
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
LLMが「会話相手」から「システムの部品」になった
500万本のニュース記事を読ませて、洪水予測モデルを作った。
これがGoogleの最新AI活用の現実だ。
Gemini 3.1 ProとDeep Thinkの進化が示しているのは、モデルの性能向上だけじゃない。LLMがシステム設計の「コンポーネント」として機能し始めたという、アーキテクチャレベルのシフトだ。
開発者として、これは無視できない。
Googleが2月に動かしたこと — 3つの事例から見える本質
2月のGoogleのAI発表は、大きく3つの柱で整理できる。
1. Gemini 3.1 Pro + Deep Thinkのアップグレード
Gemini 3.1 Proが大型アップデートを受けた。複雑なタスクへの対応力が強化され、Google全プラットフォームで展開されている。同時にDeep Thinkという推論強化モードも進化。単純な質問応答ではなく、「長い推論チェーンを必要とする複雑な問題」への対応を前提に設計されている。
さらにNano Banana 2が登場した。「Proの画像品質 × Flashの速度」というコンセプト。GeminiやGoogle検索の画像生成機能に組み込まれ、レイテンシを抑えながら高品質な出力を実現する。
2. ニュース記事500万本から洪水予測データセットを構築
フラッシュフラッドは年間5,000人以上の死者を出す気象現象だ。発生が局所的かつ短時間なため、従来の気象センサーでは観測データが蓄積しにくい。深層学習モデルを訓練しようにも、「データがない」という根本的な問題があった。
Googleのリサーチチームが取ったアプローチはこうだ。Geminiを使って世界中のニュース記事500万本を解析。そこから260万件の洪水報告を抽出し、「Groundsource」という地理タグ付き時系列データセットに変換した。
このデータセットを使ってLSTM(Long Short-Term Memory)ニューラルネットワークを訓練し、フラッシュフラッド発生確率を予測するモデルを構築。現在は150カ国の都市部でリスク情報を提供し、緊急対応機関にデータを共有している。
3. Aletheia — 数学研究を自律的に行うAIエージェント
Google DeepMindが発表したAletheiaは、競技数学から「プロの研究」レベルへの橋渡しを目指すAIエージェントだ。2025年のIMO(国際数学オリンピック)で金メダル水準を達成したモデルをベースに、長期的な証明構築と文献調査を自律的にこなす。
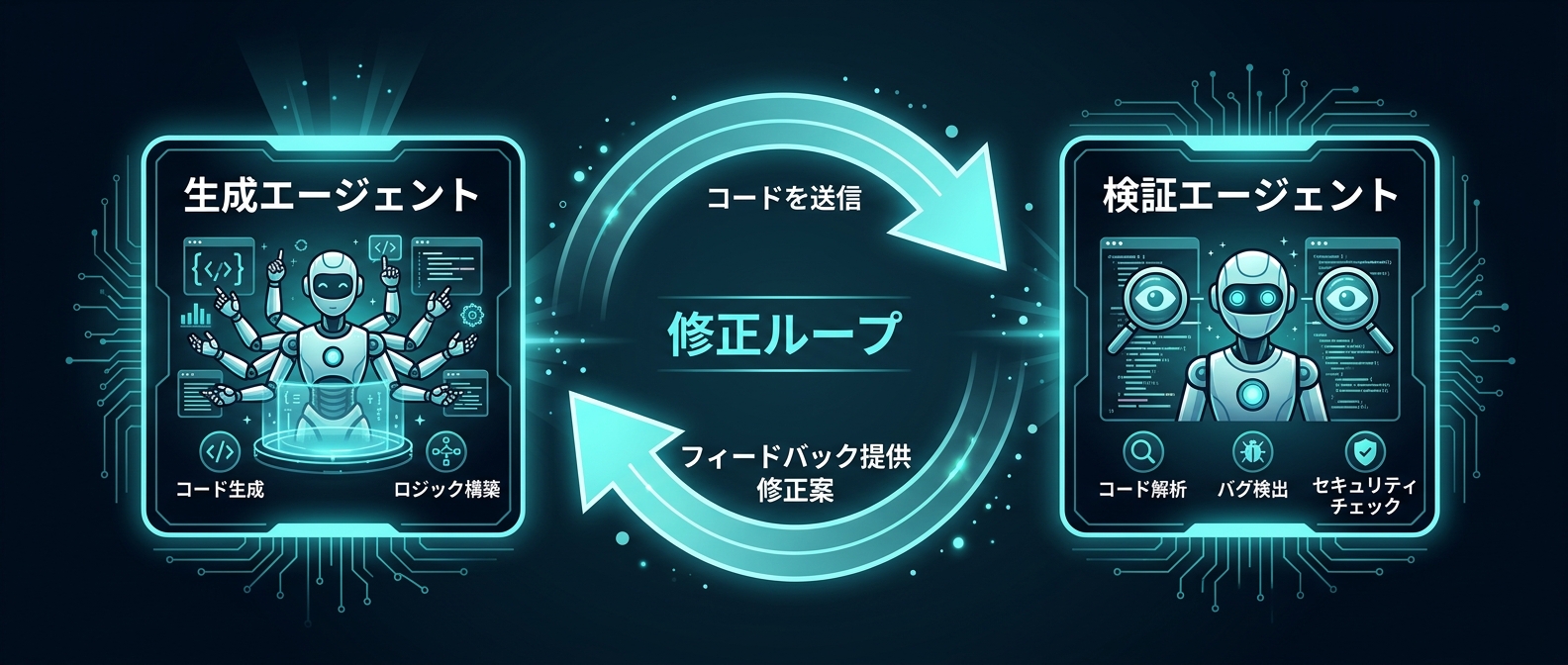
Aletheiaは「生成」「検証」「修正」の3ステップを反復するアーキテクチャを採用。この設計思想が、後述する開発者への示唆として非常に重要になる。
しんたろー:
洪水予測の話、最初は社会貢献系の話かと思って読み進めたら全然違った。
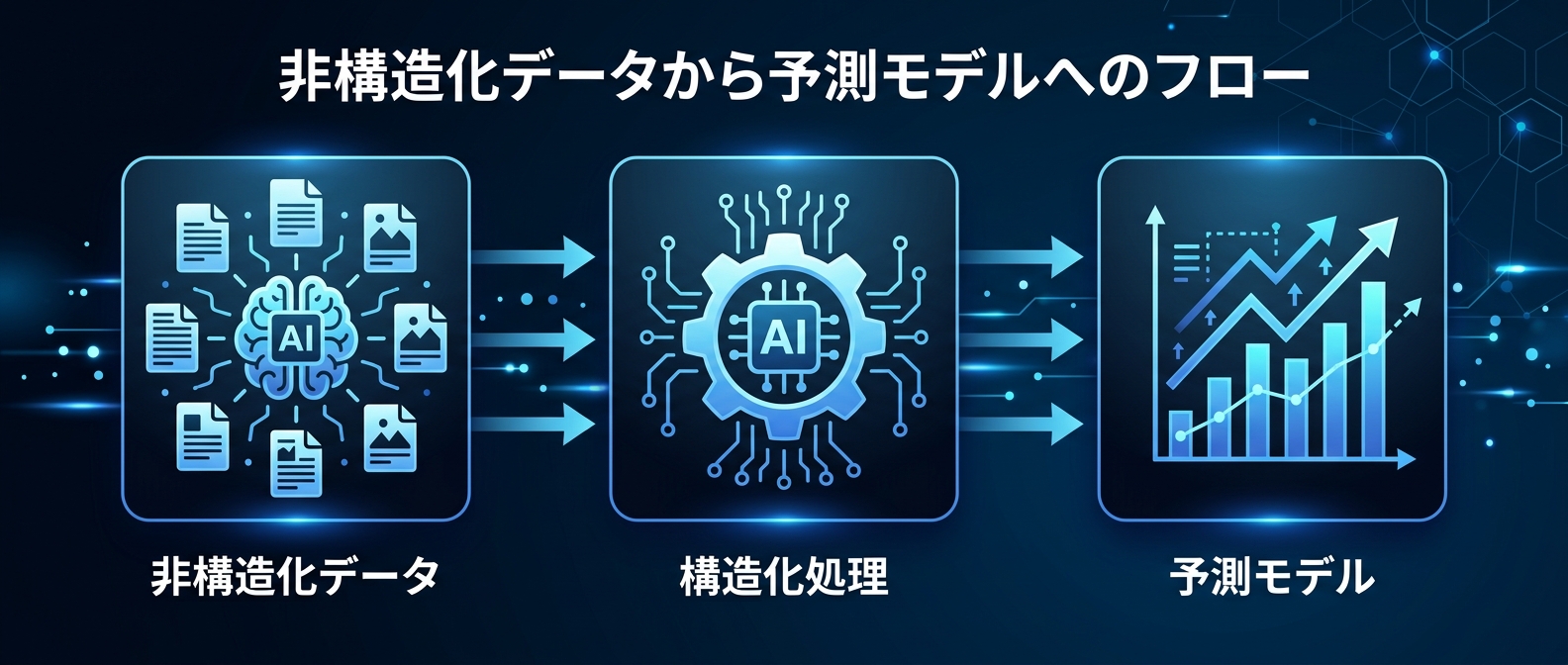
LLMで非構造化テキストを構造化データに変換して、別の機械学習モデルの学習データにする——これ、普通に汎用的なアーキテクチャパターンだ。「データがない」問題を「LLMで既存テキストから作る」で解決する発想、気になってる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
「LLMをコンポーネントとして使う」設計思想に切り替えるとき
今回の3事例を並べると、共通する設計思想が見えてくる。
LLMはチャットボットの裏側じゃない。データパイプラインの処理エンジンだ。
洪水予測の事例を分解すると、こういう構成になっている。
- 入力: 非構造化テキスト(ニュース記事500万本)
- 処理: Gemini(構造化 + 地理タグ付け + 時系列変換)
- 出力: 構造化データセット(Groundsource)
- 次の処理: LSTMモデルの学習データとして投入
LLMは「答えを出す」ために使われていない。「データを変換する」ために使われている。
Aletheiaの設計はもっと示唆が深い。
「生成と検証の分離」——これがAletheiaの核心だ。単一のプロンプトで「ステップバイステップで正しい答えを出せ」と指示するのではなく、システムレベルで役割を分ける。
- 「回答を生成するLLM」
- 「その回答の論理的欠陥を指摘するLLM」
- 「指摘を受けて修正するLLM」
この3役を明示的に分離することで、モデルが「自分の間違いを自己正当化するバイアス」を防ぐ。生成したものを自分で検証させると、「なんとなく正しく見える」になりやすい。外部の目で見ることで、欠陥が浮かび上がる。
Claude Codeで毎日コードを書いている身として、これは直接関係する話だ。
コード生成後のテスト・修正ループを「生成エージェント」と「検証エージェント」で分けて設計する発想。Claude Codeのような自律型コーディングエージェントでも、この「agentic harness」的な設計を意識するかどうかで、出力の信頼性が変わってくる。
Nano Banana 2の話も、表面的なスペック以上の意味がある。
「Proの品質 × Flashの速度」は単なるマーケティングコピーじゃない。これまで「高品質な画像生成 = 高レイテンシ + 高コスト」だったトレードオフが崩れつつあることを示している。リアルタイム性が求められるアプリケーションで画像生成機能をスケールさせるコストが、設計上の前提から変わってくる。
Googleが「AIの民主化」を訴えながら、実際の高度な事例は専門的なシステム設計を要求している、という矛盾も見えてくる。
インドのAI Impact Summitで「誰もがAIの恩恵を受けられる」と語る一方、洪水予測もAletheiaも、汎用モデルをそのまま使うだけでは実現できない。LSTMとの組み合わせ、マルチエージェントワークフローの設計、ドメイン特化のデータパイプライン——全部必要だ。「使える人が増える」と「高度な使い方が複雑になる」は、同時に進行している。
Aletheiaの「生成と検証を分離する」設計、Claude Codeで作業してると自然にやりたくなる構成だと思った。
コード生成させて、そのままテスト書かせると、テストが生成コードに忖度し始めることがある。「生成したコードを知らないエージェントが仕様書からテストを書く」みたいな分離、うちの構成でも試してみたいと思ってる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響 — 今の開発設計で変わる3つの視点
今回の発表を踏まえて、開発者として意識しておきたいことを整理する。
① 「LLMをデータ変換器として使う」パターンを設計に組み込む
社内に眠っている非構造化テキストは、ほぼ全員が持っている。
営業日報、カスタマーサポートのチャット履歴、業界ニュースのスクラップ——これらはこれまで「検索できない資産」だった。
LLMを「テキストから構造化データへの変換エンジン」として使うことで、既存の機械学習モデルの学習データを作れる。Googleがやったことのスケールダウン版は、自社データで十分に実現できる。
具体的には:
- 過去のサポートチケットから「問題カテゴリ」「解決時間」「ユーザー感情スコア」を抽出
- 営業日報から「商談ステータス」「競合言及」「次のアクション」を時系列データ化
- 社内ドキュメントから「意思決定ログ」を構造化してベクトルDB化
② 「生成と検証の分離」をワークフロー設計の基本原則にする
単一のLLMに「生成して検証して修正して」を全部やらせるのは、設計として弱い。
Aletheiaが示したように、役割を分離することで信頼性が上がる。
実務での応用:
- コード生成エージェントと、コードレビューエージェントを別プロンプト/別モデルで設計
- 文章生成エージェントと、ファクトチェックエージェントを分ける
- 提案生成エージェントと、リスク指摘エージェントを分ける
「同じモデルに自己チェックさせる」から「役割分担させる」への移行だ。
③ 画像生成機能のコスト前提を見直す
Nano Banana 2の登場で、「画像生成はコストが高いから後回し」という判断が変わる可能性がある。
プロダクトのUXに画像生成を組み込む際のコスト試算は、最新のモデルスペックで再計算する価値がある。
注意点として:
- 150カ国対応の洪水予測モデルでも「20平方キロメートル単位の解像度」という限界がある。LLMを組み込んでも、精度の上限はデータ品質と設計次第だ
- 「LLMが得意な変換処理」と「従来のMLが得意な予測処理」を組み合わせる設計が現実的だ
- マルチエージェント設計はコストが増える。生成と検証を分離すると、API呼び出し回数が増える。コストと精度のトレードオフは必ず計算する
「生成と検証を分離するとAPI呼び出し回数が増える」問題、これは地味に痛い。
Aletheiaみたいな研究用途なら精度最優先でいいけど、プロダクションでは「どこまで分離するか」のバランスが気になってる。Nano Banana 2みたいにコストが下がる方向と、マルチエージェントでコストが上がる方向が同時に来てる。財布が泣いてる。
よくある質問
Q1. LLMを使ってテキストからデータセットを作る手法は、自社の業務に応用できますか?
応用できる。特に「過去のテキストデータが大量にあるが、構造化されていない」という状況に有効だ。
ポイントは「LLMに何を抽出させるか」を明確に定義することだ。洪水予測の事例では「洪水の発生場所」「日時」「規模」という抽出項目が明確だった。自社業務に応用する場合も、まず「何を構造化データとして取り出したいか」を先に決める。
カスタマーサポートの履歴なら「問題カテゴリ」「解決時間」「再発率」。営業日報なら「商談フェーズ」「競合言及の有無」「次のアクション」。抽出項目が曖昧だと、LLMの出力もブレる。
精度の上限はデータ品質に依存する。元のテキストが曖昧なら、構造化後のデータも曖昧になる。LLMは「ない情報を作り出す」ことはできない。
Q2. Aletheiaの「生成と検証の分離」は、通常のプロンプトエンジニアリングとどう違いますか?
根本的に違う。通常のプロンプトエンジニアリングは「1つのモデルに良い答えを出させるための指示設計」だ。「ステップバイステップで考えて」「自分の回答を確認して」という指示も、同じモデルが同じコンテキストで処理している。
Aletheiaが採用した分離は、システム設計レベルの話だ。「回答を生成するLLM」と「その回答の欠陥を指摘するLLM」は、別のプロセスとして動く。生成側は検証側の存在を知らない状態で動作する。
この分離が重要な理由は「自己正当化バイアス」を防ぐためだ。同じモデルが生成と検証を両方やると、「自分が生成したものは正しいはず」という方向にバイアスがかかりやすい。外部の視点を持つ検証エージェントを置くことで、このバイアスを構造的に排除できる。
実装コストは上がるが、信頼性が求められる用途では有効な設計だ。
Q3. Nano Banana 2の「Proの品質とFlashの速度」は、開発のどこに影響しますか?
主に「画像生成機能を組み込む際のコスト試算」と「UX設計の前提」に影響する。
これまで高品質な画像生成をリアルタイムで提供しようとすると、レイテンシとコストの両方がボトルネックになっていた。ユーザーが操作するたびに画像を生成するようなUXは、コスト的に現実的でなかったケースも多い。
Nano Banana 2がFlash並みの速度でPro品質を出せるなら、この前提が変わる。「画像生成は非同期で、結果を後で表示する」という設計から、「操作に連動してリアルタイムで生成する」設計が現実的なコスト範囲に入ってくる可能性がある。
ただし、実際のAPI料金と処理時間は自分で検証する必要がある。「Proの品質 × Flashの速度」がどのベンチマークで測られているかを確認してから、プロダクションへの組み込みを判断するのが正しい順序だ。
まとめ — LLMを「部品として設計する」時代
500万本の記事から260万件の洪水データ。150カ国のリスク情報。IMO金メダルから自律的な数学研究へ。
Googleが2月に動かしたことの本質は、「モデルが賢くなった」じゃない。「LLMをどうシステムに組み込むか」の設計パターンが、実世界の複雑な問題に適用され始めた、ということだ。
チャットボットを作るだけなら、今のLLMで十分すぎる。「データ変換エンジン」「推論ループのコア」「生成と検証の分離」——この設計思想を持てるかどうかが、次の差になる。
LLMをシステムの部品として使う設計、自律エージェントのアーキテクチャ、データパイプラインへの組み込み方——こういうテーマで話したい人は、ThreadPostにいる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
