
RAG(検索拡張生成)を実装したのに「なんか回答がズレている」「ハルシネーションが止まらない」「期待したほど賢くない」という経験はないだろうか。原因のほとんどは、チャンク設計とコンテキスト管理の甘さにある。
2026年現在、RAGの精度向上は「フラットなテキスト分割を卒業できるかどうか」が分岐点だ。単純にテキストを切り刻んでベクトルデータベースに保存するだけのアプローチは、すでに限界を迎えている。今回は、検索精度・推論能力・トークン効率を根本から底上げする手法とツールを4つ厳選して解説する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
選定基準
以下の3軸で選んだ。
- 検索精度への直接的な貢献度
- エージェント開発への実用性
- 初心者〜中級者が導入できる現実的な難易度
単なる概念論ではなく、「実際にパイプラインに組み込める」ものだけを取り上げた。
1. Parent-Child Chunking|検索と生成のトレードオフを解消する設計手法
RAG精度向上の最初の一手として、まずここから始めるべき手法だ。
従来のRAGは、テキストを一定サイズで分割して全部ベクトルDBに放り込む設計が主流だった。しかしここに構造的な矛盾がある。
- 検索精度を上げたい → チャンクは小さいほうがいい(150〜300トークン程度)
- LLMに文脈を渡したい → チャンクは大きいほうがいい(800〜1500トークン程度)
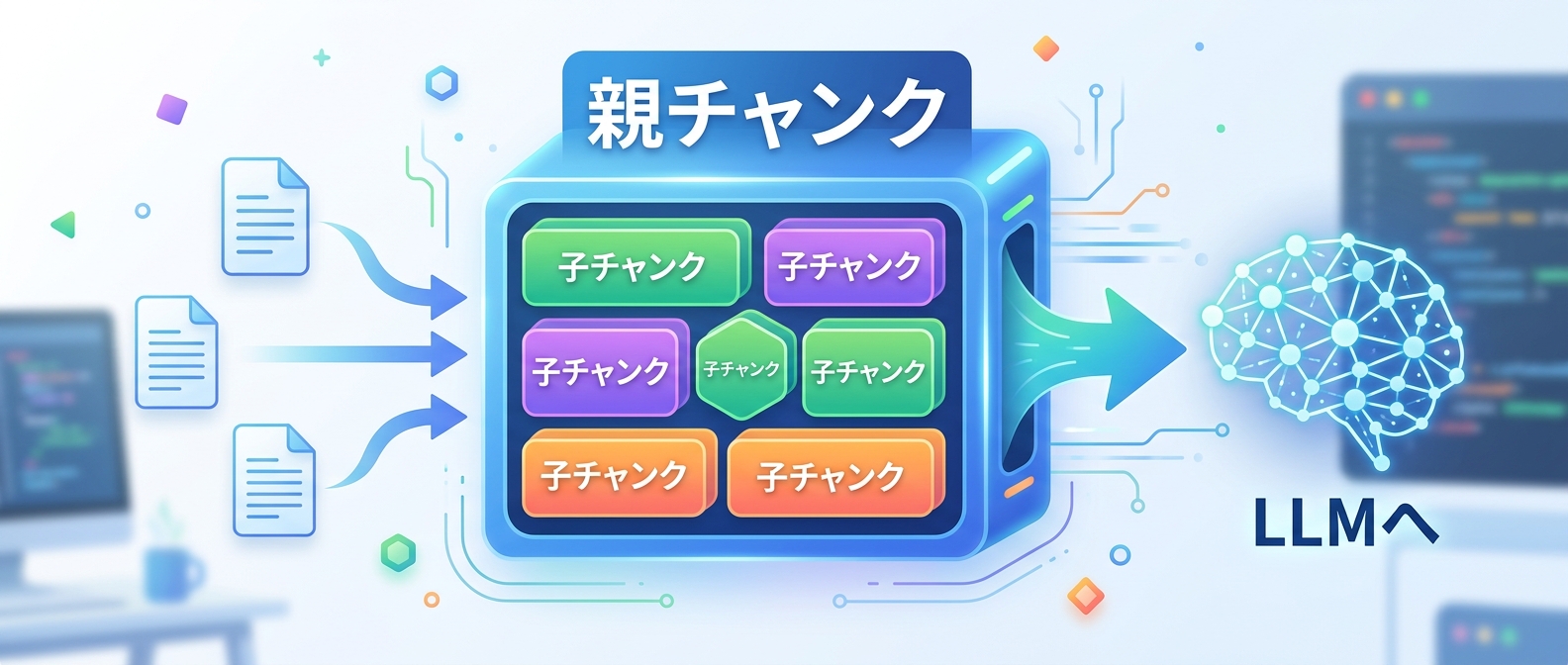
この2つは同時に成立しない。Parent-Child Chunkingはこの矛盾を「チャンクを2層に分ける」という発想で解決する。
仕組みはシンプルだ
- Childチャンク(150〜300トークン): ベクトルDBに登録し、検索に使う
- Parentチャンク(800〜1500トークン): LLMに渡す文脈として使う
処理の流れは「Childで検索 → ヒットしたChildに紐づくParentを取得 → ParentをLLMに渡す」という順番になる。
検索の粒度と生成の文脈量を独立して最適化できるのが最大の強みだ。特に長文ドキュメント(社内規程、製品マニュアル、契約書など)を扱うRAGでは、この設計の有無で回答品質が大きく変わる。たとえば「有給休暇の取得条件」を検索する場合、Childチャンクで「有給休暇」というキーワードを正確に拾い上げ、Parentチャンクで「第10条(有給休暇)...」という条文全体をLLMに渡すことができる。
LlamaIndexやLangChainなどの主要なフレームワークでも、このParent-Child Chunking(またはAuto-Merging Retriever)は標準的な機能としてサポートされ始めている。実装のハードルは以前よりも格段に下がっている。
デメリットは、Parentサイズを大きくしすぎると複数ヒット時にコンテキストウィンドウを圧迫するリスクがある点だ。Childのオーバーラップ(20〜50トークン程度)も適切に設定しないと、文章の途中で意味が途切れる。
料金: 設計手法なので追加コストはゼロ。既存パイプラインの実装変更のみで導入できる。
2. OpenViking|ファイルシステム型の階層コンテキストDB
フラットなベクトル検索の限界を感じているなら、OpenVikingは気になる存在だ。
Volcengine製のオープンソースプロジェクトで、AIエージェントのコンテキスト管理をファイルシステムのように階層化するという発想が面白い。
従来のベクトルDBはコンテキストを「フラットなテキストの塊」として扱う。これが長時間稼働するエージェントや複雑なタスクを処理するエージェントで問題になる。「どのプロジェクトの、どのタスクに関する情報か」という構造的な文脈が失われてしまうからだ。たとえば、A社のプロジェクトとB社のプロジェクトの要件定義書が混ざってしまい、エージェントが混乱するケースが頻発する。
OpenVikingのアーキテクチャ
「viking://」プロトコルで仮想ファイルシステムを公開し、コンテキストをディレクトリ構造で管理する。
- resources: プロジェクトドキュメント
- user: ユーザー設定・好み
- agent: タスク記憶・スキル・指示
検索は「ベクトル検索でスコアの高いディレクトリを特定 → そのディレクトリ内で再検索 → サブディレクトリを再帰的に掘り下げる」というディレクトリ再帰検索で動く。
ディレクトリ構造を持つことで、エージェントは「今はAプロジェクトのディレクトリ内だけを検索する」といったスコープの限定が可能になる。これにより、無関係な情報がノイズとして混入するのを防ぎ、推論の精度を高く保つことができる。
単純な類似度検索ではなく、「どのディレクトリ文脈の中でヒットしたか」まで保持できるのが強みだ。エージェントの記憶管理を体系化したい場合に特に有効だ。
デメリットは、フラットなベクトル検索と比べてシステム構成が複雑になる点だ。検索パイプラインの設計コストは従来より高くなる。
料金: オープンソース(無料)。ホスティング・運用コストは自前になる。
3. Uncertainty-Aware LLM Pipeline|自己評価でハルシネーションを抑える仕組み
ハルシネーションの根本原因は「LLMが自分の不確実性を認識していない」ことだ。
このパイプラインは、LLM自身に「この回答への確信度はどのくらいか」を評価させ、確信度が低い場合に自動でWeb検索を実行して情報を補完するという3段階設計になっている。
3段階のパイプライン
- 回答生成 + 確信度スコアの出力: LLMが回答と同時に自己報告の確信度スコアを出力する
- 自己評価ステップ: LLM自身が回答を批評・精緻化するメタ認知チェックを実行する
- 自動Webリサーチ: 確信度が閾値(たとえば0.55以下)を下回った場合のみ、外部検索を実行して情報を補完する
自己評価ステップでは、LLMに「この回答は事実に基づいているか」「推測が含まれていないか」を客観的にチェックさせるプロンプトを挟む。このメタ認知のプロセスが、ハルシネーションのストッパーとして強力に機能する。
この設計の優れた点は「常にWebを叩くのではなく、不確実性が高い時だけ叩く」という選択的な補完にある。確信度が高い一般的な質問には余分なレイテンシが発生しない。一方で、最新のニュースやニッチな専門知識を問われた際には、LLMが「自分の知識だけでは不十分だ」と判断し、自律的に検索を行って正確な情報を取得する。
デメリットは、自己評価と追加のWeb検索プロセスが発生するため、全体的な応答速度は低下する。リアルタイム性が求められるユースケースには向かない場面もある。
料金: 設計パターンなので追加コストはゼロ。ただしWeb検索APIの利用料が別途発生する。
しんたろー:
Claude Codeで1人SaaS開発してると、LLMが自信満々に間違ったコードを出力するケースに何度も遭遇してきた。
Uncertainty-Aware Pipelineの発想は本質を突いている。「確信度が低い時だけ検索を走らせる」という設計は、コスト効率とハルシネーション抑制を両立できる賢いアプローチだ。自分のエージェント設計にも取り入れたい考え方だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
4. OpenSpace|タスクをこなすほど賢くなる自己進化型スキルエンジン
トークンコストに悩んでいるなら、OpenSpaceは見逃せない存在だ。
HKUDS開発のオープンソースプロジェクトで、エージェントが実行したタスクから再利用可能な「スキル」を自動抽出してデータベースに保存し、類似タスクが来た時に再利用する仕組みだ。
自己進化の仕組み
- コールドスタート: スキルがない状態でタスクを実行し、推論プロセスを記録する
- スキル抽出: タスク完了後、再利用可能なパターンを自動でSQLiteデータベースに保存する
- スキル再利用: 類似タスクが来たら保存済みスキルを参照し、ゼロから推論する手間を省く
コールドスタート時には通常のCoT(Chain of Thought)で推論を行い、その成功パターンを抽出する。スキルが蓄積されるにつれて、エージェントは「考えながら動く」状態から「知っている手順を即座に実行する」状態へと進化していく。
たとえば「特定のフォーマットでJSONデータを抽出する」というタスクを一度成功させれば、その推論手順がスキルとして保存される。次に似たようなデータ抽出タスクが発生した際、エージェントは試行錯誤することなく、保存されたスキルを直接適用して一発で正解を導き出す。
3つの進化モード(FIX・DERIVED・CAPTURED)と、スキルを健全に保つ3つの自動トリガーが設計されている。
最大の強みは数字だ。 GDPValベンチマーク(50の実世界タスク)での実証では、トークン消費量を約46%削減しながら処理効率を大幅に向上させた実績がある。長期稼働するエージェントほど恩恵が大きくなる設計だ。
さらに「open-space.cloud」のクラウドコミュニティでは、複数のエージェントがスキルを共有する集合知の仕組みも持っている。
デメリットは、スキル抽出・管理エコシステムを導入するための初期設定と学習コストが必要な点だ。既存のシンプルなエージェントに後付けで組み込む場合は、設計の見直しが必要になることもある。
料金: オープンソース(無料)。クラウドコミュニティ機能は要確認だ。

4手法の比較表
| 手法・ツール | 主な効果 | 難易度 | 追加コスト | おすすめ度 |
|---|---|---|---|---|
| Parent-Child Chunking | 検索精度と文脈保持の両立 | 低〜中 | なし | ★★★★★ |
| OpenViking | 階層的コンテキスト管理 | 高 | なし(OSS) | ★★★★☆ |
| Uncertainty-Aware Pipeline | ハルシネーション抑制 | 中 | Web検索API代 | ★★★★☆ |
| OpenSpace | トークンコスト削減・自己進化 | 中〜高 | なし(OSS) | ★★★★☆ |
正直、RAGの精度問題は「チャンク設計を見直すだけで8割解決する」と確信している。
Claude Codeで毎日コードを書いてる中で、コンテキスト管理の設計がいかに重要かは身に染みてわかる。Parent-Child Chunkingは概念がシンプルな分、すぐ試せるのが強みだ。OpenSpaceのトークン46%削減という数字も気になる。長期稼働エージェントを作るなら、スキル再利用の仕組みは絶対に考慮すべき設計だ。
しんたろーの推し
まず手を動かすなら Parent-Child Chunking 一択だ。
理由はシンプルで、追加コストゼロ・概念がわかりやすい・効果が出やすいという三拍子が揃っている。既存のRAGパイプラインのチャンク分割を見直すだけで、検索精度と文脈保持の両方が改善される。
次のステップとして、ハルシネーションが課題ならUncertainty-Aware Pipeline、トークンコストが課題ならOpenSpaceという順番で検討するといい。
よくある質問
Q1. RAGのチャンクサイズはどのくらいが最適か。
検索用と生成用で最適なサイズは根本的に異なる。検索精度を高めるには150〜300トークン程度の小さなチャンクが適しているが、LLMが文脈を正しく理解して自然な回答を生成するには800〜1500トークン程度の大きなチャンクが必要だ。
このジレンマを解決するのがParent-Child Chunkingで、検索用(Child)と生成用(Parent)のチャンクを分けて階層的に管理する。これにより、検索のヒット率と回答の正確性を両立させることが可能になる。「どちらかを犠牲にする」という選択肢を取らなくてよくなるのが最大のメリットだ。単純な分割から一歩進んだ設計として、必ず押さえておきたい。
Q2. Parent-Child Chunkingを実装する際の注意点は何か。
Parentチャンクのサイズ設定に最も注意が必要だ。文脈を保持するためにサイズを大きくしすぎると、検索で複数のParentチャンクがヒットした際にLLMのコンテキストウィンドウを圧迫してしまう。最悪の場合、トークン上限エラーを引き起こす原因になる。
また、Childチャンク間のオーバーラップ(20〜50トークン程度)を適切に設定し、文章の途中で意味が途切れるのを防ぐことも重要だ。LLMの処理能力と文脈保持のバランスを見極めて設計する必要がある。最初は小さめのParentサイズから始めて、回答品質を見ながら調整していくアプローチが現実的だ。
Q3. OpenVikingのようなContext Databaseは通常のベクトルDBとどう違うか。
通常のベクトルDBはテキストをフラットなリストとして扱い、意味的な類似度のみで検索を行う。一方、OpenVikingはファイルシステムのように情報を階層化して保存する。
「どのプロジェクトの、どのタスクに関する情報か」という構造的な文脈を保ったままディレクトリを絞り込んで検索できるため、エージェントの記憶管理や検索の精度が飛躍的に向上する。複数の長期タスクを並行処理するような複雑なエージェントに特に有効な設計だ。単純な類似度検索では「関連しているけれど全然違うプロジェクトの情報」がヒットしてしまう問題を構造的に解消できる。
Q4. LLMのハルシネーションをRAGで防ぐにはどうすればいいか。
RAGで関連情報を提供するだけでなく、LLM自身に「回答の確信度」を評価させる仕組み(Uncertainty-Aware Pipeline)を組み込むことが有効だ。
LLMが自身の回答に対して確信度が低いと判定した場合にのみ、自動で外部のWeb検索を実行して最新情報や不足情報を補完するステップを挟む。これにより、不確実な推測によるハルシネーションを大幅に減らし、より信頼性の高い回答を生成できる。「常にWebを叩く」のではなく「必要な時だけ叩く」設計なので、レイテンシとコストのバランスも取りやすい。
Q5. エージェントのAPIトークンコストを節約する方法はあるか。
OpenSpaceのような自己進化型スキルエンジンの導入が非常に効果的だ。エージェントが過去に解決したタスクの推論プロセスを「スキル」としてデータベースに保存し、類似タスクが発生した際にそのスキルを再利用することで、ゼロから推論する手間を省く。
GDPValベンチマークでの実証では、この仕組みによりAPI呼び出しのトークン消費量を約46%削減しながら処理効率を大幅に向上させた実績がある。長期稼働するエージェントほど恩恵が大きくなる設計だ。初期設定のコストはかかるが、稼働時間が長くなるほどコスト削減効果が積み上がっていく。
まとめ
今回紹介した4つの手法・ツールを整理する。
- Parent-Child Chunking: 検索精度と文脈保持を両立する設計手法。まず最初に取り組むべきだ
- OpenViking: ファイルシステム型の階層コンテキストDB。複雑なエージェントに有効だ
- Uncertainty-Aware Pipeline: 自己評価でハルシネーションを抑える仕組み。信頼性重視の案件に向く
- OpenSpace: タスクをこなすほど賢くなる自己進化型エンジン。トークンコスト削減に直結する
RAGの精度向上は「一つの銀の弾丸」ではなく、チャンク設計・コンテキスト管理・不確実性制御・スキル再利用という複数の層を積み上げていく作業だ。
まずはParent-Child Chunkingから始めて、課題に応じて他の手法を組み合わせていくのが現実的なアプローチだ。
あなたが開発しているAIエージェントで、今一番課題に感じているのは「検索精度」「ハルシネーション」「トークンコスト」のどれだろうか。ThreadPostではAI開発の知見を継続的に発信している。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
