
AIエージェント開発を始めるとき、真っ先に巨大なフレームワークをインストールしていないだろうか。
実は今、そのブラックボックス化によってプロジェクトが座礁するケースが相次いでいる。
LLMが内部でどう思考し、どうツールを呼び出しているのか。
基礎となるループ構造を知らないまま複雑なシステムを組むと、エラーの迷宮から抜け出せなくなる。
フレームワークを完全に捨てることではない。
その裏側にある「意思決定と実行の分離」という本質を理解し、制御権を取り戻すことだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
なぜ「とりあえずフレームワーク」が開発を停滞させるのか
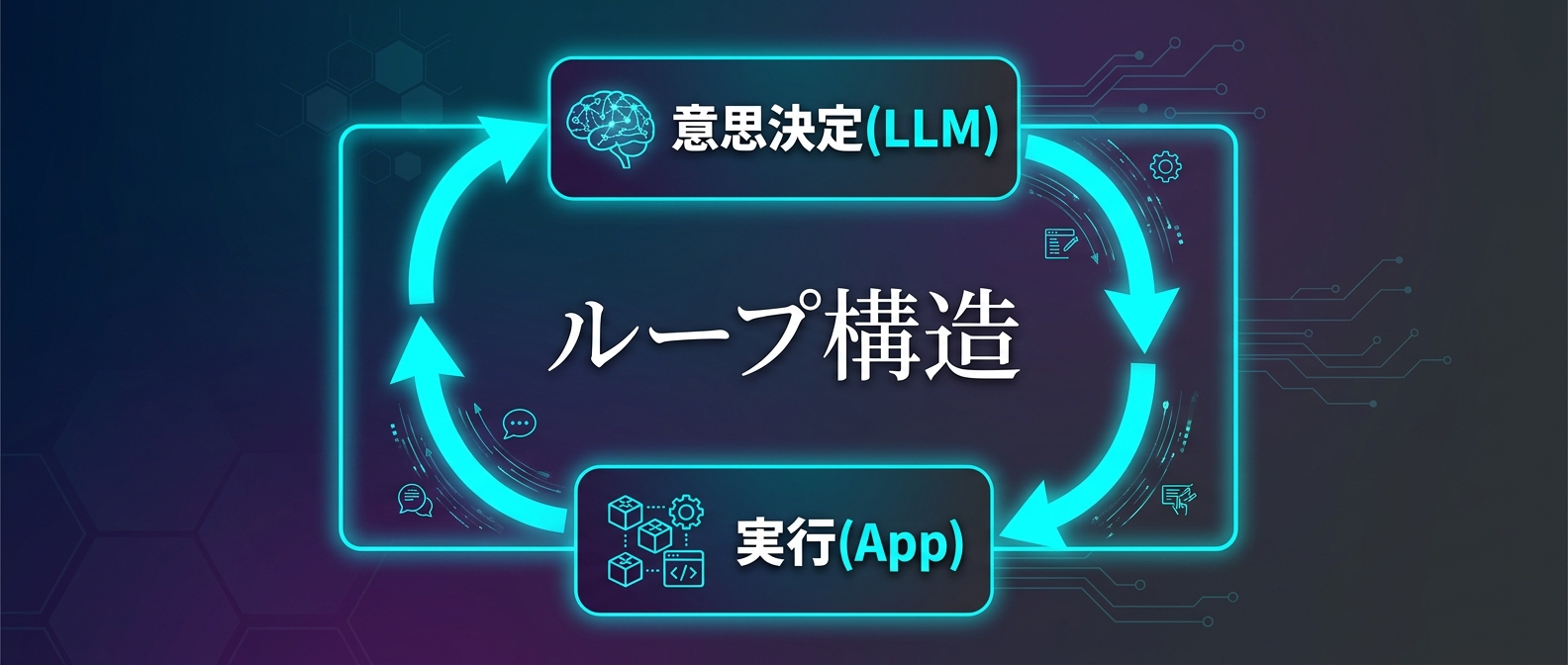
AIエージェントの代表的な実装パターンにReActと呼ばれる手法がある。
これはLLMが「考える」ステップと「行動する」ステップを交互に繰り返す仕組みだ。
多くの開発者はこれをLangChainやMastraなどの既存のフレームワーク経由で手軽に利用している。
しかし、その内部で実際に何が起きているのかを正確に把握している人は少ない。
LLMは本来、テキストを生成することしかできない言語モデルだ。
どれだけモデルの性能が向上しても、それ単体で業務システムを直接操作することは不可能だ。
AIエージェントが自律的に動いているように見えるのは、決してAI自体が魔法のように賢いからではない。
外部のシステムを実行できる構造を持っている。
この構造の核となるのが、LLMによる意思決定の構造化だ。
開発者はLLMに対して、事前に利用可能なツールの仕様書を渡しておく。
するとLLMは、プロンプトと現在の状況から「どのツールを使うか」「引数は何か」を論理的に推論する。
そして、その結果をJSON形式などの構造化データとして出力する仕組みだ。
ここが最も誤解されやすいポイントだ。
LLM自身が関数やAPIを直接実行しているわけでは決してない。
LLMはあくまで実行内容を決定し、単なる文字列として出力しているだけだ。
その出力を受け取ったアプリケーション側が、実際の処理を泥臭く実行している。
そして、実行結果を再びテキストとしてLLMに返し、次の行動を促す。
この「プロンプトによる制約」と「出力のパース処理」の反復こそが、エージェントの正体だ。
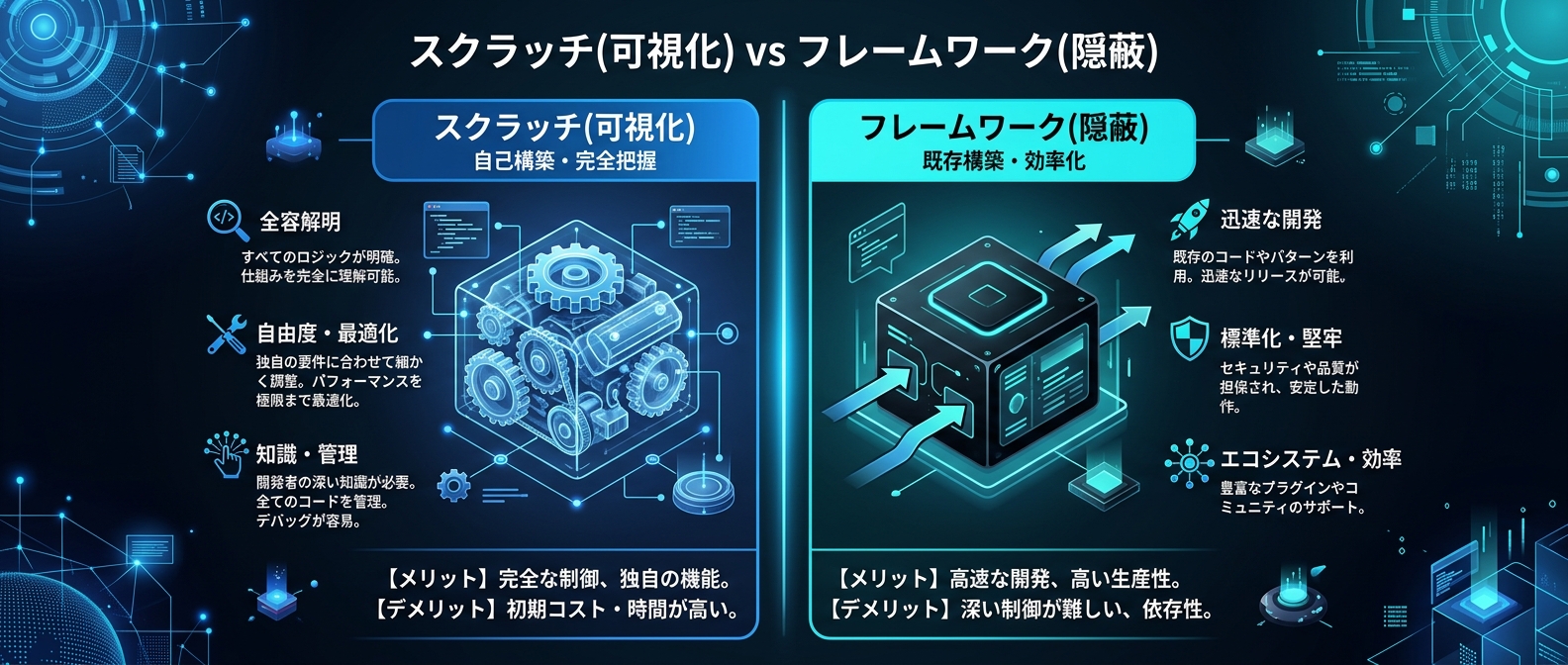
標準のOpenAI SDKを使って、この仕組みをゼロから実装するアプローチが今、再評価されている。
巨大なフレームワークを一切使わずに、標準機能だけで推論のループを構築する。
これにより、これまで隠蔽されていた推論プロセスが完全に可視化される。
エラーが起きた際も、LLMの出力がおかしいのか、アプリケーション側のパース処理が失敗したのかが一目瞭然になる。
この基礎的なメカニズムの理解こそが、後の複雑なシステム構築における最強の武器となる。
ツール呼び出しの際は、関数の名前や引数の型を定義したスキーマをLLMに渡す。
LLMはそのスキーマを読み解き、ユーザーの要求を満たすための最適な関数を選択する。
出力されたJSONデータをアプリケーションが解析し、指定された関数を呼び出す。
外部APIから取得したデータは、再びプロンプトの一部としてLLMにフィードバックされる。
この一連の流れを自らの手で実装することで、エージェントの挙動を完全に掌握できる。
高度に抽象化されたツールは、正常に動いている時は魔法のように便利だ。
しかし、ひとたび想定外の挙動を示すと、途端に手が出せなくなる。
フレームワークの奥深くで発生したパースエラーを追うのは至難の業だ。
だからこそ、まずはTypeScriptやPythonの標準SDKでスクラッチ実装を経験しておく必要がある。
基礎ループの挙動を肌感覚で知っているかどうかが、プロとアマチュアを分ける境界線になる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者目線で読み解く「エージェントの解剖学」
エージェント開発において「とりあえずフレームワーク」という思考停止は致命傷になる。
LLM自身が仕事を進めていると錯覚しがちだが、実態は単なるテキスト生成器に過ぎない。
賢いから動くのではない。
実行を担保する外部システムとの連携があるから動く。
外部システムとLLMをつなぐインターフェースこそが、エージェントシステムの心臓部である。
僕が毎日使っているClaude Codeのような自律型コーディングAIも、裏側の仕組みは全く同じだ。
ファイルの読み書きやコマンドの実行をツールとして定義し、LLMに意思決定させている。
この「意思決定」と「実行」の分離構造を深く理解していれば、AIの挙動は手に取るように予測できる。
LLMがどの情報を元に判断を下し、どのような形式で指示を出してくるのか。
それを知ることで、より効果的なプロンプト設計やエラーハンドリングが可能になる。
しんたろー:
Claudeに複雑なタスク投げた時、延々とループに入って抜け出せなくなるの、原因が気になるよね。
中のJSONパースでコケてるか、ツールの戻り値が想定外でLLMが混乱してるかのどっちかだと推測する。
自分でループ組んだ経験があると、ログ見た瞬間に「あ、ここで詰まってるな」ってすぐ分かる気がする。
現代のエージェント開発では、2つのアプローチを組み合わせるのがトレンドだ。
1つはプロンプト上で思考と行動を明示させる手法である。
もう1つは、APIレベルで提供されるネイティブな関数呼び出し機能だ。
前者は推論過程を可視化でき、複雑なタスクの解決プロセスを追跡するのに向いている。
後者は確実な構造化データを得るのに適しており、システム間の連携を強固にする。
これらを融合させることで、極めて堅牢なエージェントシステムが構築できる。
推論フェーズでは思考プロセスを展開させ、実行フェーズでは厳密なスキーマに従わせる。
フレームワークは、この複雑な連携をわずか数行のコードで実現してくれる。
複数エージェントの対話や、並行処理のパイプライン構築には確かに不可欠な存在だ。
しかし、その裏で何が行われているのかを知らなければ、適切なチューニングは絶対に不可能だ。
LLMに渡されるシステムプロンプトが内部でどう構築されているのか。
ツールの実行結果がどのようなフォーマットで履歴に追加されているのか。
スクラッチ実装の経験があれば、これらの内部挙動を容易に想像できる。
エラーメッセージを見ただけで、フレームワークのどの層で問題が起きたのかを特定できる。
このデバッグ能力の差が、開発スピードに違いを生み出す。
AIは「答える存在」から「仕事を進める存在」へと進化を遂げた。
だが、その仕事を進めているのは、僕たちが書いた泥臭い実行コードだ。
LLMは単なる高性能なルーターやディスパッチャーに過ぎない。
入力されたコンテキストを解析し、どこに処理を振り分けるかを決定しているだけだ。
この事実を直視することで、AI開発の解像度は上がる。
魔法の箱として扱うのではなく、システムの一部として完全に制御する。
LLMの不確実性を、アプリケーション側の堅牢なロジックでカバーする。
それこそが、プロダクションレベルのAIシステムを構築するプロのエンジニアに求められる姿勢だ。
基礎を知らずして、応用を語ることはできない。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務のエージェント設計はどう変わるか
では、実際の開発プロジェクトでどう立ち回るか。
要件の複雑さに応じたアーキテクチャの柔軟な使い分けが必須になる。
単一のLLM呼び出しと数個のツール実行で完結するようなシンプルなタスク。
これなら標準SDKを使ったスクラッチ実装で十分すぎるほどだ。
例えば、npmパッケージの選定を行うエージェントを構築する場合を考えてみる。
searchツールでパッケージを検索し、get_infoツールで詳細情報を取得する。
この程度の要件であれば、TypeScriptとOpenAI SDKだけで完全に実装可能だ。
余計な依存関係を徹底的に排除でき、軽量でメンテナンス性の高いコードベースを維持できる。
ブラックボックスが存在しないため、不具合の特定も一瞬で終わる。
アップデートによる破壊的変更に怯える必要もない。
一方で、複数の専門エージェントが自律的に議論を交わすような高度なシステム。
あるいは、長期的なメモリ管理や並行処理が求められる大規模なプロダクション環境。
ここでは迷わず、AgentScopeのような実績のある強力なフレームワークを採用する。
gpt-4o-miniモデルを使用し、temperature 0.7、max_tokens 1024といったパラメータを設定する。
Pydanticを用いて構造化出力を強制し、複数のエージェントが並行して問題を分析するパイプラインを構築する。
ただし、その際も内部の動きを常に意識した設計が不可欠だ。
特に実務で最も注力するポイントが、LLMに渡すツールの定義である。
ここを疎かにすると、どんなに優れたフレームワークを使ってもシステムは破綻する。
LLMって関数名より説明文をガッツリ読んでるんだよね。
「このツールはこういう時に使え」って説明をサボると、平気でトンチンカンなAPI叩きに行く。
スキーマの定義にどれだけ魂込められるかで、エージェントの賢さが決まるって分かったよ。
LLMに正しいツールを選ばせるためには、説明文と引数スキーマの明確化が命だ。
関数名だけでは、LLMはその用途や制約を正確に判断できない。
どのような状況で使うべきか、どのような値を受け付けるかを極めて詳細に記述する。
さらに、プロンプト内で「良い引数の例」と「悪い引数の例」を明示する。
これだけで、ハルシネーションや誤ったツール呼び出しの確率は減少する。
エージェントの行動ログを常時監視する仕組みも必ず導入する。
LLMが何を考え、どのツールを選択し、どんな結果を受け取ったか。
この一連のトランザクションをすべて記録し、後から分析できるようにしておく。
エージェント開発は、システムを作って終わりではない。
ログを見ながらプロンプトやツール定義を微調整し続ける、泥臭い運用フェーズが待っている。
想定外のエラーが起きたとき、LLMの推論が間違っていたのか、ツールの実行が失敗したのか。
ログがあれば、問題の切り分けは容易になる。
スクラッチ実装で培った基礎ループの理解は、この運用フェーズで最大の威力を発揮するはずだ。
システムの状態を常に可視化し、制御可能な状態を保つ。
それが、複雑化するAI開発を成功に導く唯一の道だ。
異なるアプローチを比較することで、エージェント開発の全体像が浮き彫りになる。
TypeScriptによるゼロからの実装は、ReActの基礎ループを完全に可視化する。
一方でAgentScopeのようなフレームワークは、マルチエージェントの対話や並行処理を容易にする。
これら2つの知見を統合することで、最適なアーキテクチャの選択が可能になる。
基礎的な推論プロセスはスクラッチ実装で理解を深める。
その上で、複雑なワークフローには適切なフレームワークを導入する。
このハイブリッドなアプローチこそが、現代のAI開発における最適解だ。
ブラックボックスを排除しつつ、開発効率を最大化する。

AIエージェント開発のよくある疑問
ReActとFunction Callingの違いは何ですか?
ReActはプロンプティングの手法だ。
「思考」と「行動」をプロンプト上で明示的に出力させ、推論過程を可視化しながらタスクを段階的に進める。
一方、Function CallingはLLMのAPIレベルで提供される機能だ。
利用可能な関数のスキーマを渡し、LLMに実行すべき関数と引数をJSON形式で出力させる。
現代の開発では、ReActの思考プロセスとFunction Callingの確実なツール実行を組み合わせて実装することが主流になっている。
エージェント開発において、フレームワークは導入するのか?
要件の複雑さによって判断する。
単一のLLM呼び出しと数個のツール実行で済むなら、標準SDKでのスクラッチ実装を強く推奨する。
依存関係が減り、ブラックボックス化を完全に防げる。
しかし、複数エージェントの対話、並行処理、メモリ管理が必要なプロダクションレベルのシステムを構築する場合は別だ。
この領域では、AgentScopeなどのフレームワークの導入が開発効率と保守性を引き上げる。
LLMにツールを正しく選ばせるためのコツはありますか?
ツールの説明文と引数スキーマを極限まで明確に定義することだ。
LLMは関数名だけでなく、説明文を深く読み込んでどのツールを使うべきか判断している。
また、プロンプト内に「良い引数の例」と「悪い引数の例」を明示することが極めて有効だ。
これにより、LLMのハルシネーションや誤ったツール呼び出しを未然に防ぎ、システムの安定性を向上させることができる。
まとめ
AIエージェントの本質は、高度な推論力と泥臭い実行処理の組み合わせだ。
基礎構造を深く理解すれば、どんな複雑なシステムも恐れるに足らない。
結局、最新技術も裏側はシンプルなループの積み重ねなんだよな。
魔法の正体を知った上で使いこなすのが、エンジニアの醍醐味って気づいたよ。
さて、今日もClaude Codeとペアプロしてきますか。
(エラー吐きまくって1時間溶かしたけどね笑)

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
