
AIツールへの課金がかさんで困っていないだろうか。
最近、ローカルLLMのエコシステムが急速に成熟している。
クラウドAPIに依存せず、自分のPCだけで実用的なAI開発環境を作るのが現実的になってきた。
この記事では、月額0円でCopilot代替や高精度な文字起こしを構築するための実践的なTipsを10個紹介する。
結論から言うと、Ollamaと各種ツールを組み合わせるのが一番確実でコスパが良い。
初心者でも問題ない。順を追って解説する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
ローカルAI開発を加速するTips10選
1. Claude Codeをローカルで動かすプロキシ構築
セキュリティ要件が厳しくてクラウドAPIが使えない環境でも、Claude Codeを諦める必要はない。
Claude CodeのAPIリクエストをローカルLLM向けに変換するプロキシを自作する手法が非常に有効だ。
エンドポイントの違いやメッセージ形式の違い、さらにはツール呼び出しの方法まで、すべてプロキシ側で吸収する仕組みを作る。
これにより、AnthropicのAPIに接続しなくても、ローカル完結の自律的コーディング環境を実現できる。
機密性の高い社内のソースコードを外部のサーバーに送信することなく、安全にAI駆動の開発を進められるようになる。
コンプライアンスを遵守しながら最新のAIツールを活用したい開発者にとって、まさに救世主となるアプローチだ。
ネットワークから完全に切り離されたオフライン環境でも、強力なAIアシスタントを傍らに置いて開発を進められる。
しんたろー:
ThreadPostの開発でもセキュリティは常に意識しているが、ローカルで完結する安心感は格別だ。
クラウドにコードを送らずに済むので、どんな機密ロジックでも躊躇なくAIに相談できる。
2. エージェント用途にはDenseモデルを選ぶ
Claude Codeのようなツール呼び出し主体のエージェントを動かすには、ローカルLLMのモデル選びが極めて重要になる。
結論から言うと、生成速度が速いMoEモデルよりも、全パラメータが常にアクティブなDenseモデルを選ぶのが正解だ。
たとえばQwenシリーズの27Bモデルなどが、エージェント用途の有力な候補となる。
MoEモデルは速度面で有利だが、複雑な推論を連続で行うエージェントタスクではエラーループに陥りやすい傾向がある。
一方、Denseモデルは推論能力が高く、ステップをスキップすることなく実用的なコードを安定して出力してくれる。
複雑なタスクを自律的にこなしてもらうなら、迷わずDenseモデルを選択するといい。
メモリ消費は大きくなるが、その分だけ確実な成果を出してくれる頼もしい相棒になるはずだ。
3. 高速・省メモリな文字起こし環境の構築
ローカルで音声の文字起こしを行う際、公式のパッケージをそのまま使うのはおすすめしない。
CTranslate2をベースにした高速化ツールと、軽量化されたturboモデルの組み合わせが現在の最適解だ。
この構成を採用することで、公式パッケージの4倍の速度を出しつつ、VRAMの消費量を半分以下に抑えられる。
同等の高精度な音声認識能力を維持したまま、圧倒的なパフォーマンスを叩き出せる。
VRAMが8GBしかない一般的なグラフィックボードでも、余裕で大規模モデルを動かせるようになる。
長時間の会議音声も、ほんの数十秒でテキスト化できるため、業務効率が劇的に向上する。
4. 無音区間のハルシネーション対策
文字起こしAI特有の厄介な弱点として、無音区間で存在しない発話を勝手に生成してしまうハルシネーション現象がある。
これを防ぐため、推論を実行する際に音声区間検出のフィルタを必ず有効化するといい。
VADと呼ばれるこの技術を使うことで、AIが無音区間を自動でスキップし、出力テキストの品質を大幅に向上させることができる。
この設定を一つ追加するだけで、後から不自然なテキストを手作業で修正する手間が劇的に減るはずだ。
精度の高い議事録や字幕データを作るなら、絶対に外せない必須のテクニックと言える。
5. 処理時間によるローカルとAPIの使い分け
音声の文字起こし環境は、月間の処理時間によってローカルとAPIを使い分けるのが賢い選択だ。
コストと手間のバランスを考慮すると、月間500時間以上の大量の音声を処理する場合や、絶対に外部に出せない機密データを扱う場合は、ローカル環境の構築が圧倒的に有利になる。
それ以下の処理量であれば、1分あたり約0.4円と非常に安価なクラウドAPIを利用する方がいい。
環境構築の手間をかけることなく、高精度な文字起こし結果をすぐに得られる。
自分の用途とデータ量に合わせて、最適なアプローチを選択するといい。
6. 月額0円のコード補完サーバー構築
毎月のサブスクリプション費用を削りたいなら、自前のコード補完サーバーを立てるのがおすすめだ。
ローカルのGPU環境にOllamaとFastAPIを組み合わせることで、OpenAI互換のAPIを簡単に構築できる。
VS Codeの拡張機能からこのローカルサーバーを直接参照するように設定すれば、月額費用ゼロで快適な開発体験を得られる。
機密性の高いプロジェクトでも、ソースコードが外部のクラウドに漏れる心配が一切ない。
初期のセットアップさえ終わらせてしまえば、あとは無料で無限にコード補完を使い放題になる。
ランニングコストを抑えつつ、セキュアな開発環境を手に入れたい人にぴったりだ。
チーム全員で高いサブスクリプション費用を払い続ける現状から、一気に脱却できる。
7. コード補完に特化したモデルの選定
ローカルコード補完サーバーのバックエンドには、汎用モデルではなくコーディングに特化したモデルを配置するのが推奨される。
たとえば、約8.9GBのVRAM消費で動くコーディング特化の軽量モデルなどが非常に優秀だ。
このクラスのモデルであれば、一般的なゲーミングPCでも高速な推論が可能であり、実用的なレスポンス速度と高いコード生成精度を両立している。
汎用の対話モデルを使うよりも、はるかに的確でプロジェクトの文脈に合ったコードを提案してくれる。
メモリ容量と推論速度のバランスを見極めながら、自分のPC環境に最適なモデルを探してみるといい。
8. 文脈を読める高度なコード補完の実現
単純にカーソル位置の続きを生成するだけでなく、前後のコードを考慮した高度な補完も可能だ。
カーソル位置の前後のコードをモデルに渡し、その間を埋めさせる専用のプロンプトフォーマットを実装するといい。
これにより、後続の関数呼び出しやリターン処理を事前に考慮した、より的確で文脈に沿ったコード補完が可能になる。
たとえば、後で特定の変数を返す必要があることを理解した上で、その変数に適切な値を代入する処理を書いてくれる。
この仕組みを取り入れることで、AIの提案精度が一段階上がり、手直しの手間が大きく減るはずだ。
単なる行補完から、関数全体の構造を見据えた賢いコーディングアシスタントへと進化させられる。
9. マルチエージェント環境での出力安定化
複数のAIエージェントを連携させて複雑なタスクを処理するシステムでは、アクションをJSONなどの特定の形式で確実に出力させることが不可欠だ。
ローカル環境では、指示追従性と出力フォーマットの安定性に優れたモデルを選定することがシステムの命運を分ける。
フォーマット遵守に強いモデルを採用することで、余計な挨拶や説明文が混入するのを防ぎ、パースエラーによるシステムの停止を回避できる。
さらに、プロンプト内で「指定したデータ形式のみを出力し、他のテキストは一切含めないこと」と強く念押しするのも効果的だ。
安定したエージェント連携を実現するために、モデル選びには妥協しないようにするといい。
10. 軽量な自作コントローラーによる制御
複雑なエージェント制御を行う際、既存の巨大なAIフレームワークを使うと内部処理がブラックボックス化しやすい。
そのため、Pythonを使ってAPIを直接叩く軽量なコントローラーを自作するアプローチが非常に有効だ。
自作することで、ログの出力やフェーズ進行の制御が格段に容易になり、システム開発時のデバッグ効率が圧倒的に向上する。
裏側で何が起きているのかを完全に把握できるため、予期せぬエラーやAIの暴走にもすぐに対処できる。
自分だけの小さな箱庭環境を作って、エージェントたちがどのように相互作用するのかを観察してみると面白い。
しんたろーのイチ推しTips
数あるTipsの中でも、僕が一番おすすめしたいのは「月額0円のコード補完サーバー構築」だ。
Claude Codeで毎日コード書いてる身からすると、ローカルプロキシを構築してAPI費用をゼロにするアプローチが一番魅力的だった。
理由はシンプルで、コストを気にせずエラーの修正やリファクタリングを無限にAIへ任せられるからだ。
一度環境を作ってしまえば、あとはOllamaを起動するだけでいつでも自分専用のAIアシスタントが立ち上がる。
最初は少しハードルが高く感じるが、やってみる価値は十分にある。
まずは軽量モデルをダウンロードするところから始めるといい。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
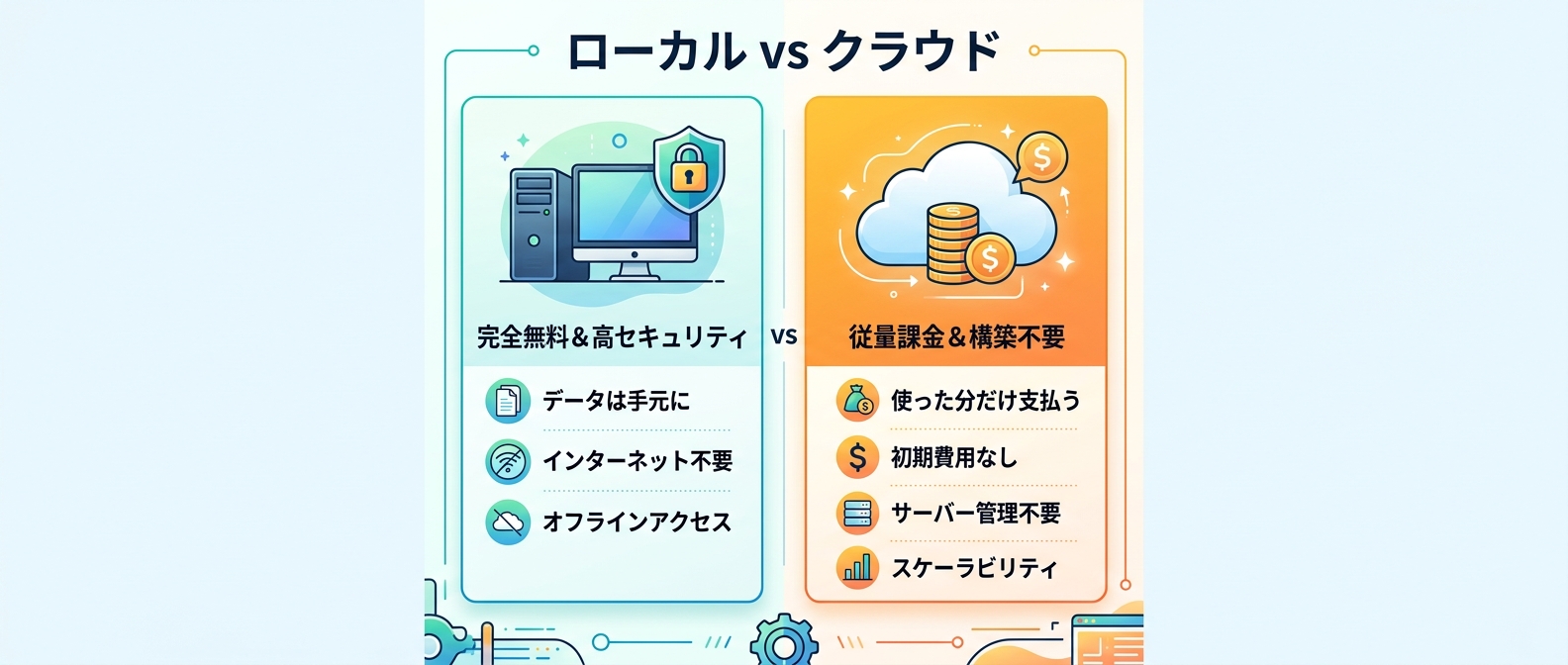
環境比較表
ローカル環境とクラウドAPIのどちらを選ぶべきか、迷った時のための比較表を用意した。
用途に合わせて最適な選択をするといい。
| 比較軸 | ローカルLLM環境 | クラウドAPI環境 | おすすめなケース |
| :--- | :--- | :--- | :--- |
| ランニングコスト | 完全無料 | 従量課金(使った分だけ) | 毎日長時間AIを利用する場合 |
| 初期構築の手間 | かかる(ソフト導入必須) | ほぼなし(キー発行のみ) | 手軽にすぐ始めたい場合 |
| セキュリティ | 最高(データが外に出ない) | クラウド事業者に依存する | 機密性の高いデータを扱う場合 |
| 推論速度 | PCのGPU性能に大きく依存 | 安定して高速な処理が可能 | 高性能なPCを持っていない場合 |
| モデルの自由度 | 好きな特化モデルを選べる | 提供されているモデルのみ | 用途に合わせてAIを変えたい場合 |
よくある質問(FAQ)
Q1: ローカルLLMを動かすにはどれくらいのスペックのPCが必要か?
用途によって異なるが、実用的な速度で動かすにはNVIDIA製のGPUが推奨される。
小規模なコード補完モデルであれば、VRAMが8GBのモデルでも十分に動作する。
一方、高性能なモデルを快適に動かすには、VRAMが16GB以上あると安心だ。
自分のPCスペックに合わせて最適なモデルを選ぶことが重要になる。
グラフィックボードへの投資は、長期的なクラウドAPI利用料の削減効果を考えると十分に元が取れる計算になる。
Q2: 既存の有料コード補完ツールからローカルLLMに乗り換えるメリットとデメリットは何か?
最大のメリットは、月額費用が0円になることと、ソースコードが外部に送信されない点だ。
機密性の高いプロジェクトでも安全に使えるのは大きな強みと言える。
デメリットは、初期の環境構築に手間がかかることと、PCの電力消費が増えることだ。
最新のクラウド型AIと比べると、対応言語の幅でやや劣る場合もある。
Q3: Ollamaとは何か?初心者でも簡単に使えるツールか?
Ollamaは、ローカル環境で大規模言語モデルを簡単に実行・管理できるオープンソースのツールだ。
コマンド一つでモデルをダウンロードし、すぐにチャットやAPIとして利用できる。
複雑な環境構築を意識せずに済むため、初心者でも非常に扱いやすい。
ローカルAI開発のデファクトスタンダードとなっている必須ツールだ。
Q4: 文字起こしをする際、ローカル環境とAPIのどちらを選ぶべきか?
処理する音声の量とデータの機密性で判断するといい。
月間500時間以上の大量の音声を処理する場合や、機密性の高い音声の場合はローカル環境を構築するべきだ。
一方、たまにしか文字起こしをしない場合は、安価なクラウドAPIを利用するのが最もコストパフォーマンスが高い。
手間とコストのバランスを見て決めるのがおすすめだ。
Q5: ローカルLLMが期待通りの形式で出力してくれず、エラーになる場合の対策はあるか?
ローカルの小〜中規模モデルは、プロンプトで指示しても余計なテキストを含めてしまうことがよくある。
対策として、出力の安定性に定評のあるモデルを選定することが重要だ。
また、プロンプト内で「指定した形式のみを出力し、他の説明は一切含めないこと」と強く念押しするといい。
ツールのオプション機能で出力形式を固定するのも効果的だ。
まとめ
この記事では、月額0円で構築するローカルAI開発環境のTipsを10個紹介した。
まとめると以下のようになる。
- Ollamaを活用すれば、初心者でも簡単にローカルAI環境を作れる
- 用途に合わせてDenseモデルや特化型モデルを使い分けるのがコツだ
- 文字起こしやコード補完は、ローカルとAPIのメリットを比較して選ぶといい
ローカルLLMの世界は日々進化しており、個人でも強力なAIを使いこなせるようになっている。
自分のPCに環境を構築して、快適な開発ライフを手に入れるといい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
