
LLMアプリを開発していて一番頭を悩ませるのが、出力品質の担保だ。同じプロンプトでも毎回回答がブレる。テストを自動化しようにも、従来のWebアプリの手法が全く通用しない。本番環境に出した途端、ハルシネーションや個人情報漏洩のリスクに怯えることになる。結論から言うと、LLMアプリには専用の設計と評価基盤が不可欠だ。今回は、LLMアプリの品質を劇的に上げる評価・テスト手法を3つのフェーズに分けて解説する。
具体的な手法に入る前に、LLM特有の性質を理解しておく必要がある。LLMはシステム的なエラーを出さずに、もっともらしい嘘をつく。ステータスコードが200で返ってきても、中身が間違っていることが頻繁に起きる。だからこそ、開発時のプロンプト設計、テスト時の意味的評価、運用時の専用監視という3段構えの対策が必要になる。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
手法1:プロンプトの構造化で「出力ガチャ」を防ぐ
まずは開発フェーズの対策だ。LLMの出力が安定しないとき、多くの人はプロンプトに指示をどんどん書き足してしまう。しかし、これは逆効果だ。指示の量ではなく、入力の構造が曖昧なことが出力ブレの原因だ。
LLMはトークン列を意味の塊(セマンティック・ユニット)として処理する。構造が明示されていれば解釈が一意に定まり、曖昧であれば出力が分散する。つまりプロンプト設計とはLLMの入力インターフェース設計であり、これを防ぐには、プロンプトの入力スキーマを定義する「セマンティック・アーキテクチャ」という設計手法を取り入れるとよい。具体的には、プロンプトを以下の4つの要素に分割し、マークダウンの見出しで明確に分離する。
- Role(役割):AIにどのような立場で振る舞うかを指定する
- Context(前提):タスクの背景や、優先すべき条件を定義する
- Task(タスク):具体的に何をしてほしいかを順序立てて書く
- Constraints(制約):使っていいツールや、出力フォーマットのルールを縛る
たとえば、単に「データを読み込んでグラフを作って」と書くのではなく、見出しを使って構造化する。何を、どんな前提で、どんな制約で処理するのかを明示することで、LLMの解釈が一意に定まる。結果として、出力ガチャと呼ばれるブレを大幅に減らすことができる。まずは既存のプロンプトを見出しで区切ることから始めるべきだ。
手法2:LLM-as-a-Judgeで意味的な誤りをテストする
プロンプトを整えたら、次はテストフェーズだ。ここで多くの開発者がつまずく。LLMアプリのテストでは、従来の文字列比較テストには明確な限界がある。
たとえば、顧客からのメールを要約するアプリを想像するとわかりやすい。正解が「お客様は解約を検討されています」だとする。LLMの出力が「お客様は解約を希望されています」だった場合、文字列の類似度を測るテストでは合格になってしまう。しかし、検討していると希望しているでは意味が全く違う。逆に、意味は同じなのに言い回しが違うだけで不合格になるケースも多い。
この問題を定量的に検証した結果、文字列比較(Levenshtein ratio)では、意味的に正しいパラフレーズが不合格になりやすく、逆に意味的な誤りを見逃すケースも多いことがわかっている。見逃しと過検知が重なると、テスト結果を信じられなくなる。
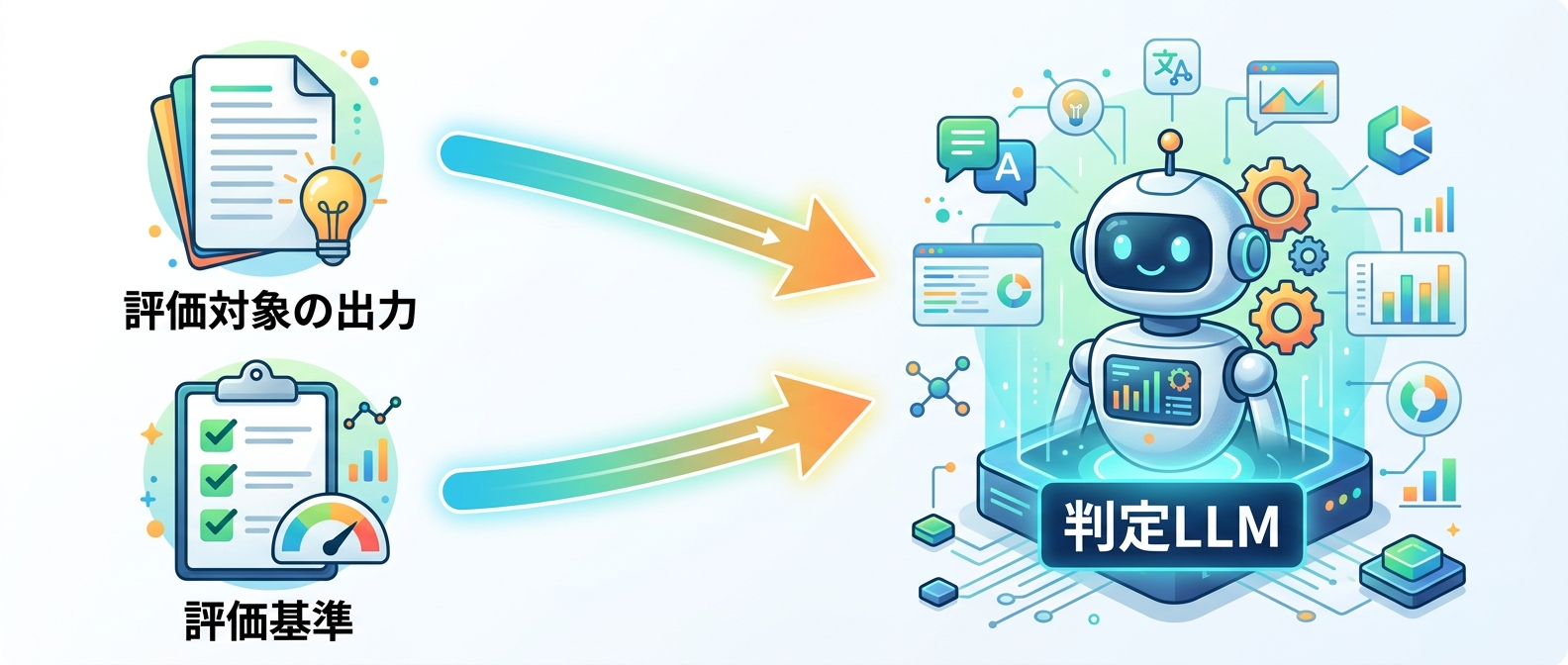
この問題を解決するのが、LLM-as-a-Judgeという手法だ。これは、LLMの出力結果が要件を満たしているかを、別のLLMに評価させる仕組みだ。
手順は以下の通りだ。
- アプリごとの要件を構造化された判定基準(Rubric)として定義する
- その判定基準と、テスト対象のLLMの出力を、評価用のLLMに渡す
- 評価用LLMに、基準を満たしているかどうかを判定させる
判定基準をプロンプトの自然言語に埋め込むのではなく、コードの外に仕様として固定することで、判定が安定する。この手法なら、文字列比較では拾えない意味的な誤りを高精度に検知できる。たとえば「通話ログに根拠のない断定を含まないこと」といった複雑な要件も、判定基準として渡すだけでテスト可能になる。回帰テストの信頼性が大幅に上がり、安心してコードの変更やプロンプトの改善ができるようになる。
しんたろー:
LLMアプリの開発において、出力のテストは本当に苦労するポイントだ。
単純な文字列比較だと、少し言い回しが変わっただけでテストが落ちて開発のテンポが悪くなる。
評価基準を明確にして別のLLMに判定させるアプローチは、工数削減の面でもかなり有効だ。
手法3:本番環境でのLLMオブザバビリティ監視
テストを通過して本番環境にデプロイした後も、油断はできない。従来のWebアプリならエラーレートやCPU使用率を見ておけばよかったが、LLMアプリではそれだけでは不十分だ。本番運用では、LLM特有の指標を監視する「LLMオブザバビリティ」が必須になる。
具体的に監視すべき指標は以下の4つだ。
- トークン数とコスト:入力長やモデルによってコストが大きく変動するため、リクエスト単位での記録が欠かせない。GPT-4oやClaude 3.5などモデルを変えるだけでコストが変わるため、用途別のコスト内訳をリアルタイムで出せる体制が必要だ
- レイテンシ(パーセンタイル):平均値ではなく、ばらつきを捉える。ユーザーの10人に1人が極端に待たされていないかを確認する
- 出力品質:ハルシネーションや、不適切な発言が含まれていないかをリアルタイムで追跡する
- 個人情報(PII)の検出:日本のサービス固有のマイナンバー(12桁、スペース区切り)など、機密情報がLLMに送信されていないかを監視する
ここで注意したいのが、既存の汎用監視ツールでこれらをすべて賄うのは難しいということだ。従来の監視はシステムが正常に動いているかを見るものだが、LLMオブザバビリティはシステムの出力が正しいかまで踏み込む必要がある。そのため、LLMに特化したオブザバビリティツールの導入を検討するのが賢明だ。
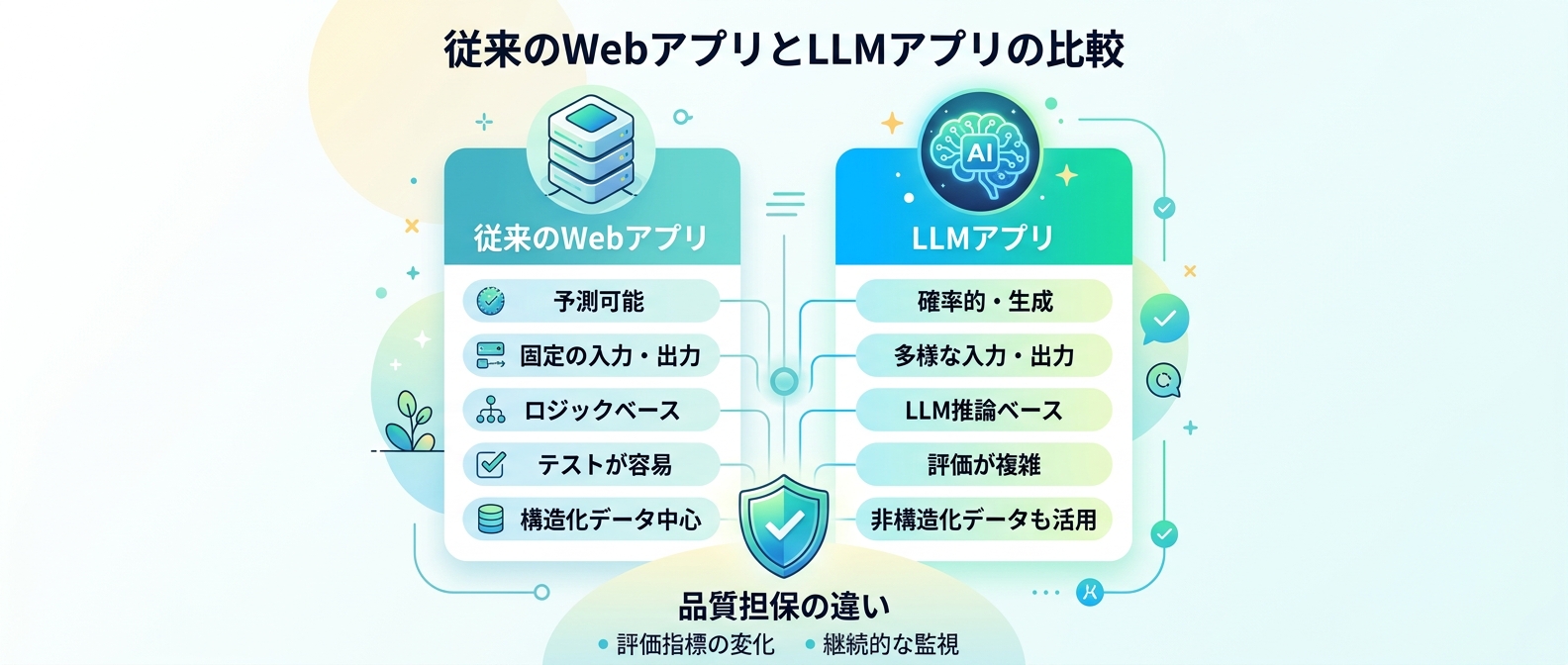
従来WebアプリとLLMアプリの品質担保の違い
ここで、従来の手法とLLM向けの手法の違いを比較表で整理しておく。
| 比較項目 | 従来のWebアプリ | LLMアプリ |
| --- | --- | --- |
| 開発時の入力 | 型定義・バリデーション | プロンプトの構造化(4要素への分割) |
| テストの合否判定 | ステータスコード、文字列の完全一致 | LLM-as-a-Judgeによる意味的な正しさの評価 |
| 本番環境の監視 | エラーレート、平均レスポンスタイム | トークンコスト、パーセンタイル遅延、出力品質、PIIの漏洩検知 |
Claude Codeで毎日コードを書いている身からすると、プロンプトの構造化が一番即効性があった。
理由はシンプルで、Claudeにタスクを投げるときに前提や制約を明確に分けるだけで、手戻りが圧倒的に減るからだ。
ちなみにLLMの専用監視ツールは色々あるが、出力の正しさまで踏み込んで監視できるかが鍵になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
LLMアプリ開発のつまずきポイント3選
ここまで解説した手法を実践する上で、初心者がハマりやすい罠を3つ紹介する。
- 指示を足しすぎてプロンプトが崩壊する
出力が思い通りにならないとき、場当たり的に条件や指示を足し続けるのは危険だ。プロンプトが長くなるほどLLMは混乱し、重要な制約を見落とすようになる。指示を足すのではなく、構造を見直すのが正解だ。
- ステータスコード200で安心してしまう
APIが正常に返ってきたからといって、出力内容が正しいとは限らない。もっともらしい嘘をついていないか、前提条件を無視していないかを、LLM-as-a-Judgeで常に疑う仕組みが必要だ。
- 平均レスポンスタイムだけを見てしまう
LLMの処理時間は入力の長さで大きくブレる。中央値が800msでも、一部のユーザーは5秒以上待たされているケースがある。必ずパーセンタイルでレイテンシを監視し、極端に遅いリクエストが発生していないかをチェックする必要がある。

よくある質問(FAQ)
Q1: プロンプトを工夫しても出力が安定しないのはなぜか?
指示の量ではなく、入力の構造が曖昧なことが原因だ。LLMは制約なく並列された指示を自由に解釈してしまうため、指示を足すほど出力がブレやすくなる。これを防ぐには、役割、前提、タスク、制約の4要素に分け、見出しで明確に分離する構造化を取り入れるとよい。構造を明示することで、LLMの解釈が一意に定まり出力が安定する。
Q2: LLMアプリのテストは、従来のWebアプリと同じ方法でできるか?
従来のWebアプリのようなステータスコードや文字列の完全一致によるテストだけでは不十分だ。LLMはシステム的なエラーを出さずに、もっともらしい嘘や前提を無視した回答を出力することがある。そのため、文字列の類似度を測るだけでなく、出力の意味的な正しさや制約の遵守度を評価する専用の仕組みをテスト工程に組み込む必要がある。
Q3: LLM-as-a-Judgeとは何か?導入するメリットは?
LLM-as-a-Judgeとは、LLMの出力結果が要件を満たしているかを、別のLLMに評価させる手法だ。従来の文字列比較では、意味は同じだが表現が違う場合を不合格にしたり、文字列は似ているが意味が逆なものを合格にする問題があった。評価基準を明確に与えてLLMに判定させることで、人間の目視に近い高精度な品質チェックを自動化できる。
Q4: 本番環境でLLMアプリを運用する際、監視すべき指標は何か?
従来のレスポンスタイムやエラーレートに加え、LLM特有の4つの指標を監視することが重要だ。モデルや入力長で変動するトークン数とコスト、ばらつきを捉えるためのパーセンタイルでのレイテンシ、ハルシネーションを防ぐ出力品質、そして日本固有のフォーマットにも対応した個人情報の検出だ。これらをリアルタイムで追跡する体制が求められる。
Q5: 既存の監視ツールでLLMアプリの監視はできるか?
トークン数やレイテンシの計測など部分的な監視は可能だが、LLM特有の要件を満たすには限界がある。従来の監視はシステムが正常に動いているかを見るものだが、LLMオブザバビリティはシステムの出力が正しいかまで踏み込む必要がある。そのため、LLM特化のツールの導入が推奨される。
まとめ
LLMアプリの品質担保は、従来のWeb開発の常識が通用しない領域だ。しかし、今回紹介した3つの手法を順番に実践すれば、確実に出力は安定し、運用リスクも下げることができる。
まずは手元のプロンプトを見出しで構造化するところから始めるべきだ。それだけでも、AIの回答精度が劇的に変わるのを実感できるはずだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
