
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
冒頭フック
7,000億パラメータの巨大な脳。
日本固有の知識を問うテストでGPT-4oを上回るスコア。
ついに実用レベルの国産オープンモデルが登場した。
驚くべきは、これがApache 2.0ライセンスで公開された事実だ。
クラウドAPIの利用料と情報漏洩リスクに悩む開発者にとって、これは究極の打開策になる。
エンタープライズ向けAI開発の前提が、今日から完全に変わる。
国産モデルが世界の壁を越えた日
Rakuten AI 3.0が公開された。
パラメータ数は約7,000億だ。
これは従来のモデルの15倍から100倍という圧倒的な規模になる。
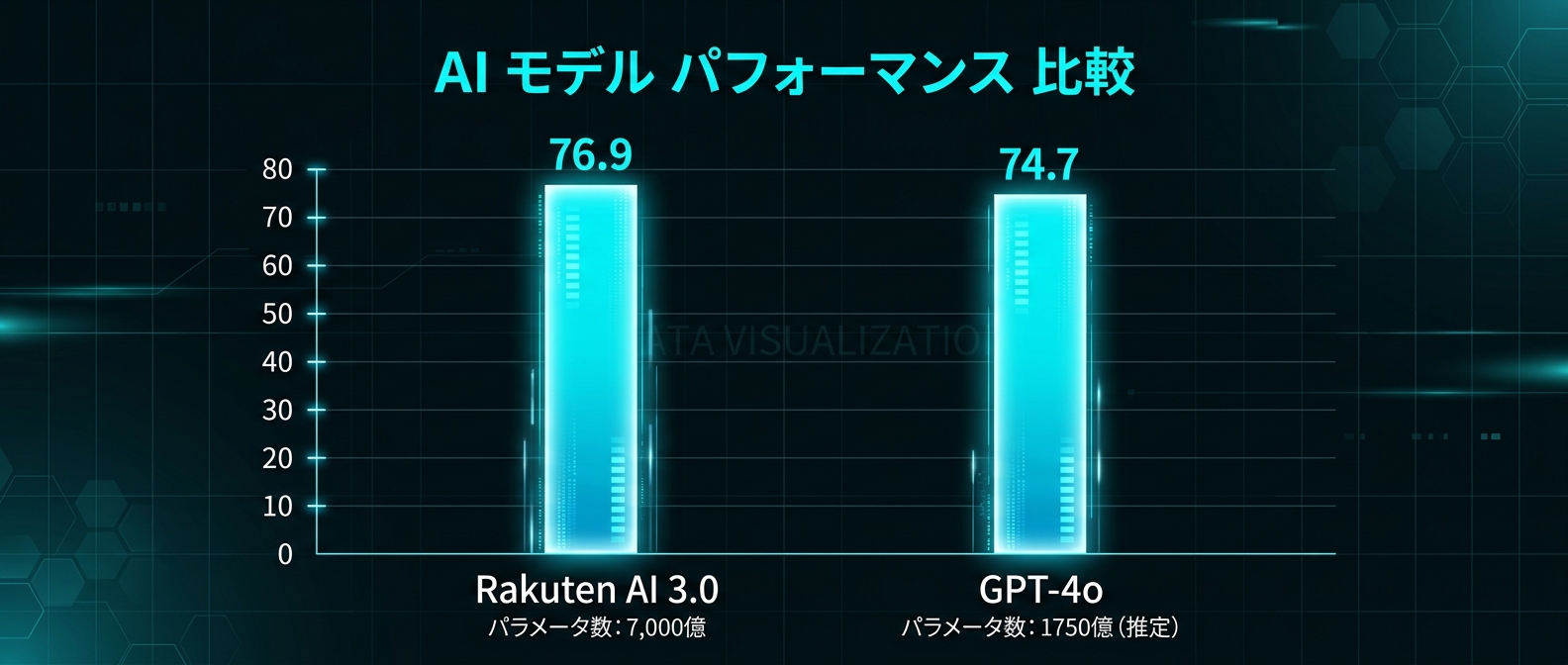
日本語の文化や歴史を問うテストで76.9点を記録した。
これはGPT-4oの74.7点を明確に上回る数字だ。
大学院レベルの推論や競技数学でも高い性能を示している。
「国産AIは遅れている」という認識は過去のものになった。
このモデルはMoEアーキテクチャを採用している。
7,000億のパラメータすべてを毎回動かすわけではない。
入力されたタスクに応じて、最も得意な専門家グループだけを呼び出す。
計算リソースを抑えながら、巨大モデルの性能を引き出す仕組みだ。
開発の背景にはGENIACプロジェクトの存在がある。
国が計算資源を提供し、独自のデータでモデルを磨き上げた。
「侍」「お盆」「根回し」といった日本特有の文脈を深く理解している。
契約書や議事録といった硬い日本語文書の処理に強い。
最大の衝撃はライセンス形態だ。
Apache 2.0ライセンスで公開されている。
商用利用も改造も再配布も自由だ。
誰でも今すぐ手元の環境にダウンロードして動かせる。
RAG技術は次のフェーズへ移行した
高性能なモデルを活かすため、RAGの技術も進化している。
文書を細切れにしてベクトル化するだけの時代は終わった。
単純な分割では、文脈が途切れて検索精度が落ちる。
現在は3つの高度なインデックス最適化手法が主流になりつつある。
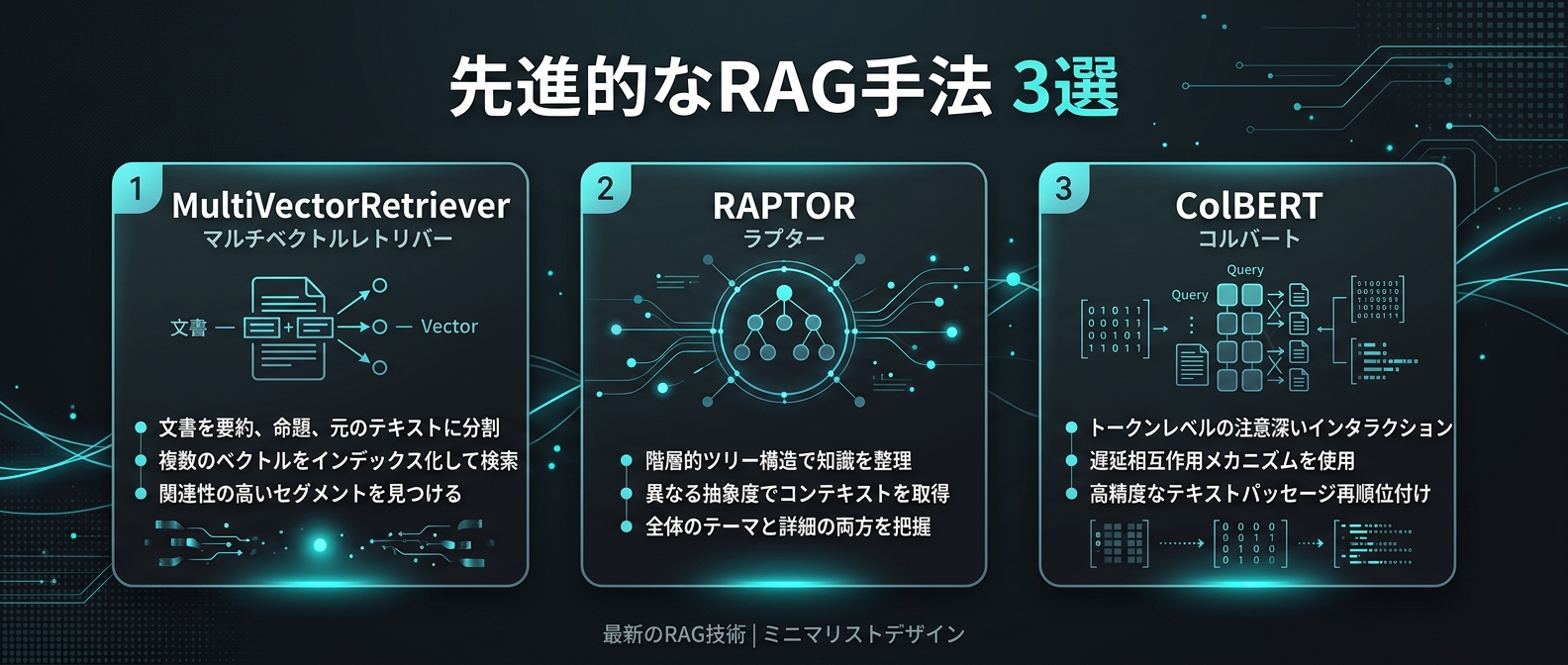
1つ目はMultiVectorRetrieverだ。
1つの文書に対して、複数のベクトルを紐付ける。
文書の要約ベクトルや、想定される質問ベクトルを生成する。
ユーザーの短い質問とマッチングさせ、回答には元の詳細な文書を使う。
情報の欠落を防ぎながらヒット率を上げる。
2つ目はRAPTORだ。
文書をクラスタリングし、再帰的に要約を繰り返す。
詳細なチャンク、トピックごとの要約、全体の要約というピラミッド構造を作る。
質問の粒度に合わせて、適切な階層から情報を検索できる。
膨大な技術白書などの全体像を把握するのに向いている。
3つ目はColBERTだ。
文章全体を1つのベクトルに圧縮する従来の手法を覆す。
すべての単語を個別にベクトル化して保持する。
検索時に、クエリの各単語と文書の全単語を総当たりで比較計算する。
これをLate Interactionと呼ぶ。
細かいバージョン番号の違いや、専門用語を正確に拾い上げる。
クラウドLLMに潜む致命的なプライバシーリスク
モデルと検索技術が進化する一方で、クラウドAPIのリスクが顕在化している。
機密情報をそのままクラウドLLMに貼り付ける行為は危険だ。
一般向けのFreeプランやProプランでは、入力データが学習に使われる。
2025年10月以降、消費者向け全プランでこの設定がデフォルトになった。
データ保持期間は最大5年に延長されている。
オプトアウトの手続きを忘れた瞬間、社内データが外部に流出する。
法的な開示リスクも存在する。
米国のCLOUD Actに基づき、政府機関へのデータ開示義務が発生する。
連邦裁判所では「AIには守秘義務がない」という判決も出ている。
中国系モデルの場合はさらに深刻だ。
中国国家情報法により、国家からの要請があればデータを提供する義務を負う。
サインイン状態での会話はすべて記録されている。
個人アカウントでデータを削除しても、内部ログは残る。
設計書、ソースコード、顧客情報、インシデントログ。
これらを外部サーバーに送信することは、致命的なセキュリティインシデントに直結する。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
エンタープライズAIの主戦場はローカルへ
なぜこの3つのニュースが繋がるのか。
それは、エンタープライズAI開発の最適解が明確になったからだ。
クラウドAPIの性能に依存するフェーズは終わった。
これからは、高性能なオープンモデルを自社環境で動かす時代になる。
開発者はこれまでジレンマを抱えていた。
セキュリティを重視すれば、性能の低いローカルモデルを使うしかない。
性能を求めれば、機密情報をクラウドに送信するリスクを負う。
このトレードオフを、Rakuten AI 3.0が破壊した。
MoEアーキテクチャのおかげで、現実的なハードウェアで巨大モデルが動く。
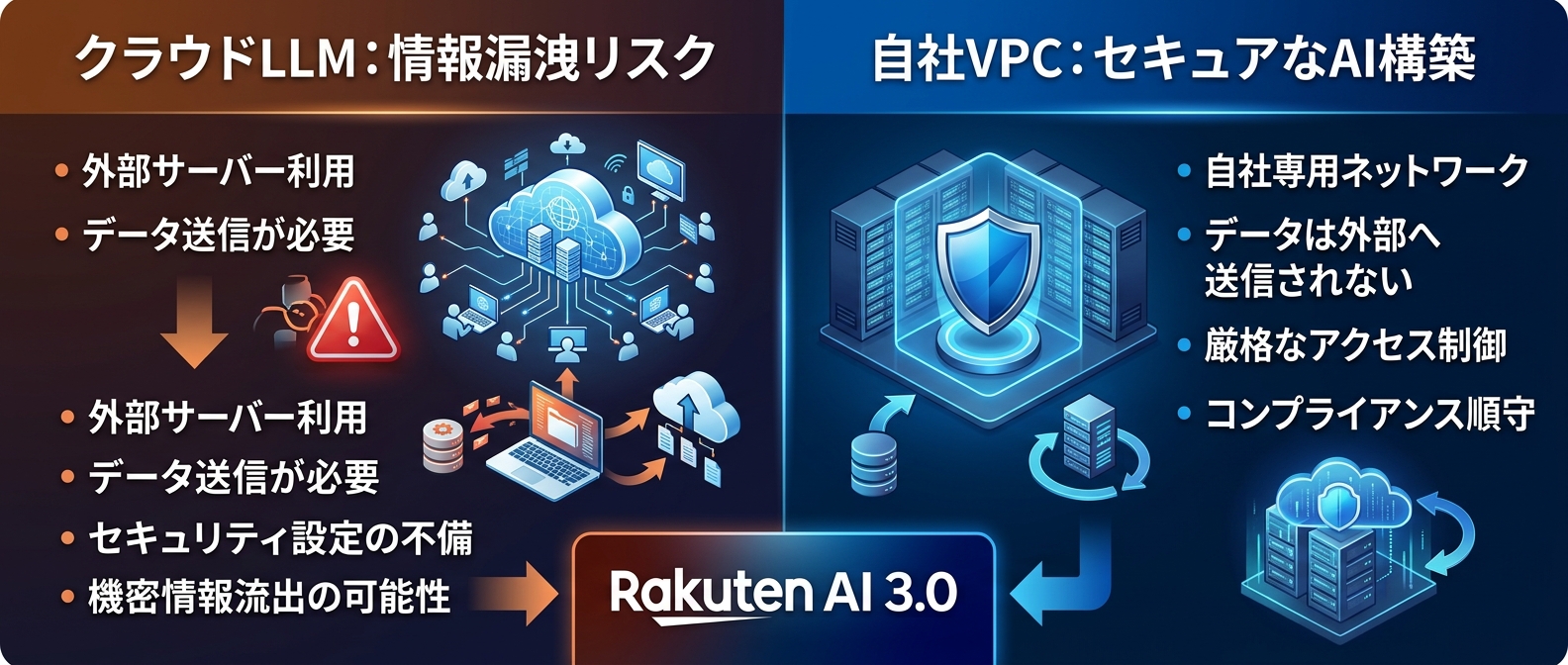
自社のVPC内やオンプレミス環境に、GPT-4oクラスの日本語AIを構築できる。
外部へのデータ送信は一切発生しない。
情報漏洩リスクは物理的にゼロになる。
これがエンタープライズ領域における最大の価値だ。
さらに、ここに高度なRAGを組み合わせる。
社内の膨大な規定集やマニュアルをColBERTでインデックス化する。
クラウドAPIを使わずに、専門用語に強い社内専用の検索システムが完成する。
APIの従量課金を気にする必要もない。
初期投資だけで、ランニングコストを劇的に抑えられる。
しんたろー:
クラウドの規約変更をいちいち追いかけるのはもう限界だ。
結局、自前のVPCにオープンモデルを立てるのが一番確実な防衛策になる。
開発環境のセキュリティを再定義する
AIを活用したソフトウェア開発の現場でも、この変化は無視できない。
僕は毎日Claude Codeを使って1人SaaS開発をしている。
ターミナルから直接AIに指示を出し、コードを生成させる。
開発スピードは圧倒的に上がった。
しかし、開発中のソースコードは最高の機密情報だ。
未公開のコアロジックを外部のAPIに送信し続けることには、常にリスクが伴う。
法人契約で学習利用をオプトアウトしていても、ネットワークの向こう側にデータが渡る事実は変わらない。
セキュリティ要件の厳しいプロジェクトでは、この構成は許可されない。
もし手元のマシンでRakuten AI 3.0のような高性能モデルが動けば、この問題は解決する。
コーディングエージェントのバックエンドを、完全にローカルモデルに切り替える。
機密性を保ったまま、AIによる高度な開発支援を受けられる。
次世代の開発環境は、クラウド依存からローカル回帰へと向かっている。
毎日Claude Codeにコードを食わせてる身からすると、クラウド送信のリスクは無視できない事実だ。
ローカルでこのレベルの日本語モデルが動くなら、機密性の高いバッチ処理のコード生成も全部手元で完結できる。
自社専用AIを構築するための実践ステップ
開発者は今後、モデルの配置戦略を設計するスキルが求められる。
用途とセキュリティ要件に応じて、クラウドとローカルを使い分ける。
まずはデータの分類だ。
公開情報や一般的な技術の質問は、今まで通りクラウドAPIを使う。
顧客データや未公開のソースコードが絡む処理は、自社環境のオープンモデルに切り替える。
ハイブリッドな構成が今後のスタンダードになる。
自社環境で動かすためのインフラ構築も重要だ。
Rakuten AI 3.0をフルサイズで動かすには、複数のハイエンドGPUが必要になる。
しかし、量子化技術を使えば要求スペックは大きく下がる。
GGUFやAWQといったフォーマットへの変換手法を習得する。
限られたリソースで巨大モデルを動かす技術が、開発者の強力な武器になる。
次に、RAGのインデックス設計を見直す。
単純なベクトル検索から脱却する。
実装のハードルが低いMultiVectorRetrieverから導入する。
これだけで情報欠落を防ぎ、ヒット率は大きく上がる。
専門用語の検索漏れが目立つ場合はColBERTを検討する。
文書全体の文脈理解が必要な場合はRAPTORを試す。
扱うデータの性質に合わせて、最適な手法を選択する。
セキュリティの観点では、利用中のクラウドLLMのプランを直ちに再確認する。
FreeプランやProプランのまま業務データを入力するのは危険だ。
組織外での学習利用が禁止されているEnterprise版への移行を急ぐ。
「どこにデータが行くか」を完全に制御することが、AI開発者の必須スキルだ。
RAGの精度が出ないって相談をよく受けるけど、大抵はチャンク分割が雑なだけだ。
ColBERTの総当たり計算を自社サーバーで回せば、細かい仕様書のバージョン違いも一発で抜けるはず。
よくある質問
Q1: Rakuten AI 3.0を自社で動かすにはどれくらいのスペックが必要ですか?
A1: 7,000億パラメータのMoEモデルであるため、フルサイズで動かすには複数のハイエンドGPUを搭載したサーバー環境が必要だ。ただし、MoEアーキテクチャにより推論時のアクティブパラメータ数は抑えられる。GGUFやAWQなどの量子化技術を活用すれば、要求スペックを現実的なラインまで引き下げることが可能だ。
Q2: RAGの精度を上げるために、まずはどの手法から試すべきですか?
A2: まずは実装が比較的容易なMultiVectorRetrieverから試すことを勧める。文書を要約して検索用ベクトルとし、回答生成には元の詳細な文書を使う。これで情報の欠落を防ぎつつヒット率を上げられる。専門用語の検索漏れが目立つ場合はColBERTを、文書全体の文脈理解が必要な場合はRAPTORを検討する。
Q3: 業務で一般向けのAIチャットを使うのは危険ですか?
A3: 機密情報を入力する場合、一般向けのFreeプランやProプランは学習に利用されるリスクや法的開示リスクがあるため危険だ。業務利用の場合は、学習利用がオプトアウトされている法人向けプランを契約するか、オープンモデルを自社環境のVPC内でホスティングする構成を選択する。
まとめ
高性能なオープンモデルと高度なRAGの組み合わせが、エンタープライズAIの最適解になる。
データ漏洩リスクを完全に排除しつつ、クラウドAPIを超える専門システムが構築できる。
AI開発の主戦場は、確実に自社環境へと移行している。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
