
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
誰もがエージェントに全振りする状況
各社が一斉にエージェントへ注力している。
単発のチャットで遊ぶ時代は終わった。
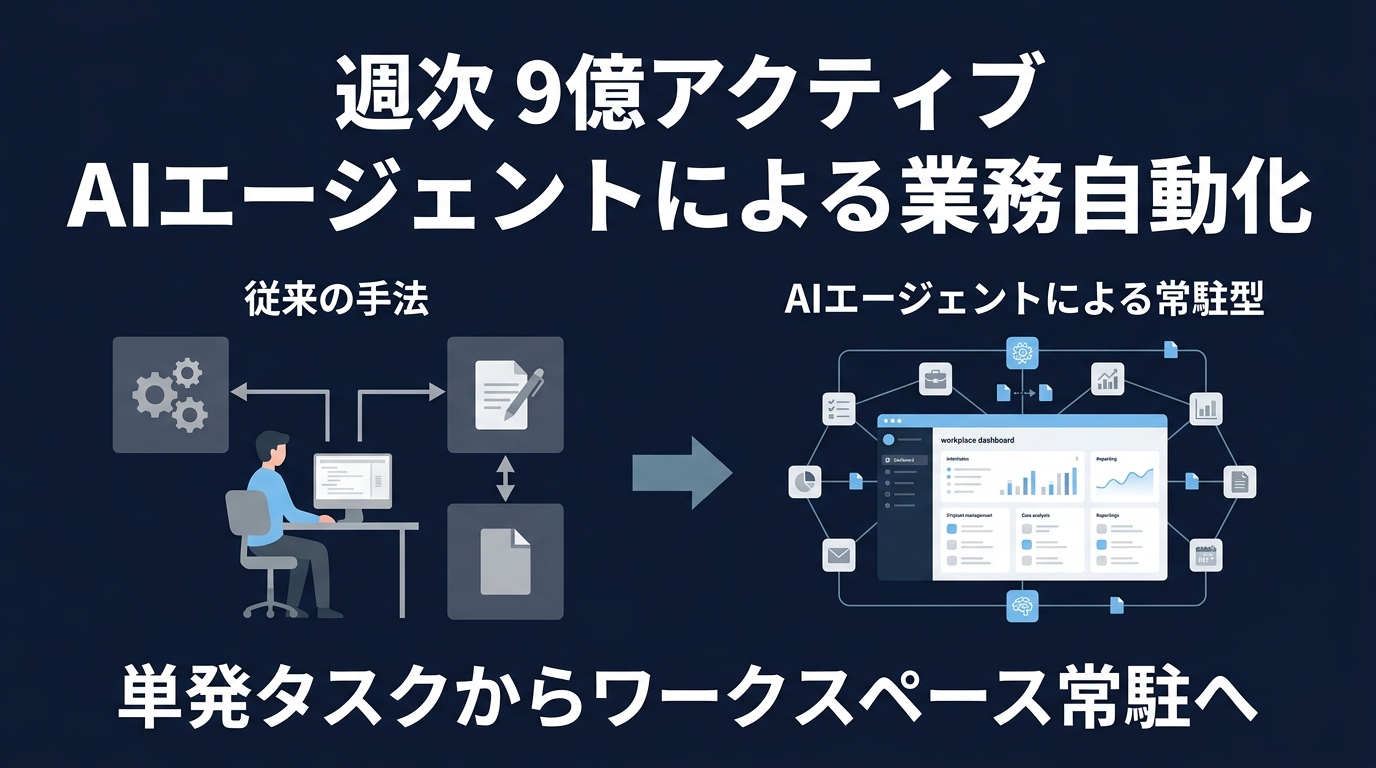
週次9億アクティブを抱える巨人が、反復業務の自動化に注力している。
開発者の仕事は「APIを叩くコードを書く」から「自律エージェントのワークフローを設計する」へシフトした。
この波を傍観すれば、確実に置いていかれる。
エージェント全振り時代の到来
ここ数週間でAI業界の景色が変わった。
各社が「長時間自律的に動くエージェント」の大型アップデートを連続投下している。
目玉は汎用型ワークスペースエージェントの登場だ。
これまで手作業でツール間をコピペしていた反復業務を、AIが実行する。
スケジュール実行や手動トリガーでエージェントが起動する。
Slack、CRM、社内ドキュメントに直接アクセスして情報を集める。
途中で情報が足りなければ、エージェントは自分で判断して止まる。
単なるプロンプト入力ではなく、業務インフラとしての立ち位置だ。
AIの使い方が、点から線へと繋がった。
同時に、専門特化型のエージェントも続々と公開されている。
非同期でリサーチを続けるモデルが登場した。
コーディングに特化してタスク完了率を3倍に引き上げたモデルも存在する。
各社の戦略は分化している。
汎用的な業務自動化で覇権を狙うゼネラリスト路線。
コーディングと複雑な論理タスクに一点突破する特化型路線。
そして、モダリティ拡張と非同期の深掘りリサーチに賭ける第三の極だ。
汎用モデルは、あらゆるツールを統合して「ひとつのサブスクで全部任せられる」世界を目指している。
一方で特化型モデルは、トークン処理能力を引き上げ、複雑なタスクを最後までやり切る力を磨いている。
リサーチ特化のモデルは、スピードよりも深さを優先し、膨大な情報源からレポートを生成する。
各社のベンチマーク競争は激しい。
だが、数字の裏にある「運用信頼性」が次の主戦場だ。
途中で壊れずに最後まで走り切れるか。
ユーザーが求めているのは、派手なスコアではなく「任せて安心できるか」だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
しんたろー:
各社がエージェント推しなのが気になる。単発のAPIコールで喜んでいたのが、昔のことのように思える。
開発者の役割はどう変わるのか
開発者にとって、これはアーキテクチャの根幹を揺るがす変化だ。
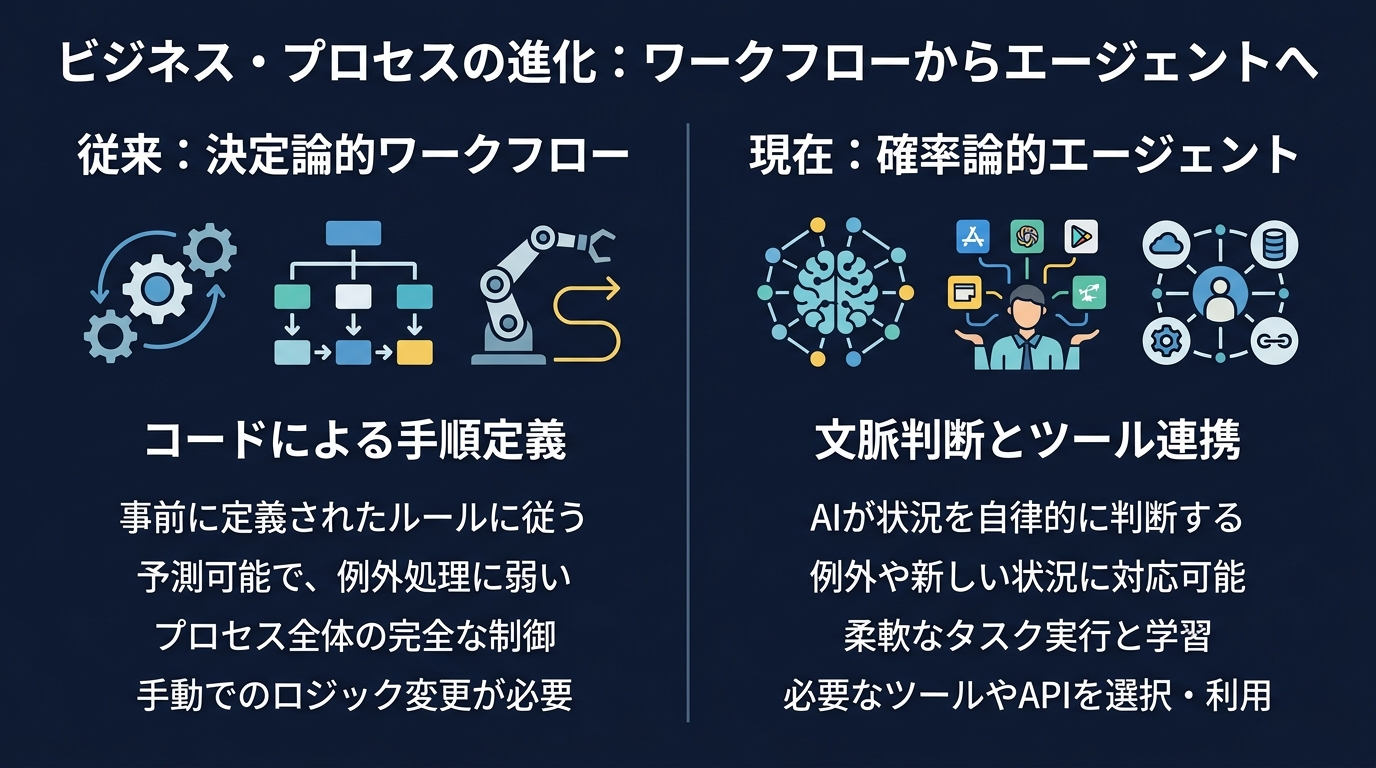
従来のAPIワークフローは決定論的だった。
ステップ1、ステップ2と、すべての分岐をコードで定義する必要があった。
だが、エージェントは確率論的だ。
ガードレールとツールセットだけを渡す。
モデルが文脈を解釈し、自分で経路を決める。
これは楽になる反面、コントロールが難しくなる。
開発者は「どのモデルを使うか」ではなく「どのエージェント基盤に乗るか」を選ぶことになる。
システムの作り方が変わる。
汎用業務の自動化なら、ゼネラリストのエージェント基盤に乗るのが正解だ。
スケジュール起動とツール連携が最初から用意されている。
開発者は、エージェントがアクセスできる社内システムのインターフェースを整えるだけでいい。
一方で、専門的な市場調査や非同期の重いバッチ処理なら、リサーチ特化の基盤を選ぶ。
一回のAPIコールで、裏側で時間をかけて情報を集め、レポートを生成する。
開発者は、その非同期処理の結果をどう受け取るかの設計に集中できる。
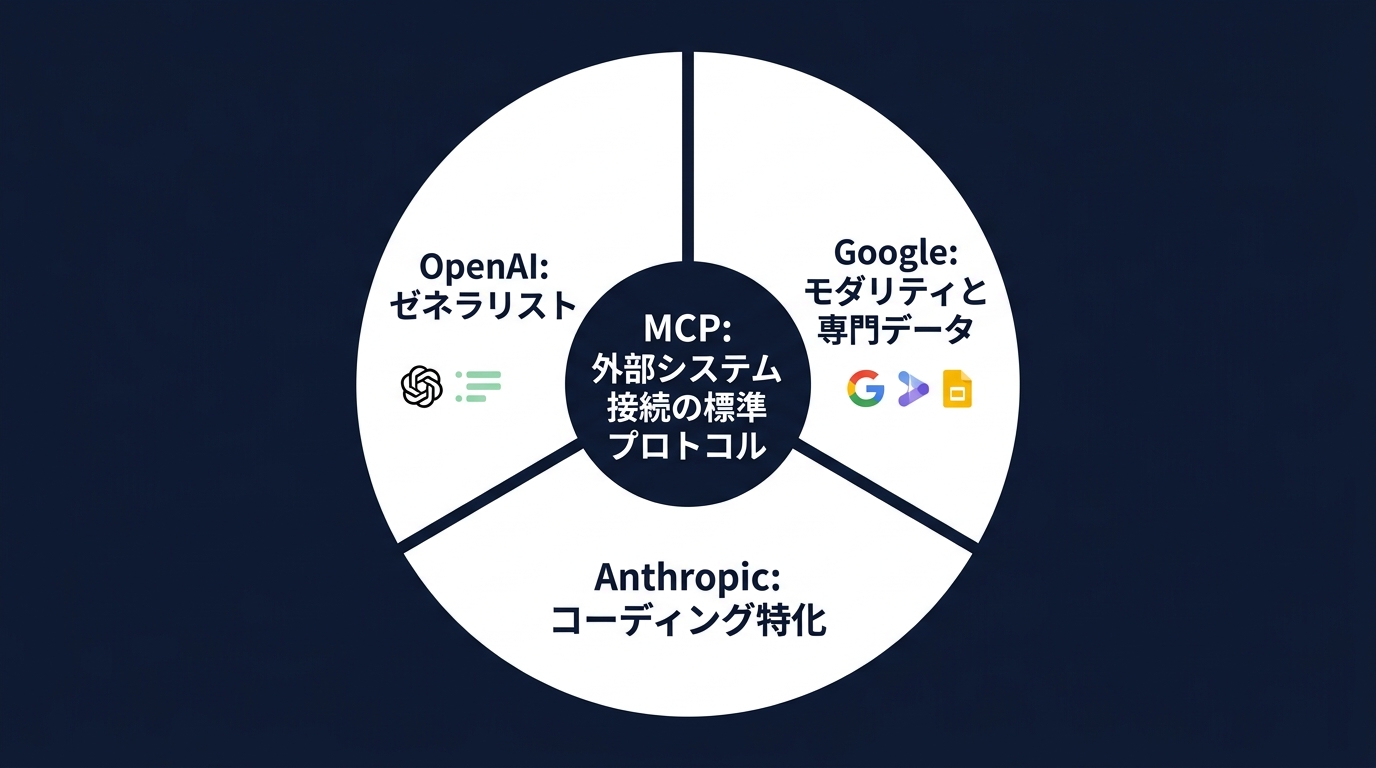
ここで重要になるのがMCPの存在だ。
標準プロトコルでツールを定義すれば、どのエージェントからも叩けるようになる。
専用のデータベースや社内APIをエージェントに開放する。
すると、単なるWeb検索マシンが、自律的な社内アナリストに化ける。
これまで各社バラバラだったAPI連携が、MCPを使えば繋がる。
開発のパラダイムを変える規格だ。
コーディング支援の領域でも同じことが起きている。
Claude Codeは、このエージェント思考の結晶だ。
ターミナルに常駐し、ファイルシステムを読み、コマンドを実行する。
開発者の脳を拡張するレベルに達している。
エージェントが自律的にコードを読み、修正し、テストを回す。
僕らはそのプロセスを監視し、方向性を修正する監督になる。
Claude Codeにコードを書かせていると、この自律性の高さが気になる。ThreadPostのバッチ処理もエージェントに投げたくなる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務でどう備えるべきか
開発者は明日からどう動くか。
まず、すべてを自作するのをやめる。
決定論的なワークフローで固めたシステムは、古い。
エージェントに「目的」と「ツール」を渡す設計に切り替える。
ここで重要になるのがガバナンスだ。
エージェントは勝手に動く。
「どこまで許すか」の境界線引きが開発者の腕の見せ所になる。
参照していいデータ、実行していいアクション。
これらをMCPなどの標準規格に沿って安全にカプセル化する。
適材適所でエージェントを使い分ける。
これが今後のアーキテクチャの基本になる。
汎用タスクには汎用エージェント、専門タスクには専門エージェントを割り当てる。
エラーハンドリングの考え方も変わる。
システムが落ちるのではなく、エージェントが「迷う」。
迷ったときに人間にエスカレーションする仕組みを組む。
途中で人手による承認プロセスを挟む設計が必須になる。
完全に自動化するのではなく、重要な意思決定のポイントで人間を介在させる。
運用信頼性の担保が、プロダクトの価値に直結する。
コンテキストの管理も課題だ。
エージェントが長時間動くほど、文脈が膨れ上がる。
どの情報を保持し、どの情報を捨てるか。
トークン制限の中で、いかに効率的にコンテキストを渡すか。
このあたりのチューニングが、新しい時代のパフォーマンス・オプティマイゼーションになる。
外部ツールとの接続性や運用信頼性を重視するフェーズに移行した。
単にLLMを呼び出すコードを書く時代は終わった。
エージェントが外部ツールと安全に連携するための「ワークフローの設計」が求められる。
特定のモデルに依存せず、複数のエージェント基盤を使い分ける設計能力が重要になる。
確率論的なシステムのエラーハンドリングは頭を悩ませる。これを乗りこなさないと1人SaaSのスケールは頭打ちになる。
核心を突くFAQ
Q1: エージェントと従来のAPIワークフローは何が違うのですか?
A1: 決定論的か確率論的かの違いだ。従来のAPIワークフローはプログラムされた手順通りに動く。一方、最新のワークスペースエージェントは文脈を解釈し、状況に応じて判断を下す。途中で情報が足りなければ自分で検索し、エラーが出れば修正する。開発者がすべての分岐を定義しなくても、目的ベースで自律的に動くのが最大の違いだ。
Q2: どのエージェント基盤を選ぶべきですか?
A2: 目的によって分かれる。社内システムとの広範な連携や汎用業務の自動化なら、ゼネラリストのエージェント基盤が強い。コーディングや複雑な論理タスクなら、特化型の基盤が適している。専門的なデータ分析やリサーチ業務なら、非同期実行に強い基盤を選ぶ。まずは自社のタスクの性質を見極めることだ。
Q3: MCPはなぜ重要視されているのですか?
A3: エージェントと外部ツールの接続を標準化するからだ。これまで各社バラバラだったAPI連携が、MCPを使えば繋がる。社内の独自データベースや特殊なツールをMCPでラップする。それだけで、あらゆるエージェントがそのツールを自律的に使えるようになる。開発者の負担を下げる規格だ。
まとめ
エージェントの進化で、開発者の仕事は「コードを書く」から「自律システムを統制する」へ変わる。
この波は絶対に見逃せない。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
