
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
魔法のプロンプトなんて、最初からなかった。
プロンプトエンジニアリングは終わった。
一発で完璧なコードを出そうとする試みは、開発効率を下げる要因だ。
AI開発の最前線は、「対話による思考の収束」と「ローカル環境でのハードウェア最適化」という、泥臭い両極端へシフトしている。
僕らが求めていたのは「答えを出す機械」ではなく、「一緒に悩んでくれる思考のパートナー」だった。
この変化の正体と、開発者がどう動くべきか、その全てを解体する。

AIは「道具」から「思考の揺らぎ」を整える存在へ
Claude Codeのアップデートには、明確な意思がある。
「AIに一発で正解を出させるな」というメッセージだ。
多くの開発者が、短いプロンプトで正確なコードを書かせることに心血を注いできた。
しかし、手に入れたのは「意図とズレているコード」の山だった。
この違和感は、AIを「入力に対して出力を返す関数」として扱っていたことに起因する。
AIの本質は、そこにはない。
整理されていない思考や、言葉にならない違和感を投げ込み、AIとの対話を通じて自分の考えを組み直すプロセスに価値がある。
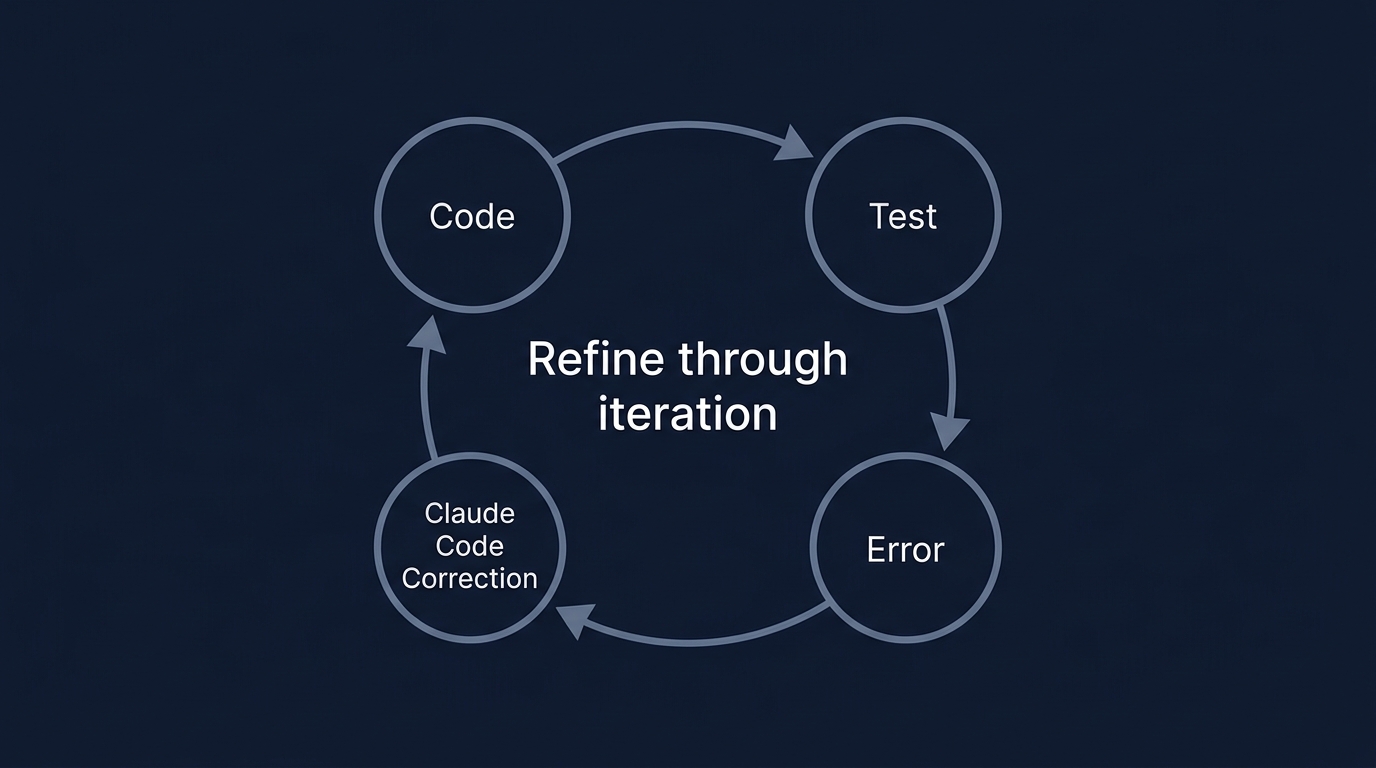
Claude Codeがローカル環境でファイルを読み込み、テストを実行し、エラーが出れば即座に修正案を出すのは、この反復プロセスを高速化するためだ。
最新の動向から、以下の3つの事実が浮かび上がる。
- プロンプトの精度よりも、対話の回数が重要になった。
- AIは「正解」を出すツールではなく、思考を「収束」させるための壁打ち相手になった。
- ローカル環境でAIを動かす際、ソフトウェアの知識だけでなく、ハードウェアの演算効率を理解する必要がある。
Apple Siliconを搭載したMacでの開発環境において、この傾向は顕著だ。
Qwen2.5のようなモデルがローカルで実用レベルに達し、128GBの統合メモリを持つM4 Maxなら、70Bクラスのモデルも手元で動く。
単にモデルを動かすだけでは不十分だ。
ANE(Apple Neural Engine)のような、行列演算に特化したハードウェアを使い切る必要がある。
そこには、0.1ms単位のオーバーヘッドを削り、演算を融合させる「低レイヤーの戦い」が存在する。
しんたろー:
プロンプトをこねくり回していた時期が懐かしい。
今はClaude Codeに「この辺の挙動が気になる」と投げ、返ってきたコードに「いや、そうじゃない」と言い返す。
人間同士のペアプロと同じだ。
1回で伝わるわけがない。
5回やり取りすれば、自分でも気づかなかった正解に辿り着く。
この「思考の収束」を体験すると、一発回答には戻れない。
開発者が直面する「思考のdispatch」と「演算のfusing」
なぜ今、対話が重要なのか。
それは、思考が「非線形的」だからだ。
最初に「こんな機能が欲しい」と思った瞬間、仕様の90%は霧の中にある。
AIに一発で書かせようとするのは、霧の中に向かって全力疾走するようなものだ。
対話を重ねることで、AIが霧を晴らし、思考を「収束」させてくれる。
技術的な側面では、この「対話」を支えるためのハードウェア最適化が重要だ。
例えば、MacでローカルLLMを動かす際、MLXというフレームワークが使われる。
しかし、MLXはMetal GPUのみを使用し、19 TFLOPSの演算能力を持つANEを無視している。
ここには対比がある。
高レイヤー(思考レベル)では、対話の回数(dispatch)を増やして精度を高める。
低レイヤー(ハードウェアレベル)では、実行の回数(dispatch)を減らして、演算を融合(fusing)させる。
ハードウェアの世界では、1回の演算命令ごとに、CPUとアクセラレータの間で同期が発生し、データ転送のオーバーヘッドが積み重なる。
この固定コストは約0.1msだ。
1つの演算が速くても、このオーバーヘッドが全てを台無しにする。
複数の演算を1つのプログラムにまとめ、SRAM内で処理を完結させることが、極限のパフォーマンスを引き出す鍵になる。
これはAIとの対話にも似ている。
細切れに指示を出すのではなく、ある程度の文脈(context)を共有し、AIの中で思考を「融合」させる。
Claude Codeが、単なるチャットUIではなく、ディレクトリ構造やテスト結果までを一度に把握しようとするのは、まさにこの「思考の演算融合」を行っているからだ。
ANEを直接叩いて行列演算を高速化する検証データを見た。
転送コストが計算速度を上回ってしまう絶望感がある。
でも、演算をまとめれば逆転できる。
これは、AIに指示を出す時の感覚に似ている。
情報を小出しにするとAIは混乱するが、適切な塊で渡せば、中で勝手に関連性を見つけ出してくれる。
ハードもソフトも、脳も、最適化の原理は同じだ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
開発スタイルをどう変えるべきか
この「対話による収束」と「ハードウェア最適化」の流れを受けて、実践すべきアクションは明確だ。
まず、「プロンプト一発で正解を出そうとする自分」を捨てること。
AIの回答が気に入らなければ、プロンプトを書き直すのではなく、「その前提は違う」「もっと具体的にこうしたい」と、AIにツッコミを入れ続ける。
AIは、ツッコミを糧にして、思考の文脈を学習する。
2回、3回とラリーを続けることで、回答の精度は二次関数的に向上する。
次に、ローカル環境を「AIファースト」に再構築すること。
API経由のAIは手軽だが、本当の意味での「思考のパートナー」にするには、ローカルでの実行速度が重要になる。
M4チップ以降のMacを使っているなら、Qwen2.5-Coderのようなモデルをローカルで動かし、Claude CodeのようなCLIツールと組み合わせる。
コードを書いて、テストを回し、エラーをAIが読み取り、また修正する。
このループが1秒以内に回る環境を作ることが、2025年以降のエンジニアの条件になる。
そして、「低レイヤーへの関心」を失わないこと。
AIがコードを書いてくれる時代だからこそ、裏で動いているハードウェアがどうデータを処理しているのか、という知識が差別化要因になる。
メモリ転送のボトルネック、演算のオーバーヘッド、量子化による精度の劣化。
これらを理解していれば、AIが出してきたコードの「筋の良さ」を、直感ではなく論理的に判断できる。
AIに全部任せるのは無理だ。
AIのおかげで「自分が何を考えているのか」を厳密に定義する必要が出てきた。
泥臭い対話と、泥臭いハードウェアの最適化。
両方を面白がれる者が勝つ。
ThreadPostの開発で、毎日Claude Codeと向き合い、Macのファンが回る音を聞いている。
これが現代の「ものづくり」だ。
FAQ
Q1: プロンプトを工夫してもAIの回答が納得できない場合、どうすべきか?
プロンプトの書き方を改善するのではなく、AIとの対話回数を増やしてください。
AIは一度の指示で完璧な答えを出すツールではなく、思考を整理し、ズレを修正するためのパートナーです。
「その前提は違う」「もっとこう考えて」と対話を重ねることで、AIは思考の文脈を理解し、最終的な回答の精度が収束していきます。
一発で正解を求めるのをやめた瞬間、AIは格段に使いやすくなります。
Q2: ローカルLLMを動かす際、なぜApple SiliconのANEを直接叩く必要があるのか?
標準のMLXフレームワークはMetal GPUのみを使用し、ANE(Apple Neural Engine)を活用していません。
ANEは行列演算に特化した低消費電力アクセラレータであり、適切に演算を融合(fusing)してdispatch回数を減らせば、推論速度や電力効率を改善できるためです。
特にモバイル環境や、バックグラウンドで常にAIを動かし続けるユースケースでは、電力効率と速度の両立が重要になります。
Q3: AI開発において、ハードウェアの知識はどれほど重要か?
API経由でモデルを使うだけなら不要ですが、ローカルLLMの運用や推論の高速化を目指すなら必須です。
特にメモリ転送コストや演算のオーバーヘッドを理解していると、モデルのサイズ選定や実装方針の判断が変わります。
高レイヤーの対話設計と低レイヤーのハードウェア最適化、この両輪を理解することが、単なる「AI利用者」から「AIエンジニア」へとステップアップするための強みになります。
最後に。
AIは魔法の杖ではない。
思考を拡張し、形にするための、高度な「鏡」だ。
鏡を覗き込み、対話を続け、その裏側にある仕組みを理解しようとする者だけが、この新しい開発体験を自分のものにできる。
プロンプトを磨くのはやめて、AIとの本当の会話を始めよう。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ

Claude Codeで開発を自動化する鍵は検証ゲートの設計にある

【速報】CursorがSDKとJSONL保存を正式発表。AIエージェントの検証を自動化する開発手法

CursorのDesign ModeでUI操作が自動化。サブエージェント設計への移行

【2026年版】レガシーシステムを刷新する仕様駆動開発|導入ステップ5選
