
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIエージェントが「野放し」にされる時代の終わり
CursorがSDKの大型アップデートを正式に発表した。
AIエージェントが自律的なチームメンバーとして機能するためのアップデートだ。
今のAI開発は、プロンプトを投げて結果を待つフェーズにある。
動けば成功、壊れればプロンプトを修正する試行錯誤が続いている。
今回のアップデートで、JSONLによるログ保存とカスタムツールの統合、自動レビューの仕組みが実装された。
エージェントの挙動を数値とロジックで管理できる環境が整った。
開発者はAIを信じるだけでなく、AIを検証するフェーズへ移行している。
TypeScriptとPythonの両SDKで、エージェントの自律性は向上した。
エージェントの検証を自動化する理由を、開発者の視点で深掘りする。
Cursor SDKアップデートの全貌と「検証可能」な設計
今回のアップデートにより、エージェントの内部処理を透明化し、制御できるようになった。
主な変更点は4つだ。
第一に、カスタムツールの定義が簡略化された。
関数定義を渡すだけで、SDKが内部で自動的にMCPサーバーとして公開する。
エージェントは、記述した関数を標準ツールと同様に呼び出せる。
第二に、auto-review機能の実装だ。
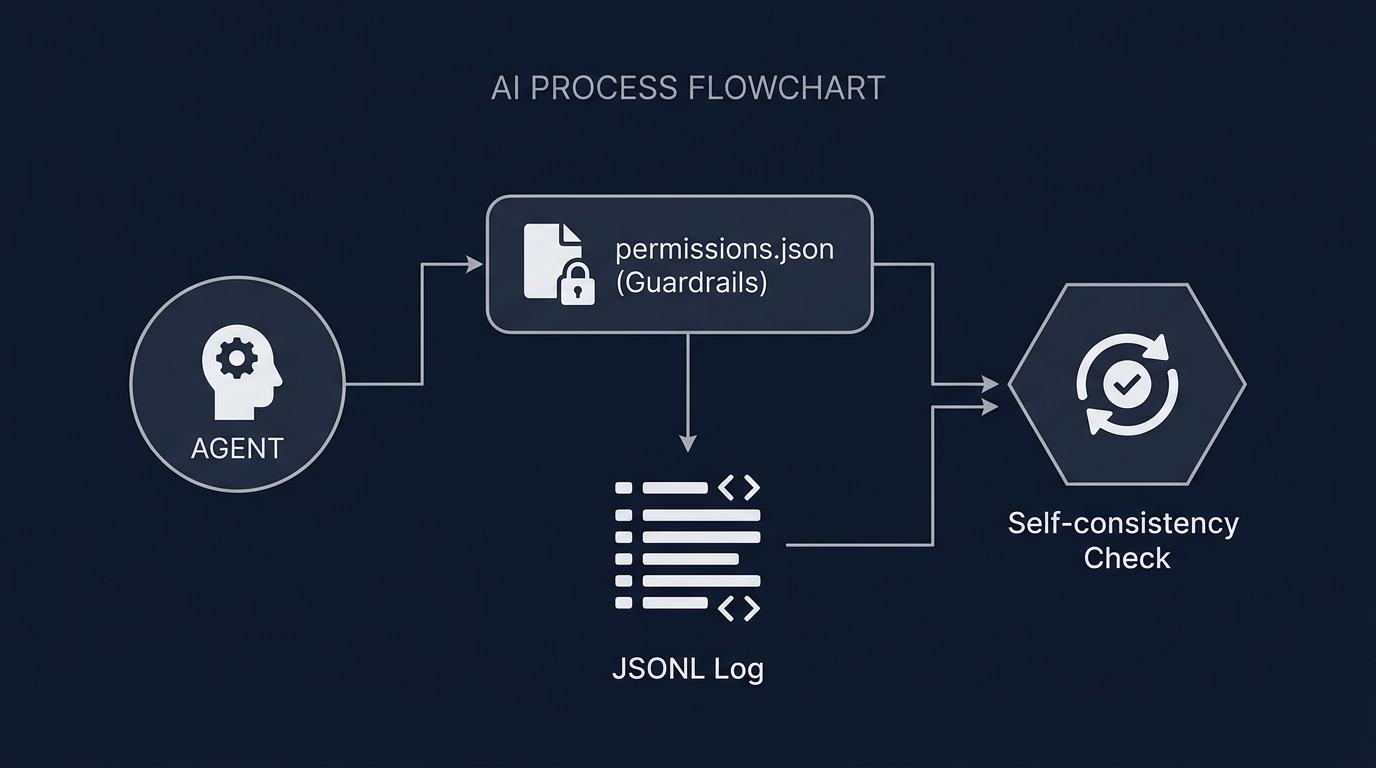
permissions.jsonという設定ファイルに自然言語で指示を記述する。
AIが実行前に「これは実行していいか」を判断する仕組みだ。
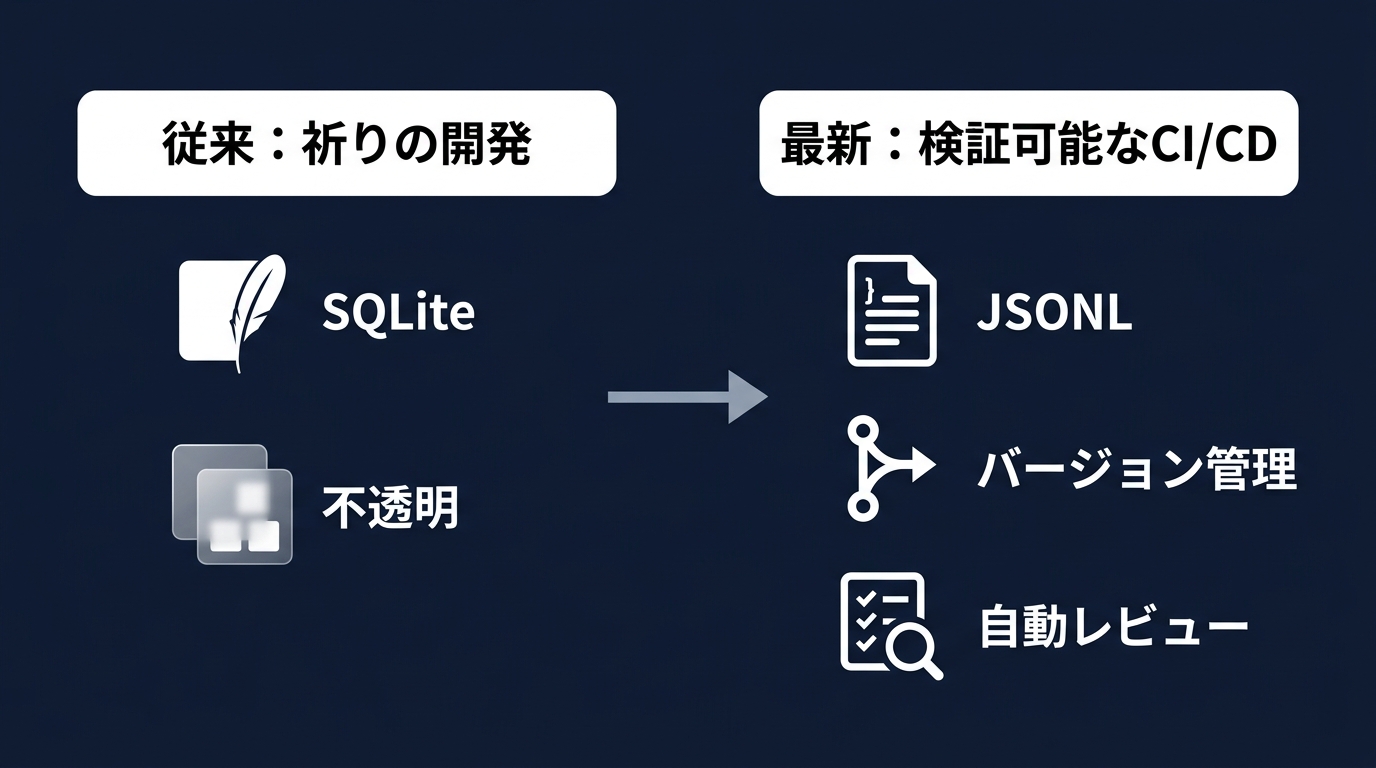
第三に、データの保存形式としてJSONLが選択可能になった。
JSONLはプレーンテキストのため、Gitで管理できる。
エージェントの思考プロセスやツール呼び出しの履歴を、diffで追跡できるようになった。
第四に、サブエージェントの無限階層化だ。
メインのエージェントがテスターを呼び出し、そのテスターがさらにドキュメント作成者を呼び出す。
複雑なタスクをチームとして処理できる構造だ。
しんたろー:
SQLiteからJSONLへの変更は、ログの追跡において大きな変化だ。
バイナリデータではGitによる履歴管理が困難だった。
JSONLであれば、CIでテストが落ちた際のログ解析が容易になる。
自身の開発でも、エージェントの透明性は重要だと感じている。
開発者は「AIの品質」をどう定義すべきか
Cursor SDKがログを出力できるようになった今、そのログを評価する指標が必要だ。
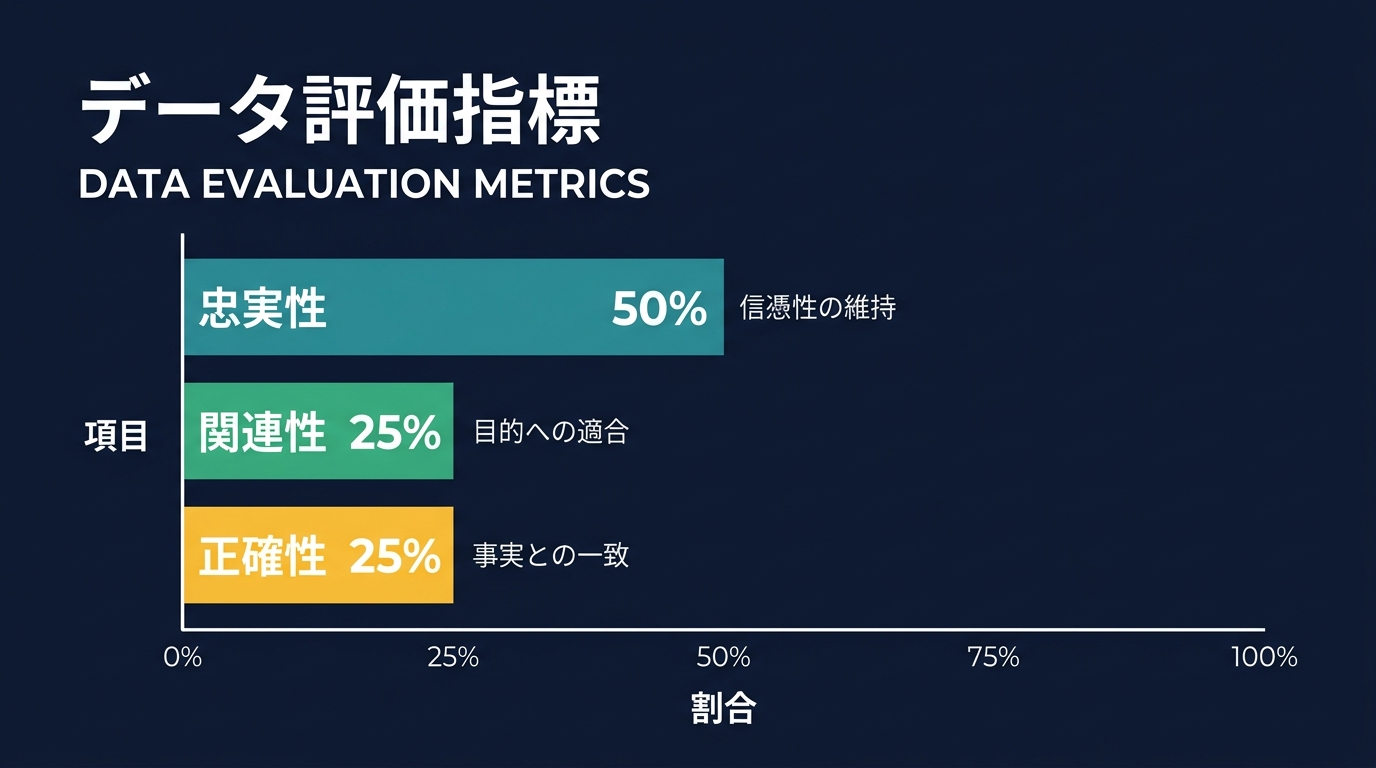
AIアプリの品質は、3つの軸で分解できる。
- 忠実性(Faithfulness): 50%
- 関連性(Relevance): 25%
- 正確性(Correctness): 25%
開発現場では、AIがもっともらしい嘘をつくハルシネーションがリスクとなる。
提供されたコンテキストやコードベースへの忠実性を最優先でチェックする。
関連性は、ユーザーの要求に対して適切なファイルやツールを選択できたかを見る。
正確性は、最終的な出力が事実として正しく、テストをパスするかだ。
Cursor SDKで出力したJSONLのログを評価フレームワークに流し込む。
評価自体もAIに行わせるLLM-as-a-Judgeという手法がある。
2026年現在の知見では、AIによる評価には偏りがあることが確認されている。
複数の評価手法を組み合わせる必要がある。
エンティティ重複率という機械的な指標を活用する。
エージェントが生成した回答に含まれる固有名詞や数値が、元のソースに含まれるかを計算する。
LLMを使わないため処理が速く、ハルシネーションを検知する保険となる。
忠実性に50%の重みを置く設計は納得感がある。
100行のコードより、勝手な仕様変更がないことの方が大規模開発では価値が高い。
Claude Codeでコードを書く際も、余計な変更がないかを監視している。
SDKアップデートで、その監視を自動化できる道筋が見えた。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
自律エージェントのCI/CDを構築する具体策
Cursor SDKを活用し、エージェントのCI/CDを構築する。
思考プロンプトやツール定義の変更に対して、精度を自動検証する環境を作る。
正解データがない場合の評価には、自己一貫性(Self-consistency)という指標を用いる。
同じ指示を複数回投げ、回答の一致を確認する。
回答がバラバラであれば、そのエージェントはタスクに対して自信がないか、プロンプトが曖昧であると判断できる。
具体的なアクションアイテムは以下の通りだ。
- ログのJSONL化: Cursor SDKのJsonlLocalAgentStoreを有効にする。
- 自動レビューの厳格化: permissions.jsonで、破壊的な操作をブロックし通知を設定する。
- 評価パイプラインの構築: 変更をプッシュするたびに、過去の成功ログと現在の挙動を比較する。
- LLM Judgeと機械的指標の併用: AIによる採点とエンティティ重複率をダッシュボードに表示する。
auto-review機能の活用は急務だ。
特定のディレクトリ以下の読み取りは許可し、削除は一時停止するといった指示を記述する。
AIをガードレールで囲うエンジニアリングへの転換だ。
エージェントに主導権を渡しすぎると、理解できないコードが積み上がる。
エージェントが何をしたのかを常に検証可能な状態にしておく。
自己一貫性のチェックは強力な武器になる。
プロンプトを修正した際、良くなったかどうかの判断に迷うことがあった。
3回試して3回とも異なるライブラリを使用するエージェントは、実戦投入を見送る。
数値に基づいた撤退判断ができるようになるのがプロの開発者だ。
エージェント開発でよくある疑問への核心回答
Q1: エージェントが勝手にコードを書き換えるのが怖いのですが、どう防げばいいですか?
A1: Cursor SDKのauto-review機能を活用してください。
permissions.jsonのautoRun.block_instructionsに、破壊的な操作をブロックする指示を記述します。
例えば、「ファイルの削除操作は全て一時停止せよ」といった指示です。
実行ログをJSONLで保存し、Gitで差分を確認する運用を徹底してください。
Q2: エージェントの評価に正解データがない場合、どうすればいいですか?
A2: 自己一貫性と機械的指標を組み合わせてください。
同じプロンプトに対して複数回実行し、回答の一致率をスコア化します。
加えて、回答内に含まれる関数名や変数が、実際にプロジェクト内に存在するかをチェックするエンティティ重複率を算出してください。
過去の挙動からの乖離や論理的な矛盾を探すのが実務的な評価のコツです。
Q3: Cursor SDKのカスタムツール機能は、MCPサーバーを立てるのと何が違いますか?
A3: 最大の利点はオーバーヘッドの削減です。
Agent.createの際にlocal.customToolsに関数を渡すだけで、SDKが内部で自動的にMCPのインターフェースを生成します。
開発者は通信ではなくロジックに集中できます。
複数のプロジェクトでツールを共有したい場合は、独立したMCPサーバーを構築する方が再利用性は高くなります。
検証可能な開発環境が、AIの真価を引き出す
Cursor SDKのアップデートは、管理を求めている。
JSONLによるログの透明化、auto-reviewによるガードレール、3つの軸に基づいた品質評価だ。
これらを組み合わせることで、AIエージェントは実験道具から生産ツールに変わる。
AIが何をやっているか分からないという状況を、エンジニアリングの力で検証可能なプロセスに変える。
Claude CodeとCursorを使いながら、評価パイプラインを磨き続ける。
最後にコードの責任を持つのは人間だ。
検証のための武器は、持てるだけ持っておく。
エージェントの野放し運用を卒業し、堅牢な開発環境を構築する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ

なぜClaude Codeはプロンプト一発回答をやめたのか。開発者が対話で思考を深めるべき訳を徹底解説

Claude Codeで開発を自動化する鍵は検証ゲートの設計にある

CursorのDesign ModeでUI操作が自動化。サブエージェント設計への移行

【2026年版】レガシーシステムを刷新する仕様駆動開発|導入ステップ5選
