
出た。32Bの軽量モデルが、480Bの超巨大モデルを完全に粉砕した。
ターミナル環境での自律実行テストでの出来事だ。
パラメータ数の暴力で殴るゲームは終わった。
これからは「いかに高品質な実行ログを食わせるか」がAIの賢さを決める。
ターミナルエージェントの進化が止まらない。
僕らの開発環境は、根本から変わろうとしている。
AIにコードを書かせるだけのフェーズは過去のものになった。
今はAI自身がターミナルを叩き、エラーを読み、自律的にタスクを完結させる。
その最前線で、NVIDIAがとんでもないゲームチェンジャーを投入してきた。
エージェント開発のパラダイムシフトの全貌を紐解いていく。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
巨大AIを凌駕した32Bモデルの正体
AIエージェント開発の最大のボトルネックは、ずっとデータだった。
ターミナルを自律的に操作するAIを作るには、膨大な学習データが要る。
しかし、プロンプトと正解コードの単純なペアだけでは不十分だ。
それは単なる「模範解答」に過ぎない。
実際のターミナル環境はもっと過酷だ。
コマンドを打ち、予期せぬエラーを読み、原因を推測して修正し、再実行する。
この泥臭いステップバイステップの「実行軌跡」が必要になる。
人間が手動で記録するのは遅すぎるし、コストが全く合わない。
かといって、AI同士で自動生成させようにも致命的な壁があった。
毎回新しい仮想環境を立ち上げる必要があり、計算コストが跳ね上がる。
誰も手を出せなかったこの領域で、NVIDIAが動いた。
彼らは新しいデータ生成パイプラインと、巨大なデータセットを公開した。
既存の高品質な静的データを、インタラクティブなターミナルタスクに変換する仕組みだ。
数学やコーディングのデータセットを、実行可能なタスクに生まれ変わらせる。
環境構築コストの破壊
最大のブレイクスルーは、環境構築のコスト破壊にある。
タスクごとに仮想環境を作る従来の無駄な手法を完全に捨て去った。
代わりに、データサイエンス用やセキュリティ用など、9つの事前構築済み共有ベースイメージを用意した。
必要なライブラリが最初から詰まっている魔法の箱だ。
NVIDIAのデータ生成パイプラインの特徴は以下の通りだ。
- 既存の静的データを再利用してタスクを生成する
- 9つの共有ベースイメージで環境構築をスキップする
- 大規模な並列処理で軌跡データを一気に生成する
これにより、低コストで膨大かつ高品質な実行軌跡データを生成できるようになった。
結果が数字に表れた。
このデータで学習した32Bのモデルが、Terminal-Bench 2.0ベンチマークで高いスコアを叩き出した。
エンドツーエンドのワークフロー実行テストでの出来事だ。
機械学習モデルの訓練やシステム環境のデバッグといった複雑なタスクをこなすテストである。
ここで32Bのモデルが、480Bの巨大モデルを完全に上回った。
32Bのモデルの勝率は23.9パーセント。480Bの巨大モデルは23.1パーセントだ。
クローズドな最先端モデルの性能にすら肉薄している。
モデルのサイズではなく、データの質が勝敗を分けた決定的な瞬間だ。

しんたろー:
32Bが480Bを超える。冗談のような光景だ。
データの質がパラメータ数を凌駕する瞬間をリアルタイムで見ている。
うちのThreadPost開発でも、モデルのサイズよりプロンプトの文脈のほうが結果を左右する気がしてならない。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
パラメータ数から軌跡の質へ
このニュースが意味するのは、単純なモデルの性能向上だけではない。
エージェント開発の主戦場が「モデルの大きさ」から「データエンジニアリング」に移ったということだ。
ターミナルという環境は、AIにとって極めて過酷な戦場だ。
曖昧な指示を解釈し、システムの状態を把握し、適切なコマンドを叩く必要がある。
これまでのAIは、コードを「書く」ことはできても「実行して完結させる」ことは苦手だった。
実行して失敗し、そこからリカバリーする「軌跡」を学習していない。それが原因だ。
NVIDIAのアプローチは、モデル自体のターミナル操作能力を底上げするものだ。
基礎体力を極限まで高めるための、強力なドーピングと言える。
MCPによるツールの拡張
一方で、実務の現場ではもう一つの地殻変動が同時進行している。
それがMCPという新しい標準プロトコルの爆発的な普及だ。
AIと外部ツールを接続するための共通規格である。
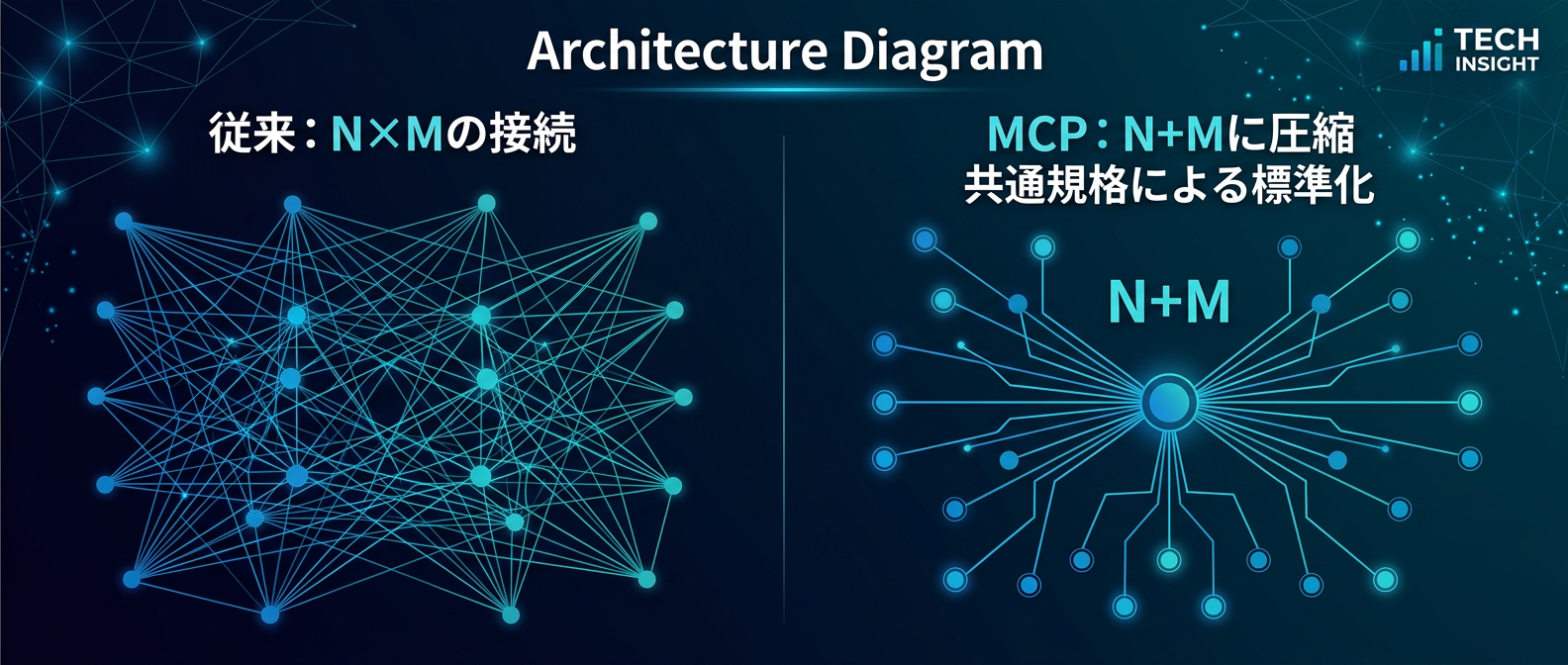
これまで、AIに社内データベースや独自ツールを触らせるには、専用の実装が必要だった。
AIがN個、ツールがM個あれば、N×M通りの接続コードを書く羽目になる。
APIの仕様変更のたびにコードを書き直す、地獄のような保守作業だ。
しかしMCPの登場で、これがN+Mに圧縮された。
一度MCPサーバーを作れば、対応するすべてのAIクライアントで使い回せる。
MCPが提供できる機能は主に3つある。
- ツール呼び出しによる外部システムへのアクション
- リソース提供による読み取り専用データの参照
- プロンプト提供による再利用可能なコンテキストの注入
Claude Codeのような既存の強力なモデルを、自社の独自環境に簡単に接続できるようになった。
これは開発者にとって、計り知れない恩恵をもたらす。
NVIDIAがモデルの「基礎体力」を上げている。
同時に、MCPがモデルの「手足」を爆発的に増やしている。
この2つの波が合流した時、ターミナルは単なる黒い画面ではなくなる。
AIが自律的に考え、ツールを駆使してタスクを完結させる最強の実行環境に変わる。
僕ら開発者は、もはやコードを書く作業員ではない。
優秀なAIエージェントを束ね、適切な環境とツールを与える指揮官になる。
MCPの概念を知った時、鳥肌が立った。
APIの繋ぎ込みで消耗していた過去の自分を殴りたい。
ThreadPostのバックエンド操作も、全部MCP経由でClaude Codeに投げられたら最高に楽になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
僕らの開発環境はどう変わるのか
で、僕らの日々の開発にどう影響するのか。
結論から言うと、AIへの「指示の出し方」と「環境の作り方」を根底から変える。
AIにブラウザ上でコードを書かせ、それをコピペする時代は完全に終わった。
これからはターミナル上で、AIに直接タスクを完結させる。
Claude CodeとMCPの連携
Claude Codeはまさに、このターミナルエージェントの最前線を走っている。
コマンドラインから直接AIを呼び出し、ファイルシステムを読み書きさせる。
これだけでも十分に強力だが、周辺ツールと組み合わせることで次元が変わる。
例えば、頻繁に使うプロンプトをランチャーアプリのスニペット機能に登録する。
定型的な指示入力を自動化するだけで、作業スピードは跳ね上がる。
「このプルリクエストのレビューを確認して、必要なら修正して」といった指示を1秒で出す。
さらに、独自のスクリプトをMCP経由でClaude Codeに接続する。
画像アップロードやテストの実行、デプロイ作業など、自社特有のワークフローをAIに叩かせる。
ここで「ログの蓄積と共有」が鍵を握る。
NVIDIAの発表が示す通り、高品質な実行軌跡こそがAIを賢くする。
実務現場での高度なClaude Codeの活用ログ。
外部ツールとの連携軌跡や、複雑なエラーからの復帰プロセス。
これらをチーム内で蓄積し、共有する仕組みが今後の競争力を決める。
どのツールをどう繋ぎ、どう解決したかという「軌跡」がチームの資産になる。
また、開発工程全体をAIと構造化して進めるアプローチも極めて有効だ。
実務でのClaude Code活用ステップは以下のようになる。
- 要件定義で制約とゴールを明確にする
- コードベース探索で既存のパターンを把握させる
- アーキテクチャ設計で複数の案を出させ、トレードオフを比較する
- 実装とレビューを並列で行わせ、品質を担保する
各ステップでAIに適切なコンテキストを与え、対話しながら進める。
一気に完成形を求めるのではなく、段階的に合意形成を図る。
これまでは、エラーが出たらそのログをコピーしてブラウザのAIに貼り付けていた。
AIが解決策を提案し、それをまたターミナルに貼り付ける。
この不毛な往復作業に、僕らはどれだけの時間を奪われてきただろうか。
Claude Codeなら、エラーが起きたその場で直接AIに原因を調査させることができる。
ログの収集から原因の特定、修正コードの適用まで、すべてターミナル内で完結する。
ターミナルエージェントは、単なるコーディングアシスタントではない。
プロジェクトの共同遂行者へと進化している。
僕らはAIの出力結果をレビューするだけではない。
AIがタスクを遂行する「過程」を設計し、見守る役割にシフトしていく。
ターミナルでAIが勝手にエラーを直していくのを眺めるのは、不思議な感覚だ。
優秀な後輩が隣でタイピングしているような気分になる。
ただし、たまにとんでもないファイルを消そうとするから、承認ステップだけは絶対に外さない。
ターミナルエージェントとMCPに関するFAQ
Q1: MCPサーバーをPythonで作る際、デバッグログはどう出力するのか?
MCPサーバーをPythonで実装し、標準の通信モードで動作させる場合、標準出力がAIとのJSON通信路として直接使われる。
そのため、開発中に安易に標準出力でデバッグログを出してしまうと、JSONフォーマットが崩れて通信プロトコルが完全に壊れる。
これが原因でサーバーが即座にクラッシュするのが、初心者が陥る最大のハマりポイントだ。
デバッグ情報を出したい場合は、必ず標準エラー出力を使用するか、専用のロギングモジュールを用いて外部ファイルにログを書き出すように設定する。
Q2: NVIDIAの新しいデータ生成手法は、従来のAI学習データセットと何が違うのか?
従来のデータセットの多くは、静的なプロンプトとコードの正解ペアに過ぎなかった。
しかしターミナルエージェントには、コマンドを実行しエラーを見て修正するというステップバイステップの実行軌跡が必要になる。
今回の手法は、既存の静的データをインタラクティブなタスクに変換するパイプラインだ。
タスクごとに仮想環境を作る重い手法を捨て、共有ベースイメージを活用することで、低コストかつ大規模に軌跡データを生成できるようになったのが最大の違いだ。
Q3: Claude Codeを実務でチーム導入する際、どのような工夫が効果的か?
Claude Codeは周辺ツールと組み合わせることで真価を発揮する。
例えば、ランチャーアプリのショートカットを用いて定型プロンプトの入力を自動化するのが非常におすすめだ。
また、独自のスクリプトをMCP経由で連携させると、自社特有の作業効率が跳ね上がる。
要件定義からアーキテクチャ設計、実装、コードレビューまでの工程を構造化して進めるプラグイン機能を活用し、日常業務のメインインターフェースとして全職種で使う事例も出てきている。
まとめ
パラメータの暴力からデータの質へ、AIの進化の軸が完全に切り替わった。
ターミナル上で自律的に動くAIをどう使いこなすかが、今後の開発者の価値を決める。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる技術10選|API課金を最適化する実践ノウハウ

VercelのZeroが変えるAI開発、なぜエージェントに特化した言語が必要なのか

Claude Codeのセキュリティ設定|APIキー管理の新たな責務

なぜKPMGは全社員にClaudeを導入したのか。業務を自律化するエージェント設計を徹底解説

AnthropicのStainless買収でClaude開発はどう変わるのか。API接続の自動化とMCP活用による新時代のAIシステム構築を完全ガイド
