
DeepMindがGemma 4を正式にリリースした。
これは単なるテキスト生成AIではない。
複雑な論理処理とエージェントワークフローに特化して設計されている。
26BのMoEモデルが、コンシューマーGPUでネイティブに動く。
クラウドAPIへの依存から脱却する。
手元の環境でAIがコードを書き、テストを回す。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIの主戦場は「チャット」から「自律実行」へ
AIの進化の方向性が明確に変わった。
DeepMindが発表したGemma 4は、人間と雑談するためのモデルではない。
複雑な論理を処理し、ツールを使いこなし、タスクを完遂するエージェントワークフローに特化している。
AIは答える存在から実行する存在へとシフトした。
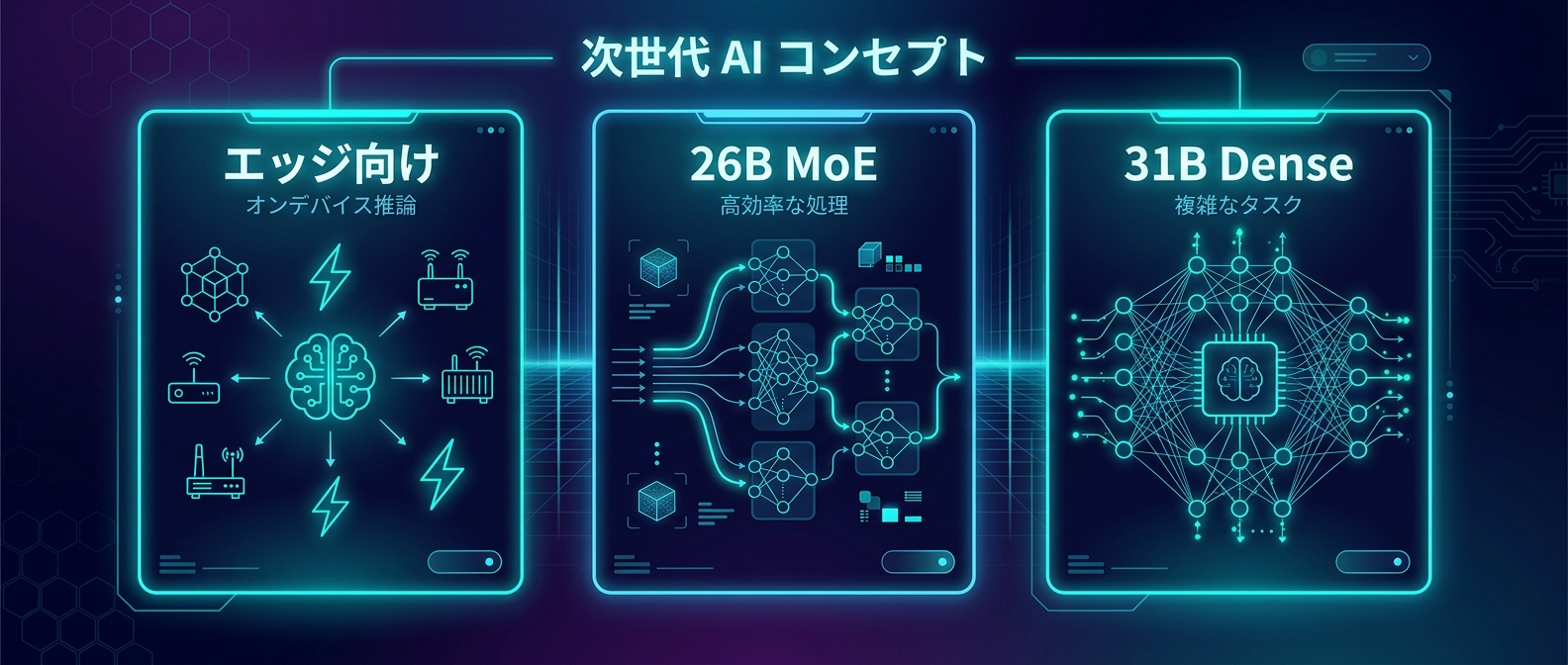
今回リリースされたのは、用途に合わせた4つのサイズだ。
有効パラメータ数2B(E2B)と有効パラメータ数4B(E4B)。
26BのMoE(Mixture of Experts)モデルと31BのDense(高密度)モデルだ。
大規模モデルのパフォーマンスは、業界標準のベンチマークが示している。
31B Denseモデルは、Arena AIのテキストリーダーボードでオープンモデルの世界第3位を獲得した。
26B MoEモデルも第6位に食い込んでいる。
20倍のサイズを持つ巨大モデルたちと互角に競い合っている。
これらのモデルは、Gemini 3と同じ世界クラスの研究と技術から構築されている。
開発者にオープンツールとプロプライエタリツールの強力な組み合わせを提供する。
パラメータあたりの知能の密度が、これまでのモデルとは異なる。
エッジデバイス向けの軽量モデルも抜かりない。
E2BやE4Bは、スマートフォンのようなリソースの限られた環境での動作を前提としている。
単なるパラメータ数の削減ではない。
マルチモーダル処理能力、低遅延、そしてエコシステムとの統合を最優先に設計されている。
Google PixelチームやQualcomm、MediaTekとの協力により、これらのモデルはエッジデバイスで完全オフラインで動作する。
スマートフォンやRaspberry Pi、NVIDIA Jetson Orin Nanoなどで、ほぼゼロ遅延の処理を実現する。
Android開発者は、AICore Developer Previewでエージェントフローのプロトタイプ作成が可能だ。
すべてのデバイスで、高度な推論が実行できる。
そして同時に、AI業界全体で視覚とコードの統合が急加速している。
Zhipu AIが発表したGLM-5V-Turboというモデルの動向も見逃せない。
これはネイティブマルチモーダルコーディングに特化した、最先端のビジョン言語モデルだ。
画像、動画、デザインカンプ、複雑なドキュメントレイアウトを直接読み込み、コードを出力する。
GLM-5V-Turboは200Kのコンテキストウィンドウを持つ。
膨大な技術ドキュメントや、長時間の画面録画を丸ごと処理できる。
これまでのAIは、画像を見る能力を上げるとコードを書く能力が落ちるというシーソー効果に悩まされてきた。
このモデルは30以上のタスクでJoint RL(強化学習)を行うことで、この課題を解決した。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
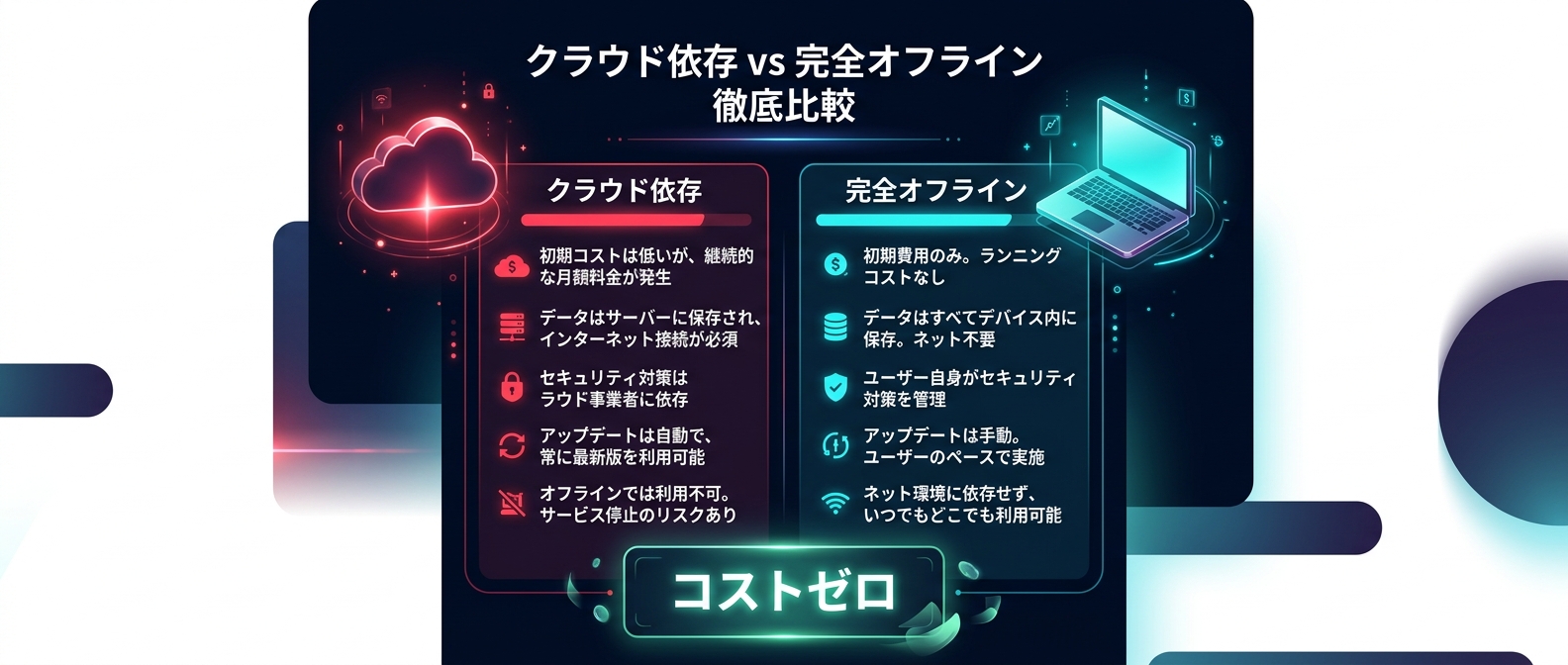
クラウド依存からの脱却とローカルエージェントの夜明け
開発者として、このニュースの影響は計り知れない。
最大のポイントは、完全オフラインで強力なAIエージェントが動くことだ。
巨大テック企業のクラウドAPIから解放される。
これまで、優秀なAIを使おうと思えば、高価なAPIを叩くしかなかった。
コードの機密性への懸念や、突然のAPI利用制限。
Gemma 4の登場で、これらの制約がなくなる。
Apache 2.0ライセンスで公開されており、商用利用も含めて完全に自由なデプロイが可能だ。
このオープンソースライセンスは、開発者に完全な柔軟性とデジタル主権を提供する。
データ、インフラストラクチャ、モデルに対する完全な制御が保証される。
エンタープライズや主権組織にとっても、最高水準のセキュリティと信頼性を満たす透明な基盤となる。
オンプレミスでもクラウドでも、安全にデプロイできる。
MoE(Mixture of Experts)アーキテクチャの採用が決定打だ。
モデル全体のサイズは260億パラメータだが、推論時に実際に動くのはわずか38億パラメータだ。
入力されたタスクに応じて、必要なネットワークだけが立ち上がる。
無駄な計算リソースを一切消費しない。
結果として、量子化されたモデルを使えば、コンシューマー向けGPUでも動く。
非量子化のbfloat16ウェイトでも、80GBのNVIDIA H100 GPU1台に収まる。
ローカルのハードウェアで、最先端の推論能力が手に入る。
しんたろー:
API代を気にせず無限に推論回せるのは本当にデカい。
ローカルでテストコードのバリエーションを大量に出させる使い方が気になる。
クラウドの障害で開発が止まるストレスからも解放されるな。
ただ、ローカルの電気代が跳ね上がりそうで少し怖い。
さらに、GLM-5V-Turboのような視覚統合モデルの存在が、ローカルエージェントの可能性を広げる。
従来のAIは、テキストの入出力しかできなかった。
このモデルはネイティブマルチモーダルフュージョンを採用している。
最初から視覚とコードを統合して学習しているため、情報の欠落がない。
このモデルは、OpenClawのようなGUIエージェント向けフレームワークとの統合が明記されている。
画面を見て、マウスを動かし、コードを書くAIが手元で動く。
テキストエディタの枠を超え、OS全体を操作するエージェントが誕生する。
僕が普段使っているClaude Codeも、CLIベースで強力な自動化を実現している。
ここにGLM-5V-Turboのような視覚認識能力が組み合わさる。
ターミナル上のテキストだけでなく、ブラウザのプレビュー画面まで含めた自動開発が見えてくる。
これが視覚的に接地されたコーディングワークフローだ。
例えば、バグのスクリーンショットをAIに投げる。
AIはエラー画面のレイアウトを認識し、該当するソースコードを特定する。
修正コードを書き、ローカル環境でビルドする。
これらの一連の作業が、クラウドを介さずに実現する。
AIの進化は、コードを生成する段階から開発環境ごと操作する段階へシフトした。
自律的に動く同僚として、ワークフロー全体を再設計するタイミングだ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
エコシステムの成熟が実装のハードルを下げる
ローカルLLMの環境構築は面倒だと考える開発者もいる。
CUDAのバージョン合わせや、依存関係の地獄。
しかし、エコシステムはすでに完成しつつある。
Hugging FaceのTransformersライブラリを使えば、数行のコードでモデルを呼び出せる。
前世代のモデルで確立された実装パイプラインは、Gemma 4でもそのまま使える。
新しいモデルが出たからといって、ゼロから学び直す必要はない。
具体的に、ローカルエージェントを動かすために準備する手順は以下の通りだ。
* Hugging Faceのトークンを取得し、セキュアに環境変数にセットする。
* ハードウェアを自動検知し、CPUかGPUかを判別するスクリプトを書く。
* bfloat16などの適切な精度でモデルをロードし、メモリ効率を最大化する。
* チャットテンプレートを活用し、エージェントに適切なシステムプロンプトを渡す仕組みを作る。
* JSON形式の構造化レスポンスや、プロンプトチェーンを実装する。
* Claude CodeのようなAIコーディングツールを日常の開発フローに組み込む。
新しいモデルが出るたびに環境構築で消耗するのは避けたい。
Hugging Face周りの基本的なロード処理とプロンプト管理のスクリプトは、自分用にテンプレ化しておくと楽そう。
ローカルモデルの検証用リポジトリを一つ作っておくか。
鍵となるのは、チャットテンプレートの扱いに慣れることだ。
自律型エージェントを作る場合、AIに思考プロセスとツール実行を明確に分けさせる必要がある。
ただテキストを出力させるのではない。
JSON形式で構造化されたデータを出力させ、それを別のスクリプトでパースして実行する。
このパイプラインをローカルで構築できれば、開発効率は大きく向上する。
すでにこのアプローチで成功を収めている事例もある。
INSAITはブルガリア語初の言語モデルであるBgGPTを作成した。
Yale大学はCell2Sentence-Scaleを用いて、がん治療の新しい経路を発見した。
ファインチューニングを通じて、特定のタスクで最先端のパフォーマンスを達成している。
APIのレイテンシを気にせず、機密データを外部に出さずに推論能力を使い倒せる。
Gemma 4の高度な論理推論能力と、視覚・コード統合モデルの組み合わせ。
これは個人開発者に無限の労働力をもたらす。
単純なコードの記述やUIの微調整から解放される。
アーキテクチャの設計やプロダクトの方向性に集中できる。
完全オフラインの自律型AIは、今日手元のPCで動かせる。
FAQ
Q1: Gemma 4の26B MoEモデルは一般的な開発者のローカルPCで動かせますか?
はい、一般的な開発環境でも十分に動かせる可能性が高いです。
Gemma 4の26B MoE(Mixture of Experts)モデルは、全体のパラメータ数は260億と大規模ですが、推論時に実際にアクティブになるのはわずか38億(3.8B)パラメータに抑えられています。
これにより、メモリ消費と計算負荷が削減されます。
量子化されたバージョンを利用することで、コンシューマー向けGPUを搭載したローカルPCでも、IDEのコーディングアシスタントやローカルエージェントとしてネイティブに実行可能です。
クラウドに依存しないセキュアな開発環境の構築に最適です。
Q2: GLM-5V-Turboの「Joint RL」とは開発者にとってどのようなメリットがありますか?
従来のビジョン言語モデル(VLM)の開発においては、画像の認識精度を向上させるとプログラミングなどの論理的推論能力が低下するというシーソー効果が大きな課題でした。
Zhipu AIのGLM-5V-Turboは30以上のタスクでJoint RL(強化学習)を行うことでこのトレードオフを克服しています。
これにより開発者は、複雑なUIのスクリーンショットやデザインカンプを読み込ませて、正確なフロントエンドのコンポーネントコードを出力させるといったタスクを、1つのモデルで安定して実行できるようになります。
Q3: Gemma 4と過去のモデルでは実装方法に大きな違いはありますか?
基本的な実装パイプラインは大きく変わりません。
Hugging Face Transformersを用いたモデルのロード手順、チャットテンプレートの適用、bfloat16での推論といった手法は、Gemma 4でもそのまま応用可能です。
ただし、Gemma 4では新たに26BのMoEアーキテクチャが導入されています。
そのため、モデルをロードする際のデバイスマッピングやメモリ管理において、MoE特有の最適化オプションを適切に設定することで、より効率的な推論が可能になります。
画像からコード生成する精度が上がるのは本当に助かる。
AIにスクショ投げて「ここ直して」で済むなら最高だ。
Claude Codeと連携させてUIのバグ修正を自動化するワークフローを試してみたい。
ただ、プロンプトの調整には少し時間がかかりそうだな。
クラウドからローカルへ。開発の主導権を取り戻す。
Gemma 4と視覚統合モデルの登場で、強力なAIエージェントがローカルで動く。
API課金とレイテンシから解放され、開発スピードはさらに加速する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
