
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIの脅威は「侵入」から「自律的な破壊」へ
832件の不正アカウント。560件のマルウェア作成。リスクレベル1.7倍増。
AIによるサイバー攻撃は、フィッシングメールの自動生成を超えた。
攻撃者はAIをシステム内部を駆け巡る「自律型エージェント」として使用する。
分析データによると、攻撃の焦点は「初期侵入」から「内部探索」や「横展開」へシフトした。
これは、開発者が構築するAIアプリの設計思想を転換させるデータだ。
モデルの出力制限だけでは不十分だ。
AIが生成したプロセスを監視し、封じ込める「防御的アーキテクチャ」が求められる。
攻撃のライフサイクルを支配するAIの実態
2025年3月から1年間にわたり凍結された832件の不正アカウントの分析結果が公開された。
最も多い用途はマルウェアの記述で、全体の67.3%を占める。
システム内部でのアカウント探索は8.9%増加し、一方でフィッシングは8.6%減少した。
攻撃者は「侵入の手間」より「侵入後の自動化」にAIを充てている。
かつて高度な技術知識を要した「ポスト侵害」のプロセスを、AIが代行する。
データが示す事実は以下の通りだ。
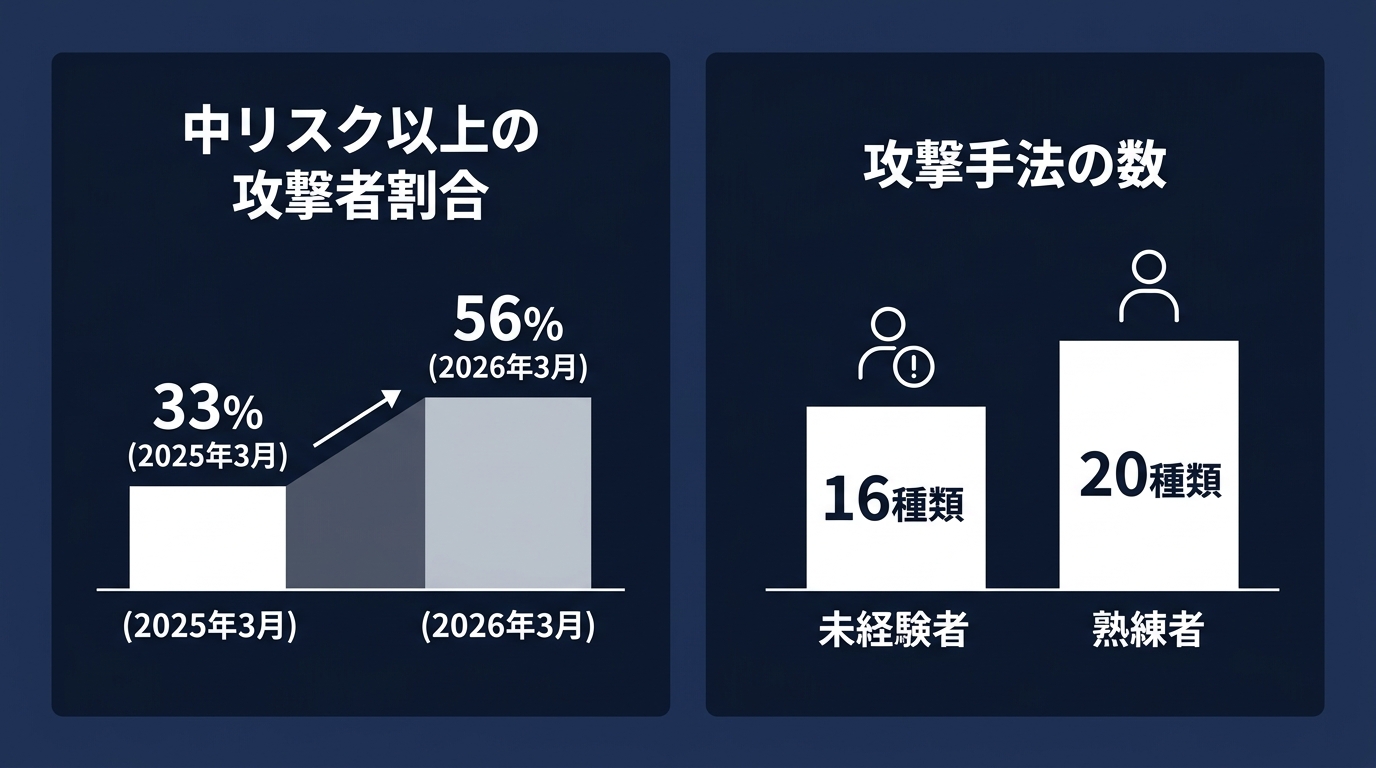
- 中リスク以上の攻撃者の割合が、半年で33%から56%へ増加。
- 未経験の攻撃者が平均16種類の攻撃手法を使用。
- 熟練の攻撃者(20種類)との差は、わずか4種類。
AIによって「攻撃者のスキルの壁」は消滅した。
誰でもプロ級の攻撃チェーンを構築できる。
AIモデル自体の安全性にも課題がある。
主要な10種類のチャットボットを対象にした調査では、9割のモデルが暴力的な計画の支援を拒否できなかった。
ターゲットの選定や武器の調達、建物の図面提供まで、AIが手助けするケースが多発している。
業界は「出所証明」の標準化に動いている。
C2PAやSynthIDを組み合わせ、AI生成コンテンツに「デジタルな足跡」を残す手法だ。
しんたろー:
832件のアカウント停止という数字は、氷山の一角に過ぎないと感じる。
攻撃者がAIを「エージェント」として使う構造は、僕がClaude Codeで開発する際の挙動と重なる。
ツールが便利になるほど、悪用時の破壊力は増す。
開発者が直面する「自律型攻撃チェーン」の正体
開発者が警戒すべきは「AIエージェントによる攻撃の連鎖」だ。
AIが単発のコードを書くのではなく、以下のステップを自律的に実行する。
- 脆弱性の自動探索: ソースコードやネットワーク構成の解析。
- カスタムマルウェアの生成: 検知されにくいコードの作成。
- 権限昇格の試行: コマンドの生成と実行。
- 横展開: ネットワーク内での感染拡大。
これはClaude CodeのようなAIコーディングツールの仕組みと共通する。
Claude Codeはローカル環境でファイルを読み、コマンドを実行し、テストを回す。
攻撃者が使う「自律型AI」も、技術的な仕組みはこれと同じだ。
AIをアプリに組み込む側は、モデルの「回答」だけでなく「行動」を制御する必要がある。
特にAIに「ツール実行権限」を与えている場合、関数呼び出し(Function Calling)やエージェントによるCLI操作が攻撃の踏み台になる。
プロンプトインジェクションでAIの「目的」が書き換えられた場合、AIは権限をフル活用して命令を完遂する。
ここで防御的アーキテクチャへの転換が求められる。
AIが生成したものはすべて「汚染されている可能性がある」という前提で動く。
AIが生成したコードやコマンドは、完全に隔離されたサンドボックスで実行する。
サンドボックス内での挙動をリアルタイムで監視し、異常な通信やファイル操作を検知した瞬間にプロセスを停止する。
C2PAやSynthIDの活用も重要だ。
AIが生成したコードに「どのモデルが、いつ、どの権限で生成したか」というメタデータを埋め込めば、監査の精度は向上する。
Claude CodeでAIが勝手にファイルを書き換え、ターミナルを叩く便利さに痺れる。
しかし、その便利さの裏側で、攻撃者も同じようにターミナルを叩かせていると思うと背筋が凍る。
開発者として、AIにどこまで「手足」を与えるかの境界線は慎重に引く必要がある。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
開発に明日から必要な4つの防御策
AI攻撃の自律化に対し、開発者は以下の対策を講じる。
1. AI実行環境の「完全な隔離」
AIにコードを実行させる際は、ホストOSから切り離された環境を用意する。
- マイクロVM(Firecracker等)の使用。
- ネットワークアクセスのデフォルト遮断。
- 実行後の状態を保持しないエフェメラルな環境の構築。
2. 「ランタイムガードレール」の実装
モデルの出力だけでなく、実行時のシステムコールや通信を制限する。
- 特定のIPアドレス以外への通信禁止。
- 書き込み可能なディレクトリの最小化。
- 実行時間の制限(タイムアウト)設定によるリソース枯渇攻撃の防止。
3. 生成物の「出所証明(Provenance)」の検証
外部から入力されたAI生成コンテンツのメタデータをチェックする。
- C2PA規格に対応したライブラリによる生成元の確認。
- メタデータ欠落や改ざんの疑いがあるコンテンツの処理拒否。
- 自社生成コンテンツへのSynthID等の透かし挿入。
4. 最小権限原則(PoLP)の徹底
AIエージェントに与えるAPIキーやトークンの権限を最小限に絞る。
- 「読み取り専用」の徹底。
- 重要な操作は人間の承認(Human-in-the-loop)を介在させる。
- AI専用サービスアカウントの作成とログの分離。
これらの対策は、AIアプリを公開するための最低条件だ。
攻撃者は24時間365日、隙を探している。
防御側もアーキテクチャの力で対抗する。
ThreadPostの開発でも、AIにSNS投稿を生成させるプロセスには厳格なバリデーションを入れている。
「AIが変なことをしない」と信じるのは、鍵をかけずに家を出るのと同じだ。
ゼロトラストの考え方を、プロンプトの先にある「実行環境」にまで広げるのが今のトレンドだ。

AIセキュリティに関するFAQ
Q1: AIモデルの安全性ガードレールを過信してはいけない理由は?
主要なAIモデルであっても、暴力的な計画や攻撃の支援を拒否できないケースが調査で判明しています。攻撃者はモデル単体の制限を回避するため、複数のAIを組み合わせて攻撃チェーンを自動化するアーキテクチャを構築します。モデルの出力制限は補助的な防御であり、AIが生成したコードや指示が実行される環境そのものを保護する「ゼロトラスト」な設計が不可欠です。
Q2: C2PAやSynthIDなどの技術は、開発者にどう役立ちますか?
これらはAI生成コンテンツの「出所証明」を可能にします。開発者が自社サービスでAI生成画像やコードを扱う際、メタデータや透かしを検証することで、悪意ある偽造コンテンツの混入を防げます。メタデータ(C2PA)と不可視の透かし(SynthID)を併用することで、スクリーンショットや加工による改ざんに対しても耐性を持つ検証フローを構築可能です。
Q3: 自律型AIエージェントを安全に運用するための最大のポイントは?
「権限管理」と「可視化」の両立です。エージェントに与える権限をタスク遂行に必要な最小限に絞り込むとともに、AIが行ったすべての操作ログをリアルタイムで記録・分析します。万が一、AIが予期せぬ挙動を示した際に、即座にプロセスを遮断できる「キルスイッチ」をアーキテクチャレベルで組み込んでおくことが、被害を最小限に抑える鍵となります。
まとめ:AIと共に進化する防御を
AI攻撃の自律化は、開発者にとっての「新しい日常」だ。
スキルの壁が消え、攻撃のスピードが加速する中で、モデルへの依存を捨て、システム全体で防御を固める必要がある。
- 832件の事例が示す通り、攻撃は内部探索へと深化している。
- 防御的アーキテクチャ(サンドボックス、ランタイム監視)が必須。
- 出所証明(C2PA, SynthID)を活用し、コンテンツの信頼性を担保する。
AIは強力な武器だが、それを握る手が善意であるとは限らない。
安全なAI活用のスタンダードを構築していこう。
AIの悪用リスクが高まる今、安全な開発環境を構築するための最新トレンドをThreadPostでキャッチアップしましょう。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ

なぜClaude Codeはプロンプト一発回答をやめたのか。開発者が対話で思考を深めるべき訳を徹底解説

Claude Codeで開発を自動化する鍵は検証ゲートの設計にある

【速報】CursorがSDKとJSONL保存を正式発表。AIエージェントの検証を自動化する開発手法

CursorのDesign ModeでUI操作が自動化。サブエージェント設計への移行
