
生成AIを自作のサービスに組み込む開発者が急増している。でも、実は多くの人が気づかないうちに法律違反ギリギリの橋を渡っているのが現状だ。結論から言うと、AI開発におけるデータ保護はエンジニア自身が守りを固めないと致命傷になる。
AI開発を始める前に必要なのは、日本の個人情報保護法の基本的な枠組みを知ることだ。コードを書くのと同じくらい、データの流れを法的に設計することが重要になる。安心してほしい。ポイントさえ押さえれば決して難しくない。今回は、1人SaaS開発者でも今日からすぐ行動に移せる法的リスク対策を7つに絞って徹底解説する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
対策1: 個人情報と個人データの違いを理解する
生成AIに関わるデータ保護の第一歩は、情報の階層構造を正確に把握することだ。多くのエンジニアが「個人情報」と「個人データ」を同じ意味で使っている。しかし、法律上はこの2つは明確に区別されており、適用される義務の重さが全く異なる。
個人情報は、特定の個人を識別できる情報全般を指す。一方、個人データは、その個人情報を検索できるようにデータベース化したものだ。エクセルやデータベースで管理されている顧客リストは、すべて個人データに該当する。
以下に、個人情報保護法における情報の分類をまとめた。
| 情報の種類 | 概要 | 規制の重さ |
| --- | --- | --- |
| 個人情報 | 特定の個人を識別できる情報 | 中 |
| 個人データ | データベース化された個人情報 | 高 |
| 保有個人データ | 開示や訂正の権限を持つ個人データ | 最高 |
| 個人関連情報 | 単体では個人を特定できない情報 | 低 |
エンジニアもこの違いを把握することで、意図せぬ法令違反を防げる。近年は法改正によって課徴金制度の導入なども議論されている。まずは自社のデータベースにある情報がどれに該当するか、正確な棚卸しから始めるべきだ。データの分類を誤ると、後続のセキュリティ対策がすべて無意味になるリスクがある。
対策2: プロンプト入力時の「個人関連情報」に注意する
ここがちょっとわかりにくいが、Cookieや位置情報などの個人関連情報には特別な注意が必要だ。これらは単体では個人を特定できない。しかし、提供先のシステムで他のデータと組み合わせて個人特定につながる場合は、本人同意が必須になる。
生成AIのプロンプト入力も、この個人関連情報に該当するケースが多々ある。たとえば、IPアドレスや端末識別子、ユーザーの行動パターンをAIに分析させる場合だ。断片的な情報でも、AIプロバイダー側で個人が特定できる状態になれば法律違反のリスクが生じる。
自社サービスにAIを組み込む場合、ユーザーの入力データがどこまで送信されるかを可視化するべきだ。不要なログやメタデータは、外部に送信する前にシステム側でフィルタリングするのが鉄則だ。データの最小化原則に従い、AIの推論に本当に必要な情報だけを抽出する仕組みを構築するべきだ。
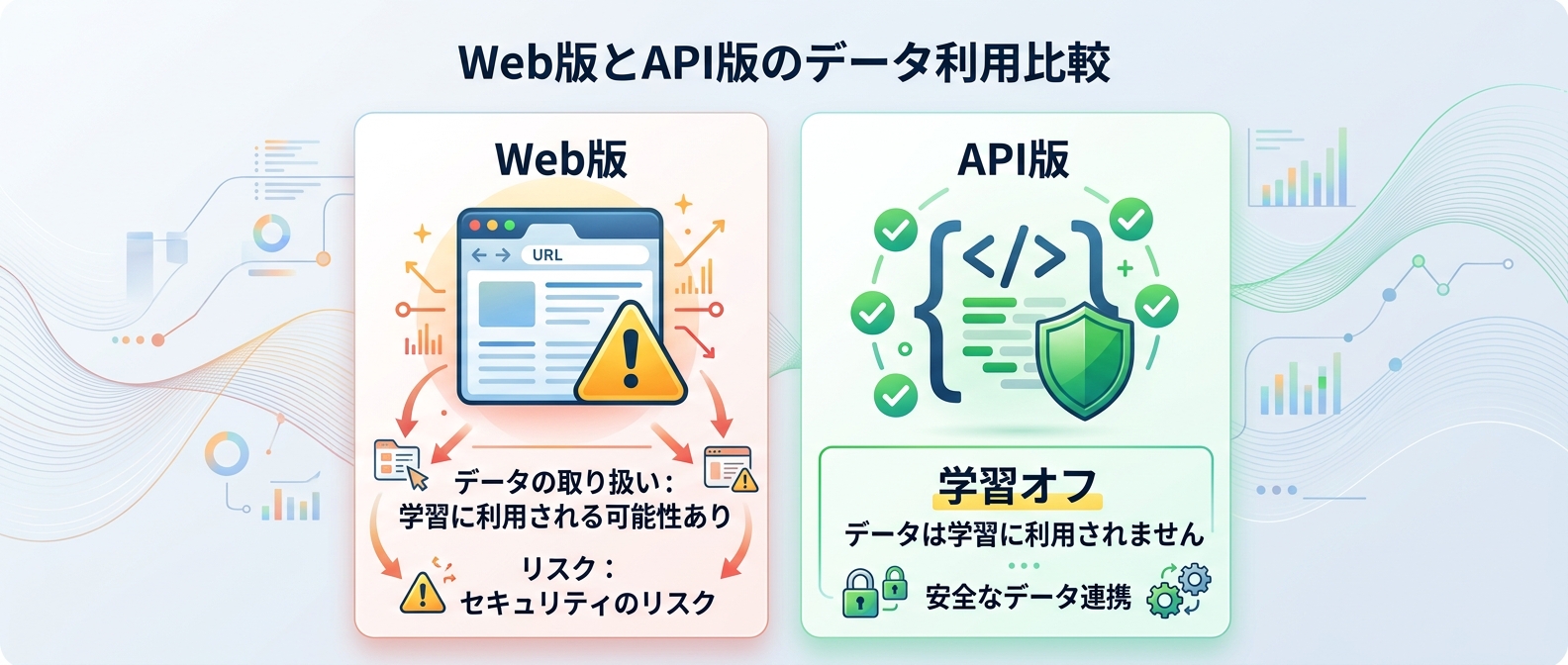
対策3: API利用で「学習利用」をオフにする
AIにデータを渡す際、プロバイダーがそのデータをモデルの学習に使うかどうかで法的な扱いが大きく変わる。入力データが学習に使われる場合、それは提供元の利用目的を超えた処理となり、第三者提供に該当する可能性が高い。
結論から言うと、業務でAIを使うならAPI経由で利用するのが一番安全だ。多くのAIサービスでは、API経由のデータは学習に利用しないと規約で明確に定められている。これにより、法的には第三者提供ではなく「委託」として整理できる。
Webブラウザで使う無料プランや個人向けプランの多くは、デフォルトで学習利用がオンになっている。これをそのまま業務で使うのは情報漏洩のリスクが高すぎる。社内で利用ガイドラインを策定し、学習利用のオプトアウトを徹底することが重要だ。開発環境と本番環境の両方で、APIの利用設定を厳格に管理するべきだ。
しんたろー:
開発初期はコストを抑えようとして、つい無料のWeb版AIでテストデータを流し込んでしまいがちだ。しかし、そこに顧客のダミーデータや本番に近いログが含まれていると、後から大きな問題になる。
最初からAPIキーを発行し、学習オフの環境で検証を進めるのがプロの鉄則だ。Claude Codeのような開発支援ツールを使う際も、データがどう扱われるか規約を確認する癖をつけている。
対策4: クラウド例外が通用しない前提で動く
個人情報保護法にはクラウド例外という解釈ルールが存在する。これは、クラウド事業者がデータにアクセスしない仕組みであれば、第三者提供には当たらないとするものだ。ただ、生成AIサービスにこの例外を適用するのは極めて困難だ。
なぜなら、AIは推論処理を行うために、ユーザーの入力テキストをトークン化してシステム上で高度に処理する必要があるからだ。技術的に事業者がデータに一切アクセスしない状態を担保するのは、事実上不可能に近い。
そのため、生成AIを利用するプロジェクトでは、クラウド例外は適用されない前提に立つべきだ。データを外部に渡す時点で、しっかりとした契約を結ぶことが求められる。法務担当者がいない1人開発者であっても、この原則を無視することは許されない。
対策5: DPA(データ処理補足契約)を必ず締結する
クラウド例外が使えない以上、外部のAIサービスにデータを渡す行為は「委託」として法的に整理するべきだ。そこで必須になるのが、DPA(データ処理補足契約)の締結だ。
DPAは、データの取り扱いに関する安全管理措置や、委託先としての責任を明確にするための重要な契約だ。監査権やデータ侵害時の通知義務などが含まれており、法人向けのEnterpriseプランなどを契約する際、標準で用意されている。
これを結ばずに顧客データをAIに流し込むのは、セキュリティの観点からも法務の観点からも非常に危険だ。サービス選定の際は、DPAが結べるかどうかを必ず確認リストに入れるべきだ。海外のサービスであっても、オンラインで同意できるDPAが用意されているケースが増えている。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
対策6: 越境データ移転規制と外部送信規律をクリアする
海外のAIサービスを使う場合、日本の法律である越境データ移転規制と外部送信規律の両方が絡んでくる。米国は日本の十分性認定の対象国ではない。そのため、米国製のAIを利用する際は特別な対応が必要になる。
具体的には、ユーザーから明確な本人同意を取得するか、先ほど説明したDPAを締結して基準適合体制を構築する。同意を取る際は、移転先の国名や保護制度、講じられる保護措置の内容を具体的に説明する義務がある。
さらに、自社WebアプリにAIを組み込む場合は、ユーザー端末から外部へデータを送るため外部送信規律の対象になる。プライバシーポリシーの改訂など、法務面での継続的なアップデートが不可欠だ。利用規約のテンプレートをそのまま使うのではなく、自社のデータフローに合わせたカスタマイズが求められる。
対策7: 国家レベルのサプライチェーンリスクに備える
AIプロバイダーの動向は、国家の安全保障とも密接に関わっている。最先端のAI企業は自律型兵器や大量監視への利用を拒否するなど、独自の倫理基準を掲げている。これが原因で、国家機関からサプライチェーンリスクに指定されるケースも実際にある。
米国のAI企業が国防総省からリスク指定を受けた事例などは、その典型だ。一般企業の利用に直接影響はないとされているが、プロバイダーと国家間の政治的な対立は無視できないリスクになる。
利用企業としては、ひとつのAIモデルに依存しすぎるのは危険だ。複数のAIモデルを切り替えられるマルチLLMのアーキテクチャを採用しておくのが、もっとも賢明な防衛策になる。APIのインターフェースを抽象化し、いつでも別のプロバイダーに乗り換えられる設計にしておくべきだ。
ThreadPostというサービスを1人で開発・運営していると、法務リスクの管理は全部自分の肩にのしかかってくる。
Claude Codeを使って開発スピードを上げる一方で、ユーザーのデータをどう守るかは常に頭の痛い問題だった。
海外の強力なAIモデルに頼らざるを得ない以上、規約を読み込んでDPAを結び、API経由でデータをコントロールするしかない。
面倒に感じるはずだが、ここをサボると後で取り返しのつかないことになる。
初心者がハマりやすい3つのつまずきポイント
AI開発を始めたばかりの人が陥りやすい罠を3つ紹介する。これだけは避けて通るべきだ。
1. 無料のWeb版AIに顧客データを入力してしまう
無料版は入力データがモデルの学習に使われることが多く、情報漏洩のリスクに直結する。機密情報を扱う場合は、必ず学習オフの設定にするか、APIを利用するべきだ。社内で個人アカウントの利用を放置していると、重大なインシデントにつながる。開発チーム全体でセキュリティ意識を共有することが不可欠だ。
2. 利用規約のサイレント変更を見落とす
AI企業の規約は頻繁にアップデートされる。昨日まで適法だった使い方が、今日から規約違反になることも珍しくない。特にデータ保護に関する条項は予告なく変更される。定期的なチェック体制を構築する必要がある。RSSフィードや規約変更の通知サービスを活用して、最新情報をキャッチアップする仕組みを作るべきだ。
3. 個人関連情報の扱いを軽視する
名前やメールアドレスが含まれていなくても、行動ログやブラウザ情報だけで個人を特定できるケースが多い。データを匿名化したつもりでも、実は不十分だったという失敗はよくある。送信するデータは最小限に留めるのが基本だ。ハッシュ化やマスキング処理を適切に行い、復元不可能な状態にしてからAIに渡す工夫が求められる。
よくある質問(FAQ)
ChatGPTに顧客情報を入力しても問題ない?
入力するデータの内容と利用プランによって法的な扱いが大きく異なる。無料プランや一部の個人向けプランでは、入力データがAIのモデル改善に利用される可能性がある。これは法的には目的外利用や第三者提供に該当するリスクが高い。EnterpriseプランやAPI経由での利用など、データが学習に利用されないことが規約で明記されている環境を用意することが重要だ。
プロンプトに直接的な個人名を含めなければ安全?
個人名が含まれていなくても安全とは言い切れない。日本の個人情報保護法では、Cookie情報や位置情報などを個人関連情報と定義している。プロンプトに入力した業務内容などの断片的な情報であっても、AI側で他のデータと組み合わせて個人を特定できる状態になれば保護対象になる。ユーザーの入力データを送信する際は慎重な判断が求められる。
海外の生成AIサービスを利用する際、日本の法律は適用される?
日本から海外のサーバーにあるモデルにデータを送信する場合、日本の法律が適用される。個人情報保護法の越境データ移転規制がその代表だ。米国は日本の十分性認定の対象国ではないため、米国サービスを利用する際はユーザーからの本人同意を取得するか、プロバイダーとDPAを締結するべきだ。さらに外部送信規律の対象になる可能性もある。
クラウド例外は生成AIにも適用できる?
生成AIサービスにおいてクラウド例外を適用するのは極めて困難だ。クラウド例外は、事業者が個人データにアクセスしないと評価できる場合にのみ成立する。しかし、生成AIはモデルの推論処理のために入力データをシステム上で処理するべきだ。そのため、生成AIではクラウド例外は適用されない前提に立ち、委託としてDPAを締結するのが実務上の基本になる。
AI企業が政府から規制を受けた場合、利用企業に影響はある?
プロバイダーが国家の安全保障上の理由でサプライチェーンリスクなどに指定された場合、間接的な影響が生じる可能性がある。影響の範囲は関連法規や契約のスコープによって異なるが、サービスの一時停止や機能制限のリスクはゼロではない。利用企業としては、特定のモデルに依存しないマルチLLM戦略などの対策を事前に検討しておくべきだ。
まとめ
今回は生成AI開発における法的リスク対策を7つ解説した。結論から言うと、個人データ保護のルールを理解せずにAIを組み込むのは非常に危険だ。API経由での利用やDPAの締結など、開発初期から守りを固めることが成功の鍵になる。法務と技術の両面からアプローチし、安全なAIサービスを構築するべきだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
