
推論速度1000 TPSの時代が到来した。
エージェントのボトルネックは、AIモデルの推論速度からAPIの通信速度へと移行した。
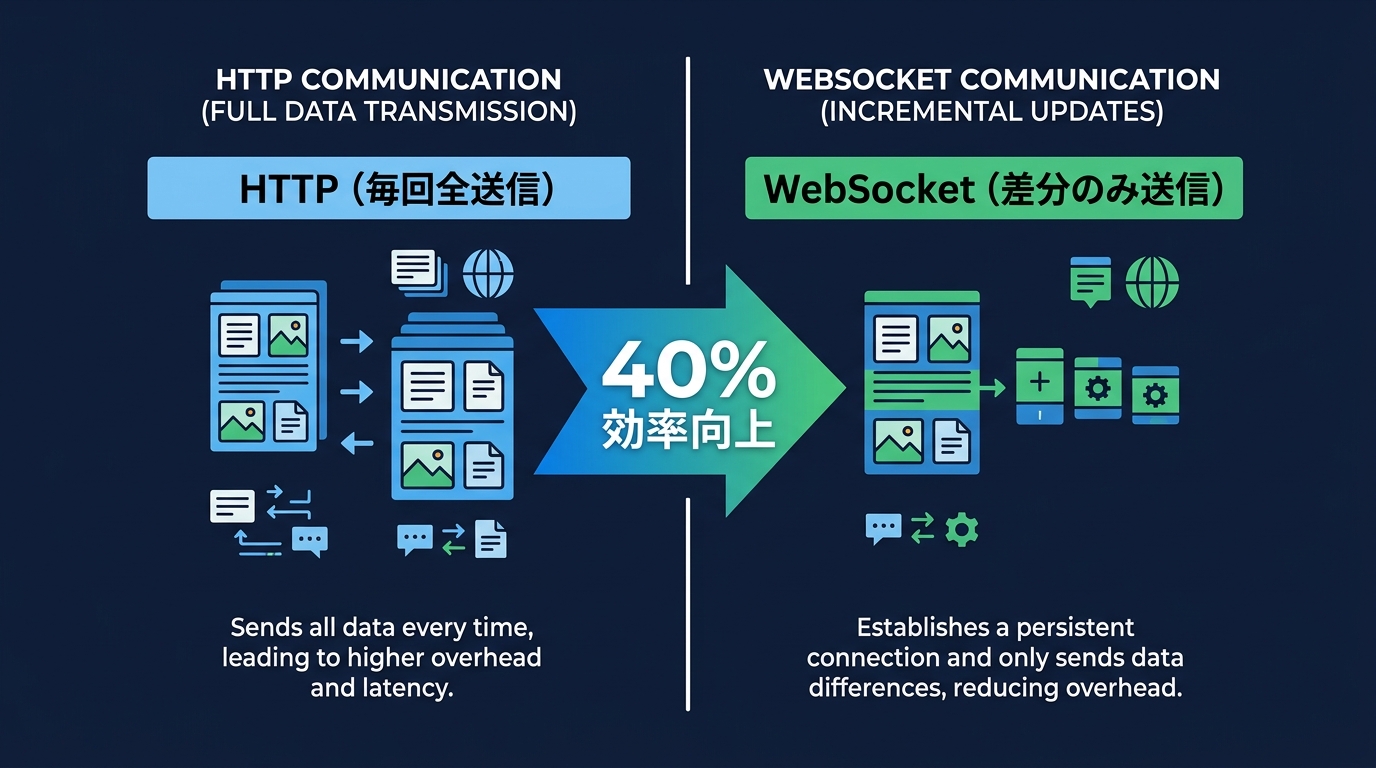
OpenAIはWebSocketによる持続的接続を導入し、エージェントループ全体で40%の高速化を実現した。
これはインフラ層のアップデートであり、開発者のコードの書き方やAIとの向き合い方に影響を与える。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
APIの通信速度がボトルネックになった理由
エージェントがバグ修正を行う際、AIは関連ファイルの検索、読み込み、編集箇所の特定、コードの書き換え、テスト実行を繰り返す。
この過程で、何十回ものAPIリクエストが往復する。
かつてはGPUによる推論自体が遅く、APIの通信オーバーヘッドは隠れていた。
専用ハードウェアの最適化により、推論速度は従来の65 TPSから1000 TPSへと向上した。
モデルは一瞬で答えを出すようになった。
結果として、CPUが処理するAPIサービスの通信オーバーヘッドがボトルネックとして浮上した。
ユーザーは、高速なGPUを使うために、遅いCPUの処理完了を待つ状態となった。
従来のHTTPベースのAPI呼び出しは、リクエストごとに独立している。
会話の履歴やプロジェクトのコンテキストを、毎回ゼロから再送信して処理する必要があった。
会話が長くなるほど、この再送信のコストは増大する。
変更されていないコンテキストの処理に、時間とリソースが割かれていた。
この構造を解決するために、WebSocketによる持続的な接続が導入された。
WebSocketは、サーバーとクライアントの間で接続を維持する。
一度送信したコンテキストは保持され、必要な差分だけをやり取りする。
同期的なAPI呼び出しの連続から、ストリーミングベースの非同期通信へ移行した。
このインフラ層の改修により、最初のトークンが出力されるまでの時間は45%改善された。
エージェントがタスクを完了するまでのエンドツーエンドの時間は40%短縮された。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。

エージェントを飼い慣らす「Harness Engineering」
通信速度が向上したことで、無駄な通信や推論のコストが相対的に重くなる。
ここで「Harness Engineering」という概念が活用される。
開発者の仕事は、エージェントが迷わず働ける環境を設計することである。
強力なAIモデルを正しい方向へ導くための「手綱」を作る作業だ。
AIモデル本体以外の、ドキュメント、制約事項、リンター、テストコード、アーキテクチャのルールがこの手綱に含まれる。
エージェントがミスを犯したとき、環境側をアップデートする。
巨大なプロンプトにすべてを詰め込むことは避ける。
一つのファイルにプロジェクトの全知識を書き込み、毎回AIに読み込ませることは、コンテキストウィンドウの浪費であり、推論精度の低下を招く。
情報の構造化と分割を行う。
プロジェクトのルートには「AGENTS.md」のようなインデックスファイルを置く。
これは全体のアーキテクチャを示す100行程度の目次に留める。
詳細な設計やルールは「docs/」ディレクトリ配下に分割して配置する。
エージェントは目次を読み、現在のタスクに必要なドキュメントだけを自律的に参照する。
ノイズが減り、AIの回答の精度が向上する。
厳格な層状アーキテクチャを導入する。
依存関係の方向をルール化し、違反するコードはCIで機械的に弾く。
認証やログ出力などの横断的な処理は、単一のインターフェースを通すように強制する。
エージェントに自由を与えすぎると、独自の解釈で複雑なコードが生成される。
選択肢を狭め、正しい道しか通れないようにレールを敷く。
Claude Codeには「CLAUDE.md」やカスタムコマンドの機能が備わっている。
これらは「手綱」を実装するためのツールキットだ。
インフラ層でWebSocketが通信の無駄を省いたように、アプリケーション層でコンテキストの無駄を省く。
しんたろー:
Claude Codeに丸投げしていると、この「手綱」の重要性を感じる。
指示が曖昧だと無限ループに入ってAPI代が消費される。
ドキュメントの構造化は避けて通れない工程だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
コストと速度を両立する開発の実践
エージェントを自律的に動かすと、APIの利用コストが課題となる。
AIにすべてを任せると、予算を30%オーバーする事例がある。
推論速度が1000 TPSになっても、トークン単価は変わらない。
速くなった分、短時間で大量のトークンを消費する。
指示の解像度を上げる。
「このバグを直して」という指示は、AIに複数の解釈を許す。
修正と再修正のループが発生し、無駄なトークンが消費される。
指示は具体的かつ限定的に行う。
「ファイルAの45行目から67行目、入力値が空の時のクラッシュを修正。テストケースはファイルBへ」と指定する。
これにより、AIの修正ループは3回から1回に減る。
モデルの適材適所な使い分けを行う。
複雑なアーキテクチャ設計やコードレビューにはSonnetを使う。
単純なスクリプトの修正やドキュメントの生成にはHaikuを使う。
モデルを切り替えることで、コストを80%削減できる場合がある。
リクエストのバッチ化を行う。
細切れの修正依頼を避け、関連するタスクを1回のリクエストにまとめる。
毎回コンテキストを送信するオーバーヘッドを削減する。
* 指示の解像度を上げ、再試行を防ぐ
* タスクの難易度に合わせてモデルを切り替える
* 関連するタスクをまとめてバッチ処理にする
これらはシステム全体のパフォーマンスを最適化するためのエンジニアリングである。
Haikuの使い所は見落としがちだ。
脳死で一番賢いモデルを使うと、月末の請求書を見て驚くことになる。
ログの整形などの単純作業ならHaikuで十分だ。

エージェント開発のよくある疑問 (FAQ)
Q1: Harness Engineeringを導入する最初のステップは何ですか?
リポジトリのルートに「AGENTS.md」を作成します。
ここにプロジェクトのアーキテクチャやコーディングの制約を、100行程度の目次形式で記述します。
次に、詳細な設計ドキュメントを「docs/」ディレクトリ配下に分割して配置します。
エージェントが参照すべきソースを明確にすることで、推論のブレを抑え、無駄な修正ループによるコスト増を防ぎます。
Q2: APIコストを削減するために、具体的に何をすべきですか?
3つのアプローチがあります。
複雑な設計にはSonnet、単純な修正にはHaikuと、タスクに応じてモデルを使い分けること。
細切れの修正依頼を避け、関連するタスクをバッチ処理として一度にリクエストすること。
そして、修正対象のファイル名や行数、期待するテストケースを具体的に指定し、指示の曖昧さを排除することです。
AIの再試行回数を最小限に抑えられます。
Q3: WebSocketによる持続的接続は、既存のHTTP通信と何が違いますか?
従来のHTTP通信では、リクエストの度に会話履歴やプロジェクトのコンテキストをすべて再送信する必要がありました。
これが通信オーバーヘッドを生んでいました。
WebSocketを使えば、サーバーとの接続を維持したまま、変更された差分データだけをやり取りできます。
最初のトークン生成までの時間が短縮され、エージェントの反応速度が向上します。
AIが賢くなるほど、人間の言語化能力と設計力が試される。
雑なコードを書くAIを責める前に、自分のプロンプトとドキュメントを見直す必要がある。
便利な道具ほど、使い手の基礎力が結果に反映される。
まとめ
推論速度の向上により、エージェント開発のボトルネックは通信とコンテキスト管理に移行した。
開発者の役割は、コードを書くことから、エージェントが迷わず動ける環境を設計する仕事へとシフトしている。
適切なドキュメント構造の構築とリクエストの最適化が、AI開発の生命線となる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
