏側でのデータクレンジングの仕組みは常に頭を悩ませる。
入力されたテキストの意図をAIに解釈させ、一貫したフォーマットに落とし込む処理フローの設計が、プロダクトの質に直結すると感じている。
セキュリティとプライバシーの観点も、これまで以上にシビアになる。
半導体工場の例が示す通り、すべてのデータをクラウドのAPIに投げられるわけではない。
用途と機密レベルに応じて、クラウドとローカルを使い分けるハイブリッドな設計力が求められる。
どのデータを外部に出し、どのデータを社内に留めるか。
この境界線を明確に定義し、システムアーキテクチャに落とし込むスキルが必要だ。
オープンソースの軽量モデルをエッジ環境で動かす技術は、もはや一部の専門家のものではない。
そして、Web上に公開するコンテンツの扱いも変わる。
AI検索エンジンからの流入を狙うなら、構造化データの実装は必須要件になる。
HTMLのヘッダーに、記事のメタデータや組織情報をJSON形式で埋め込む。
これは単なるSEO対策ではない。
AIという新たな「読者」に対して、サイトの情報を正確に伝えるためのインターフェース設計だ。
これを怠れば、どれだけ質の高いコンテンツを作っても、AIの回答ソースとして引用されることはない。
具体的なアクションとして、以下の対応はすぐにでも検討できる。
- 既存データの棚卸し: 社内に散在する非構造化データの形式と保存場所を特定する
- パース処理の検証: PDFやWordからテキストを抽出するツールの精度を比較する
- ローカル環境の構築: オープンソースの軽量モデルをローカルで動かす手順を確立する
- 構造化データの実装: Webサイトの主要ページに適切なメタデータを埋め込む
- チャンク分割の最適化: RAGに渡すテキストの最適な分割単位を検証する
- ハイブリッド設計: クラウドAPIとローカルLLMの使い分けの基準を策定する
- 入力データの整形: ユーザー入力を裏側で構造化するパイプラインを構築する
- ドメイン知識の抽出: 現場のベテランの暗黙知をヒアリングし、形式知化する
開発者が知るべき3つの疑問
Q1: AI検索エンジン対策として、開発者が今すぐできることは何ですか?
WebサイトのHTMLに、JSON形式の構造化データを実装することだ。特にブログ記事などのコンテンツには記事のスキーマ、企業情報には組織のスキーマ、よくある質問にはFAQのスキーマを追加する。これにより、AI検索エンジンがページ内容を機械的に理解しやすくなり、回答のソースとして引用される確率が上がる。人間の見た目だけでなく、機械向けのデータ構造を整えることが先決だ。
Q2: 機密性の高い社内データをAIで活用するにはどうすればよいですか?
クラウドのAPIにデータを送信できない場合、ローカル環境で稼働するLLMの導入が必須になる。数十億パラメータクラスの軽量かつ高性能なオープンモデルを利用し、オフライン環境で推論を行うアーキテクチャを構築する。同時に、社内に散在する非構造化ドキュメントを検索可能な形式にクレンジングし、ベクトルデータベースに格納する泥臭いデータ整備作業が不可欠だ。半導体FABの故障解析の事例が示す通り、LLMエージェントを作る前にデータ整備で2年かかるのが現実だ。
Q3: MetaのBOxCreteは、WebやSaaSのエンジニアにも関係ありますか?
大いに関係ある。直接的な材料工学の知識がなくても、「現場の暗黙知をデータ化し、機械学習が処理できるパラメータに落とし込む」というアプローチはすべてのドメインに共通する。ユーザーの行動データや、システムの設定値のチューニングなど、実世界の複雑な変数をどうやってAIモデルに学習させるか。そのデータエンジニアリングの手法として、非常に優れたリファレンスになる。
異業種のAI活用事例は、一見自分には関係ないように思えるが、抽象化すると直面している課題は全く同じだったりする。
コンクリートの配合も、半導体の歩留まりも、Webの検索順位も、結局は「変数の多すぎる複雑系をどう制御するか」という問題に行き着く気がする。
ドメインの壁を越えて解決策を横展開できるエンジニアは、確かに強そうだ。
綺麗なデータがAIの真価を引き出す
AIの進化は止まらないが、それを使いこなすための条件は驚くほどシンプルだ。
現場の暗黙知を形式知化し、AIが読める綺麗なデータ構造を作ること。
AIのポテンシャルを最大限に引き出すには、適切なデータの構造化が不可欠だ。
ThreadPostを使って、あなたの知見もAIが読み取りやすい形で発信してみませんか?

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code開発術7選|AIが迷わない環境構築の極意

Claude CodeでAI開発が変わる。役割分担によるハルシネーション抑制術

CursorのShared Canvasesで開発はどう変わるのか。AIが生成した設計の文脈をチームで共有する新時代の必須知識

【2026年版】最強AI開発ツール3選|Claude Code・Cursor・Geminiを徹底比較

Claude Codeの機能更新とAI開発の試行錯誤
