
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
演算特化の怪物がもたらすインフラの地殻変動
AIモデルの裏側で、ハードウェアの覇権争いが起きている。
主役はGoogleの独自チップであるTPUだ。
最新世代のTPUは、121エクサフロップスの計算能力を叩き出す。
帯域幅は前世代の2倍だ。
これはAI開発のコスト構造を覆すゲームチェンジャーだ。
開発者はCUDAエコシステムの汎用性と、TPUのコストパフォーマンスの選択を迫られている。
10年の熟成が生んだ「数学特化」のハードウェア
AIモデルを動かす処理は、巨大な行列演算の繰り返しだ。
Googleは10年以上前から、この計算に特化したチップを設計してきた。

汎用的なGPUとは設計思想が異なる。
TPUはAIモデルの実行のみを目的とする。
無駄を削ぎ落とすことで、電力効率が向上する。
電力効率はクラウドの利用料金に直結する。
最新世代のTPUは、データ転送の帯域幅も強化された。
AIモデルの巨大化に伴うチップ間のボトルネックを解消する。
帯域幅の2倍化は、チップの待ち時間を半分にする。
計算ユニットは常にフル稼働する。
これが121エクサフロップスという数字の裏付けだ。
実際のAI学習ワークロードで高いスループットを記録する。
GoogleはTPUを自社サービス基盤として活用する。
検索、翻訳、大規模言語モデルの裏側にはTPUのクラスターがある。
自社開発と自社設計の垂直統合が、最新世代で臨界点に達した。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
汎用性か特化型か。アーキテクチャの分岐点
TPUの進化は、開発インフラ選定に影響を与える。
NVIDIAのGPUは、AI開発の標準インフラだ。
CUDAというソフトウェアエコシステムが開発者を囲い込む。
PyTorchのコードは、環境を選ばず動作する。
対するTPUは、Google Cloud環境での最適化を前提とする。
特定のハードウェアとクラウド環境に結びついている。
しんたろー:
汎用性と引き換えに極限のパフォーマンスを取るアプローチが気になる。
ベンダーロックインの懸念と背中合わせになるのがインフラ選定の悩みどころだ。
本番環境の移行を考えると胃が痛くなる。
制約を受け入れる見返りがTPUにはある。
大規模なTransformerモデルを学習させる場合、コストパフォーマンスの差は明確だ。
TPUは、JAXとの組み合わせで真価を発揮する。
数学的な計算の最適化がハードウェアの限界まで行われる。
GPU向けのコードをそのまま動かしても速度は出ない。
TPUの行列演算ユニットに合わせて、データパイプラインや並列化を設計し直す必要がある。
これは新たな学習コストだ。
インフラ費用の圧縮を優先するフェーズでは、このコストを払う選択肢が生まれる。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
インフラ抽象化レイヤーとAIコーディングの未来
ソフトウェア側の抽象化も進んでいる。
PyTorchやJAXのバックエンドが、ハードウェアの差異を吸収する。
開発者は、基盤となるチップがGPUかTPUかを意識しなくて済むようになる。
コードの記述レベルで共通化が進み、コンパイラが最適化を行う。
ここでClaude CodeのようなAIエージェントが機能する。
AIがコードを書く時代において、インフラの最適化は変化する。
AIエージェントは、インフラの特性を理解した上でコードを生成する。
「このモデルはTPUで学習させるから、JAXでXLAコンパイラに最適化されたコードを書いて」という指示が可能だ。
Claude Codeにインフラの制約を投げてコード生成させるのは実用的だ。
人間が仕様書を読み込んでチューニングする作業は減っていく。
「どのインフラを選ぶか」という意思決定が人間の仕事になる。
ハードウェア特有の作法や、並列化の記述はAIが引き受ける。
開発者の役割は、コードを書くことからアーキテクチャを設計することへシフトする。
TPUの登場は、このシフトを加速させる。
インフラの選択肢が増えることで、アーキテクチャ設計の重要性が増す。
特定のハードウェアに依存しないコードベースを維持しながら、性能を限界まで引き出す。
この要求を解決するのが、AIエージェントとコンパイラ技術だ。
インフラ選定がもたらす開発速度とコストのトレードオフ
プロジェクトのフェーズと規模によって正解は変わる。
初期のプロトタイピングや、既存モデルのファインチューニングなら、GPUが適している。
トラブルシューティングの情報が多く、開発スピードが落ちない。
CUDAエコシステムの恩恵を最大限に受けられる。
独自の巨大モデルをスクラッチで学習させるフェーズでは状況が変わる。
インフラのコストが、プロジェクトの存続を左右する。
ここでTPUの導入が選択肢として浮上する。
コードの書き換えコストや、Google Cloudへの移行コストを計算に入れても、費用対効果が高いケースが多い。
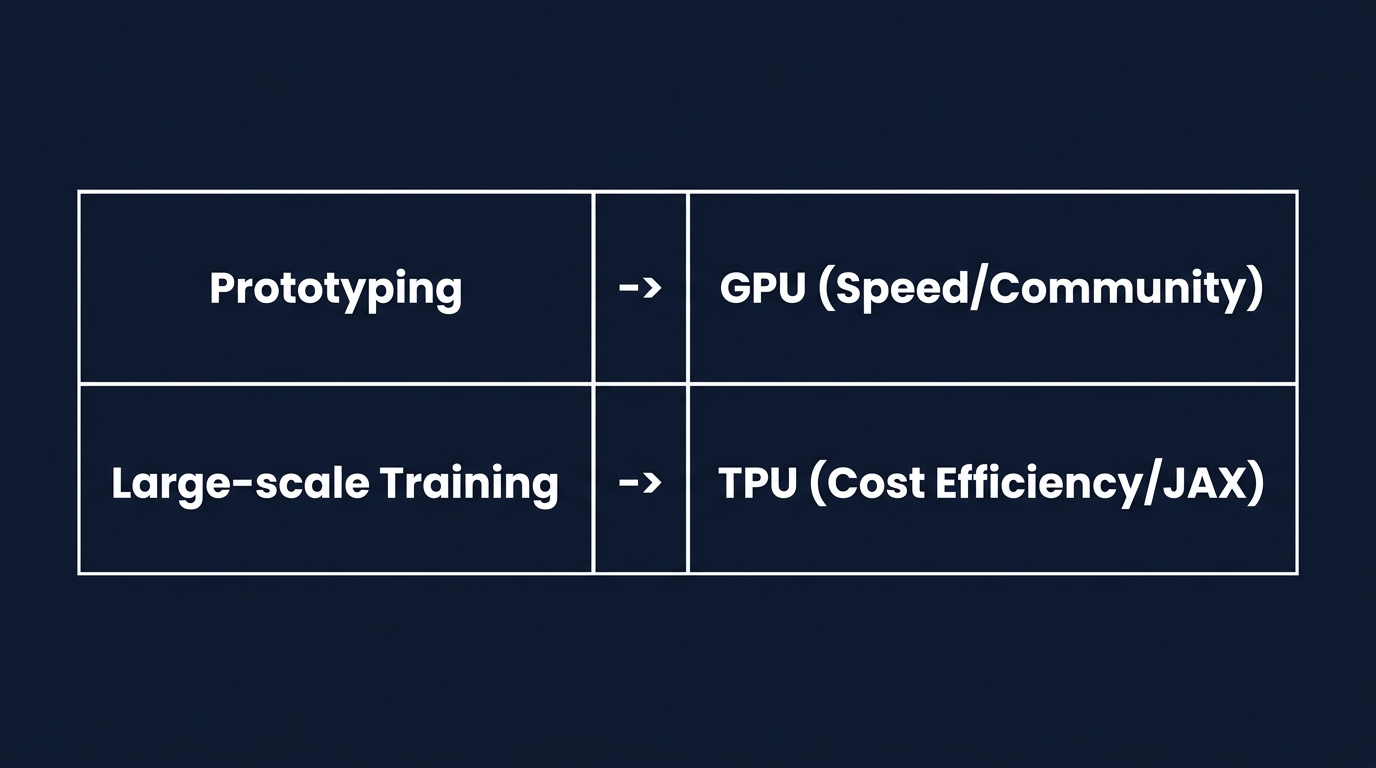
最初からどちらか一方に決め打ちしないことが肝要だ。
将来的なインフラ移行を見据えて、コードの抽象度を保つ。
特定のハードウェア特有のハックを、ビジネスロジックに混ぜ込まない。
データの前処理、モデルの定義、学習ループを明確に分離する。
ハードウェアが進化するほど、ソフトウェアの設計力が問われる。
クラウドプロバイダーは、自社製チップの開発に投資を続けている。
NVIDIAへの依存を減らし、インフラのコスト競争力を高めるためだ。
計算資源の価格破壊が起きれば、より強力なAIモデルを個人でも動かせるようになる。
インフラの進化は開発者の選択肢を増やす。
自分のプロジェクトのボトルネックが「金」なのか「時間」なのかを見極める必要がある。
僕は今の環境で動くものを最速で作ることに全振りしている。
TPUは、価格破壊の先陣を切る存在だ。
演算特化という設計が、AI開発の常識を変えようとしている。
この変化を見極め、プロジェクトに最適なインフラを選び取る必要がある。
AIの進化は、ハードウェアの進化と同期している。
開発者が知るべきTPUのよくある質問
TPUとGPU、どちらを学習に使うべきですか?
Google Cloud環境で大規模なTransformerモデルを継続的に学習させるなら、TPUがコスト効率で勝る。一方、PyTorchの既存ライブラリやコミュニティの資産を活用し、環境を問わず開発したい場合はGPUが適している。TPUはJAXとの親和性が高く、数学的な計算の最適化が行われている。GPUはCUDAというエコシステムがあり、トラブルシューティングやライブラリの互換性において開発者の生産性を支える。
TPUを使うためにコードを書き換える必要はありますか?
はい。TPUの性能を最大限引き出すには、TensorFlowやJAXといったTPU対応のフレームワークを使用し、演算をTPUのアーキテクチャに合わせて最適化する必要がある。PyTorchもPyTorch/XLAを通じてTPUを利用可能だが、GPU向けに書かれたコードをそのまま動かすだけでは、真の性能を発揮できないケースが多い。データパイプラインの構築や、モデルの並列化手法において、TPU特有の作法を学ぶ必要がある。
TPUは推論環境としても優秀ですか?
学習だけでなく推論環境としても選択肢になる。バッチサイズが大きい場合や、連続的なリクエストを処理するスループットが求められる環境では、TPUの演算ユニットが効率よく稼働する。ただし、単発のリクエストに対するレイテンシを削りたい場合は、モデルのサイズやアーキテクチャによってはGPUの方がチューニングしやすいケースもある。GoogleがGeminiの推論基盤としてTPUを運用している事実が、本番環境での実用性を示している。
まとめ:インフラの進化がAI開発のルールを書き換える
TPUの進化は、AI開発のコスト構造とアーキテクチャ設計の常識を覆す地殻変動だ。
演算に特化したハードウェアと、それを抽象化するソフトウェアの進化が、開発スタイルを変えようとしている。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
