
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
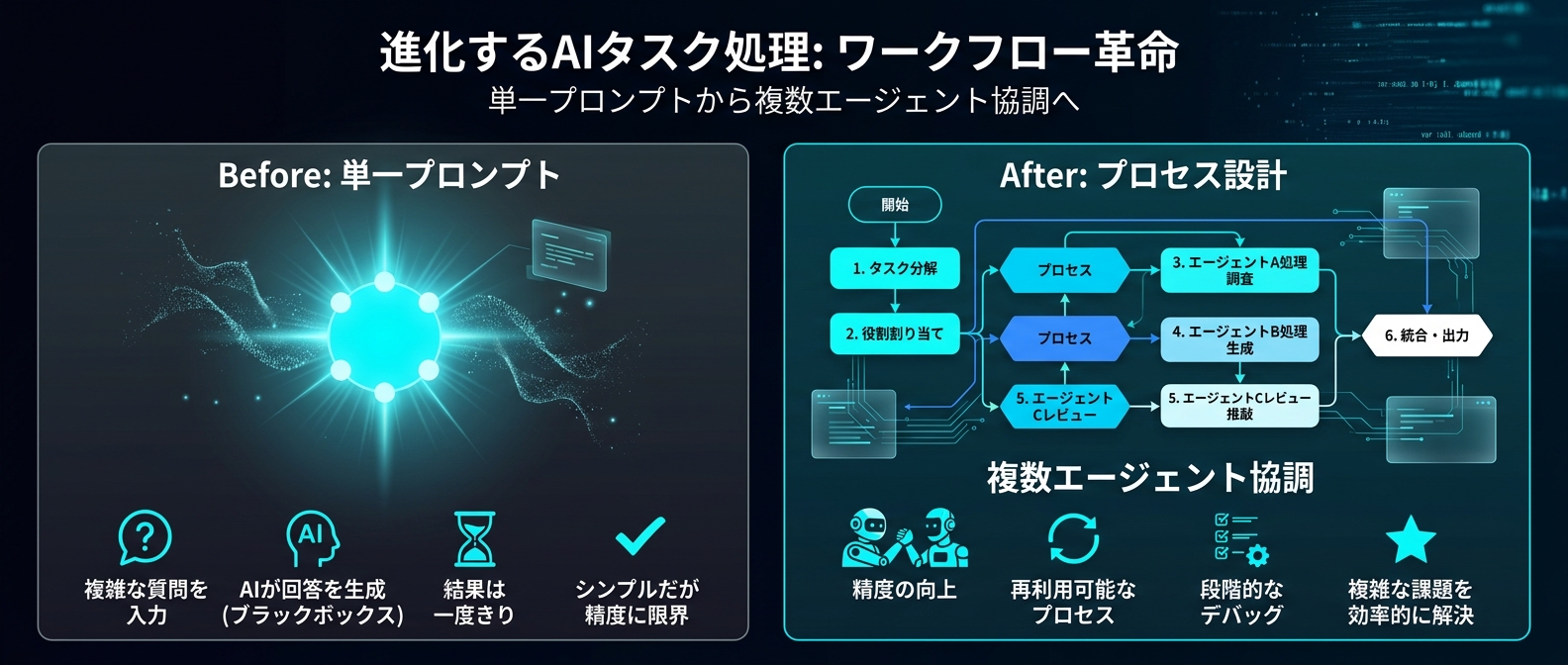
Cursor 3.0の複数エージェント並行稼働
Cursor 3.0がリリースされた。
複数エージェントが並行稼働する。
ローカル環境で稼働する。
worktreesで稼働する。
クラウド環境で稼働する。
リモートSSH環境で稼働する。
Cmd+Shift+Pを入力する。
Agents Windowを起動する。
いつでもIDEに戻ることができる。
両方を同時に開くこともできる。
Agent Tabsを使用する。
複数のチャットを一度に表示する。
横並びで表示する。
グリッドで表示する。
複数エージェントを無策で走らせるとプロジェクトは停止する。
AIの知能の問題ではない。
人間側のプロセス設計の欠如が原因だ。
最新のマルチエージェント環境で直面する引き継ぎの失敗について話す。
3課題2構成5回30回の検証結果
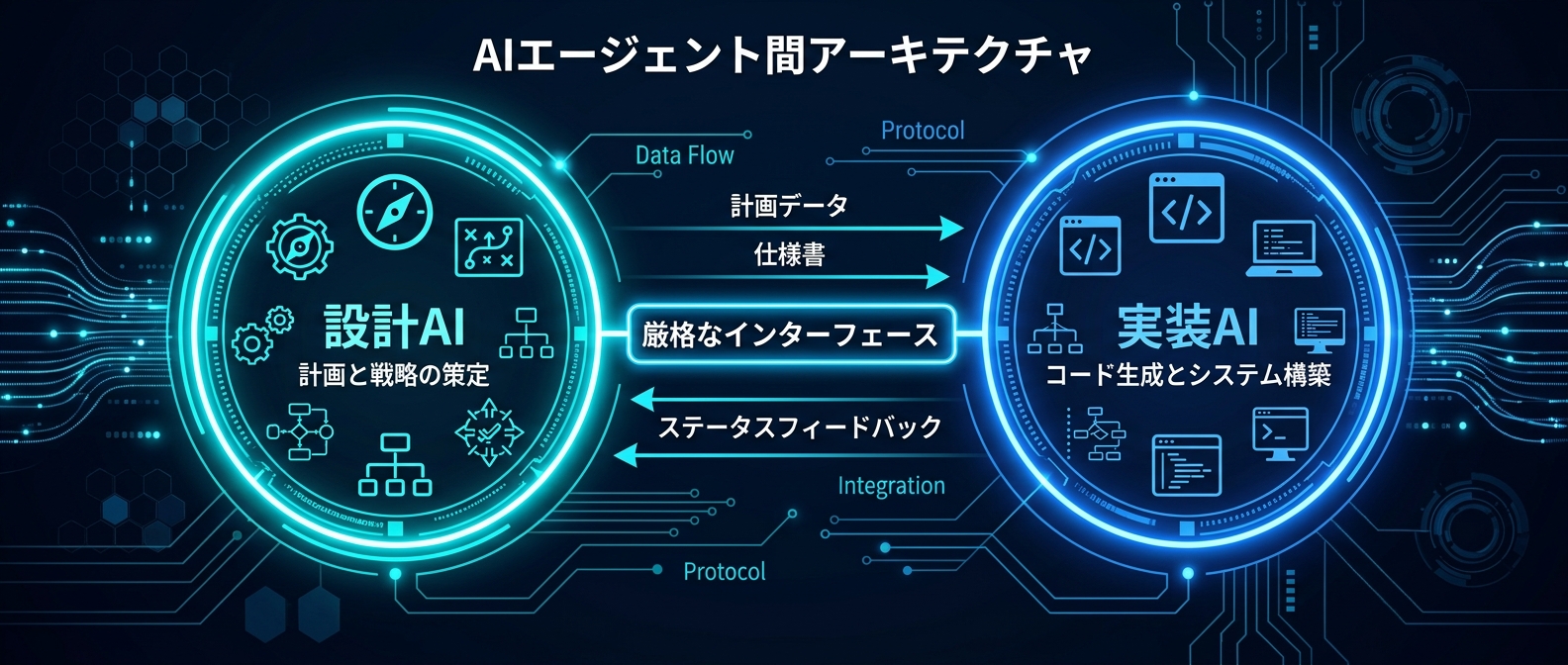
設計から実装までを1つのAIに任せるか。
設計と実装を別々のAIに分業させるか。
Qwen3.5を使用した検証がある。
Ollamaを使用した検証がある。
Claude Codeを使用した検証がある。
todo-liteという小さなWebアプリ課題だ。
notes-tagsという小さなWebアプリ課題だ。
booking-flowという小さなWebアプリ課題だ。
3課題、2構成、5回、合計30回の検証をやり直した。
llm_onlyとllm_slmの比較だ。
think=falseを固定した。
既存の成果物を流用せず毎回新しく生成する条件だ。
llm_slmの失敗が目立った。
設計役から実装役への受け渡しで停止する。
成果物形式が崩れる。
前提が崩れる。
責務分担が崩れる。
これがhandoff failure、引き継ぎの失敗だ。
実装役が成果物の約束事を守れない。
分業の利点を評価する前に失敗する。
llm_onlyは最後の方で失敗することが多い。
ファイルは出る。
テストも一部は動く。
状態遷移のロジックで崩れる。
モジュールの取り込み方で崩れる。
最後の境界条件で崩れる。
llm_slmはもっと早い段階で止まることが多い。
think=trueを試した。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
しんたろー:
3課題2構成5回30回の検証結果が気になる。
複数のAIが協調する環境でのインターフェース設計の難しさを感じた。
ツールが便利になっても人間の設計責任は消えないと思った。
35bモデルと計画の型
todo-liteで1回だけ軽い確認を行った。
設計役から実装役への受け渡しだ。
35bから35bへの受け渡しだ。
最小の課題は通る。
実装役の性能を上げると結果が変わる。
設計役と実装役をどちらも35bに固定した。
変えたのは計画の形だけだ。
補助指標としてnode --testのテスト件数を見た。
後付けの制約文は実装役を混乱させる。
設計役の生出力がまとまっているなら手を加えない方がよい。
長い制約文を足すより読み違えにくい仕様にする。
notes-tagsで設計書は固定した。
実装役だけ差し替えた。
各パターンを1回ずつ確認した。
有望だったものだけ追加で確認した。
同じ計画をより安定して実装できる実装役に渡した。
設計書自体は十分使える水準にあった。
失敗の多くは実装役側の受け渡しに引きずられていた。
実装の安定性に引きずられていた。
Codexの実装役を固定した。
計画の差が見えるようになる。
notes-tagsで比較した計画のパターンは3つだ。
hybridが最も良かった。
domainの分離が出た。
appの分離が出た。
infraの分離が出た。
uiの分離が出た。
mainの分離が出た。
テスト面も最も厚くなった。
十分に安定した実装役がないと計画の差は見えない。
条件がそろうと計画の形は結果に影響する。
タスクごとに計画の型を変える。
初期実装で使いやすい計画がある。
そのまま調査やリファクタリングに持ち込んでも機能しない。
task-plan-builderという計画作成スキルを使用した。
計画の分岐を切り替えるスキルだ。
notes-tagsの計画を作った。
そのままCodexの実装役に実装させた。
node --testは7件passだった。
0件failだった。
テストは通ったが、僕の書いたコードは1行もない。
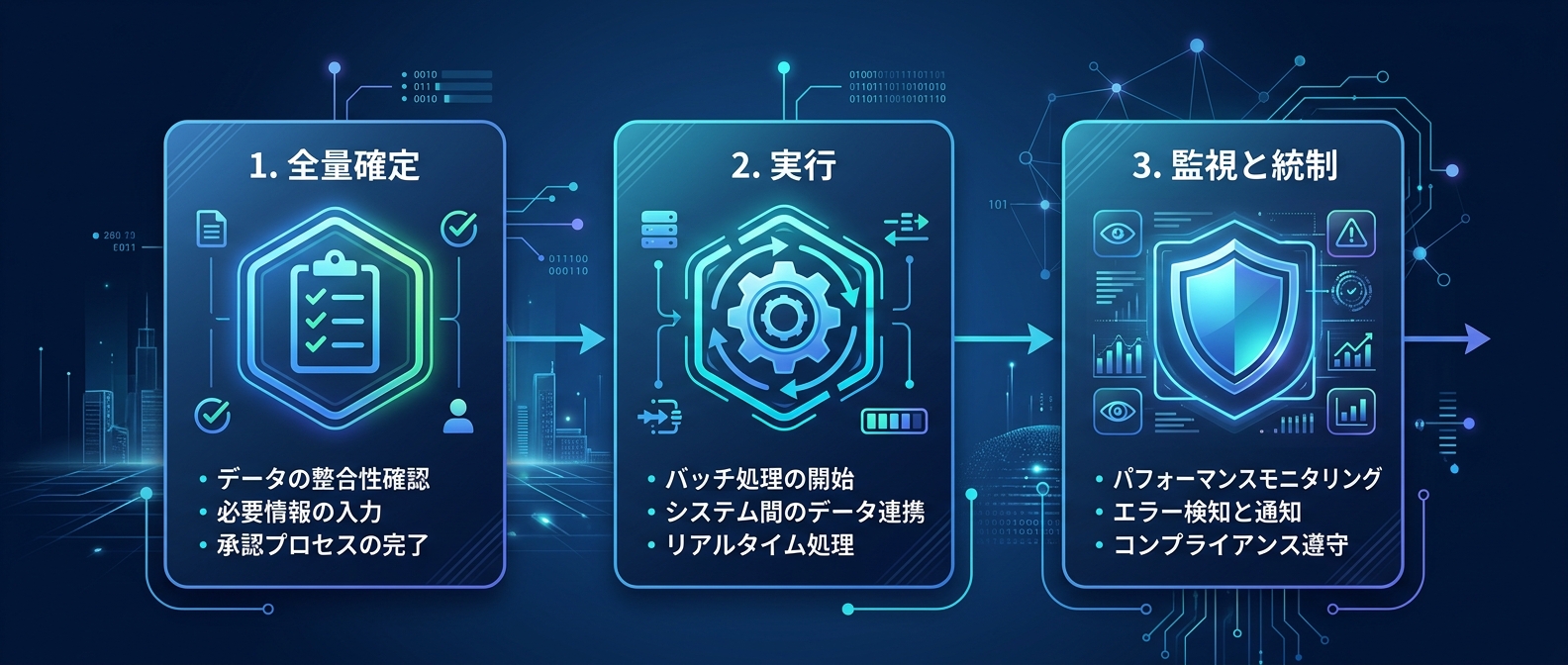
実行漏れを防ぐ5フェーズのプロセス設計
AIがチェック項目を素通りする問題がある。
属性の利用が適切かどうかという観点だ。
以前のレビューでは指摘が返ってきていた。
今日の出力にはその痕跡がない。
コードが変わったのか。
観点の解釈がブレたのか。
処理されたのか。
出力を読んでも判断できなかった。
フォルダを渡した。
AIは中身を把握した。
そのまま処理に入った。
何ファイルを対象にしたか記録する工程がなかった。
どのファイルにどの観点を適用したか記録する工程がなかった。
属性利用レビューが実行されたか確認する手段がなかった。
AIは返答できる。
何を処理し何を処理していないかを自分では保証しない。
それを観測する構造が指示の側になかった。
実行を5つのフェーズに分離した。
各フェーズに入力を持たせた。
出力を持たせた。
完了条件を持たせた。
PMBOKから名前を借りた。
Startupは前提確認のフェーズだ。
レビュー対象のソースが存在するか確認する。
レビュー観点を定義したファイルが存在するか確認する。
設計エビデンスが存在するか確認する。
前提が欠けていればunknownを記録して止まる。
ここを飛ばすと後続のフェーズは砂の上に立つ。
5フェーズの分離アプローチが気になる。
対象リストを作らせて突き合わせるステップの有効性を感じた。
チェックリストの存在がAIの挙動に影響すると思った。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
管理マトリクスの作成と実行
Planningは全量を確定するフェーズだ。
対象ファイルの一覧を作る。
適用するレビュードメインの一覧を作る。
この2つが揃ってファイルとドメインの管理マトリクスが生まれる。
Planningを飛ばすと何をやるつもりだったか不明になる。
どこまでやったか不明になる。
抜けたかどうかも不明になる。
未実施を未実施として検出するための唯一の前提だ。
Executionでマトリクスの各項目を処理する。
処理が終わった項目にはチェックを入れる。
チェックが入った項目だけが照合の対象になる。
差分確認と完了条件の定義
Monitoring and Controlは差分を確認する工程だ。
新たな判断をする工程ではない。
Planningで確定したマトリクスとの差分を確認する。
全ドメインに結果が記録されているか見る。
根拠のない判断が混入していないか見る。
未処理の項目が残っていないか見る。
未処理が見つかればExecutionに戻す。
根拠のない判断はunknownに格下げする。
漏れを許さない工程だ。
Closureでマトリクスの全行が確定したことを確認する。
doneで確定する。
unknownで確定する。
out_of_scopeで確定する。
全行確定を確認してから完了宣言を出す。
未解決項目の引き継ぎを報告する。
未処理が観測可能になった。
証拠不足が観測可能になった。
前提欠落が観測可能になった。
AIが返答した状態は完了ではない。
マトリクスの全行が確定した状態が完了だ。
属性利用レビューが抜けていたのも観測する構造がなかったからだ。
Planningでマトリクスが作られる。
Monitoring and Controlが差分を確認する。
実行されなかったという事実が見えるようになる。
フェーズを持つことで未実施が観測可能になる。
未確認が観測可能になる。
証拠不足が観測可能になる。
複数エージェントとプロセス設計の統合知見
Cursor 3.0の複数エージェント環境と5フェーズのプロセス設計は密接に絡む。
複数のAIが同時に動く環境では引き継ぎの失敗が多発する。
Qwen3.5やCodexを用いた検証でも明らかだ。
3課題2構成5回30回の検証がそれを示している。
StartupからClosureまでの5フェーズを導入する。
管理マトリクスによる監視が複数エージェントの暴走を防ぐ。
AI間のインターフェースを極限まで硬くする。
タスクの性質に合わせて計画の型を変える。
新規実装とリファクタリングでは欲しい計画が違う。
調査でも欲しい計画が違う。
全部同じ指示文で片づけようとすると破綻する。
実装上の約束を安定して守れない実装役に曖昧な計画を渡す。
分業の利点を評価する前に引き継ぎで失敗する。
実装役が成果物を出せるかどうかが問われる。
渡す計画が読み違えにくいかどうかが問われる。
ここが揃わないとモデル構成の議論は空回りする。
十分な実装役がある。
タスクに合った計画を作れる。
分業は機能し始める。
最適なモデル構成より先に最適な計画方針を立てる。
計画の型を変えるアプローチが気になる。
プロンプトを長くするより境界を与える方が効果的だと思った。
ワークフローの設計が今後の開発にどう影響するか注視したい。
FAQ
Q1: Cursor 3.0の複数エージェントを動かす際の問題点は何ですか?
設計役から実装役への受け渡しで成果物形式や前提が崩れる引き継ぎの失敗が発生します。
Qwen3.5やClaude Codeを用いた3課題2構成5回30回の検証でもllm_slmの失敗が目立ちました。
実装役が成果物の約束事を守れないとプロジェクトは停止します。
Q2: AIの実行漏れを防ぐための5フェーズとは何ですか?
Startup、Planning、Execution、Monitoring and Control、Closureの5フェーズです。
Planningでファイルとドメインの管理マトリクスを作成します。
Monitoring and Controlでマトリクスとの差分を確認し、未処理をExecutionに戻します。
Q3: エージェントへの指示は詳細に書く方が良いですか?
後付けの長い制約文は実装役を混乱させます。
notes-tagsの検証ではtask-plan-builderを用いて計画の型を変えるアプローチが有効でした。
Codexの実装役でnode --testが7件pass、0件failという結果が出ています。
マルチエージェント環境はプロセス設計のテスト場だ。
人間が強固なワークフローを構築する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
