
VRAM 8GBは「ローカルLLMには貧乏くじ」と言われる。確かに全レイヤーをGPUに載せることはできない。でも、正しい推論エンジンを選び、ビルドオプションを最適化し、量子化モデルを適切に選定すれば、32Bクラスのモデルでも実用的な速度で動かせる。このまとめは、限られたVRAMを限界まで引き出すための具体的な手順と設定のコツを10個にまとめたものだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
環境構築の基礎:推論エンジン選定から始める
Tips 1:VRAM 8GB環境ではllama.cppが最適解
OllamaとvLLMはVRAM 8GBの環境では制約が大きい。
Ollamaはセットアップが手軽で人気だが、GPUレイヤー数(ngl)の細かい制御ができない。8GBのVRAMで32Bモデルを動かす場合、1レイヤー単位で調整したい場面が必ずある。Ollamaは自動で保守的な値を選ぶため、GPUが余力を残したまま動く結果になりやすい。
vLLMはサーバー用途では優秀だが、VRAMをフルに確保する前提で設計されている。8GBの環境では32Bモデルの場合、起動すらできないことがある。
llama.cppを選ぶ理由はシンプルだ。
- nglを1刻みで自由に指定できる
- GGUFフォーマットの量子化モデルが豊富に出回っている
- CUDAビルドで推論速度を引き出せる
- コンパイル時の最適化オプションが豊富
UIや抽象化は薄いが、その分だけ制御が効く。VRAM 8GBで大型モデルを動かしたいなら、まずllama.cppを選ぶのが得策だ。
Tips 2:量子化モデルのVRAM消費量を事前計算する
モデルをダウンロードする前に、VRAMに収まるかどうかを計算しておくのが重要だ。
計算式はシンプルで、「パラメータ数(B) × 量子化ビット数 ÷ 8 ÷ 1024³」でモデルサイズのGBが出る。そこにKVキャッシュ用のメモリ約0.5GBを加算して、8GBに収まるかどうかを確認する。
たとえば32BモデルのVRAM消費量を見積もると、Q4_K_Mで約17.7GB、IQ4_XSで約16.9GBとなる。これは8GBに収まらない。GPUとCPUにレイヤーを分割して処理させるハイブリッド推論で対応することになる。
量子化レベルの目安:
- Q8_0:約32.7GBとなり全乗せ不可
- Q4_K_M:約17.7GBとなり全乗せ不可
- IQ4_XS:約16.9GB。品質とサイズのバランスが良く、最初の選択肢として有力
事前計算なしでダウンロードを繰り返すのは時間の無駄になる。計算してから選ぶのが確実だ。
Tips 3:llama.cppビルド時にCUDA Graphsを有効化する
llama.cppをCUDAビルドする際、「-DGGML_CUDA_GRAPHS=ON」フラグを追加するだけでスループットが8〜12%向上する。
CMakeでのビルドコマンドに含めるフラグの例は以下だ。
- -DGGML_CUDA=ON
- -DGGML_CUDA_FA=ON
- -DGGML_CUDA_F16=ON
- -DGGML_BLAS=ON
- -DGGML_CUDA_GRAPHS=ON(これが重要)
CUDA Graph最適化は2025年後半から正式サポートされた機能だが、公式のビルドガイドやREADMEにはほとんど記載がない。GitHubのPRを掘らないと見つからない隠し設定的なテクニックだ。
8〜12%というのは地味に見えるが、VRAM 8GBのギリギリ環境では積み重ねが効く。ビルド時に必ず追加しておきたいオプションだ。
Tips 4:WSL2でのCUDAエラーはバージョン整合で解決する
WSL2上でllama.cppを動かす際、Windows側のNVIDIAドライバとWSL2内のCUDA Toolkitのバージョンが噛み合わないと実行時エラーになる。
ビルドは通るのに「CUDA error: no kernel image is available」が出るケースがこれだ。ドライバのバージョンとCUDA Toolkitのバージョンの対応関係を確認せずに進めると、このエラーで詰まる。
安定する組み合わせ:
| Windows NVIDIAドライバ | WSL2内 CUDA Toolkit |
|---|---|
| 560.x系 | 12.6 |
バージョンが合わない場合は、Windows側のドライバを更新するか、WSL2内のCUDA Toolkitを再インストールして揃える。環境構築の最初に確認しておくと後で詰まらずに済む。
Qwen系モデルの落とし穴:thinkingモードを制御する
Tips 5:Qwen3.5系のthinkingモードはデフォルトでON
Qwen3.5系モデルは「thinkingモード」がデフォルトで有効になっている。 これを知らずに使うと、空回答が返ってくる謎の現象に遭遇する。
thinkingモードとは、最終回答の前に推論プロセスを出力する機能だ。問題は、設定した最大トークン数を「考える」プロセスだけで使い切ってしまい、実際の回答が出力される前に処理が終了してしまうことだ。
実際に24問を投げたベンチマークでは、thinkingモードをONにしたまま評価すると9問が空回答になったという報告がある。モデルの実力を大幅に低く見誤る原因になる。
対処法:
- APIリクエスト時に「think: false」を指定してthinkingモードを無効化する
ベンチマーク評価や実運用では、意図した挙動をさせるためにthinkingモードの制御は必須だ。

Tips 6:OllamaでthinkingモードをOFFにする正しい方法
よくある間違いがある。 OllamaのOpenAI互換エンドポイント(/v1/chat/completions)で「think: false」を渡しても、このパラメータは無視される。空回答が返ってくるだけで、thinkingモードは無効化されない。
正しい方法はOllamaネイティブのエンドポイントを使うことだ。
- 使うエンドポイント:/api/chat(Ollamaネイティブ)
- 渡し方:リクエストのトップレベルに「think: false」を指定
OpenAI互換エンドポイントに慣れていると、同じパラメータが効かないことに気づかずハマりやすい。Qwen3.5系を導入する前に確認しておく価値がある設定だ。
Apple Siliconユーザー向け:Macでローカルモデルを動かす
Tips 7:FameuseでApple Foundation ModelsをOpenAI API化する
Apple Foundation ModelsはHTTP APIを標準で持っていない。 そのため、Open WebUIなどのインターフェースからそのまま使うことができない。
CLIツール「Fameuse」を使えば、Apple Foundation ModelsをOpenAI API互換形式で呼び出せるようになる。HomebrewでインストールしてコマンドひとつでAPIサーバーが起動する仕組みだ。
セットアップの流れ:
- Homebrewでfameuseをインストール
- 「fameuse serve」コマンドで起動
- デフォルトでhttp://localhost:8084/v1 にアクセス可能になる
指定できる主なオプションは、ホスト・ポート・認証用のAPIキーだ。Open WebUIにURLを設定すれば、ストリーミングでチャットが動く。
ただし、Apple Foundation Modelsは算数が得意なタスクではないと公式ドキュメントに明記されている。文章要約や整理が得意なモデルとして使い分けるのが現実的だ。
Tips 8:Apple Intelligenceを有効化するための言語設定
Apple Foundation Modelsを使うには、Apple Intelligenceの有効化が必須だ。 そしてここでつまずく人が多い。
有効化の条件は「端末の言語とSiriの言語を同一の対応言語に揃えること」だ。たとえばデバイスは英語(United States)、Siriは日本語、という設定では有効化できない。
対応言語の一部:
- 日本語
- 英語(米国・英国・オーストラリア等)
- 中国語(簡体字・繁体字)
- フランス語・ドイツ語・韓国語等
日本語は対応言語に含まれているので、デバイスとSiriの両方を日本語に揃えれば有効化できる。設定 → Apple Intelligence & Siri → Apple Intelligenceから有効化する。初回はモデルのダウンロードに数分かかるので余裕を持って進める必要がある。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
UIを整える:快適な操作環境を構築する
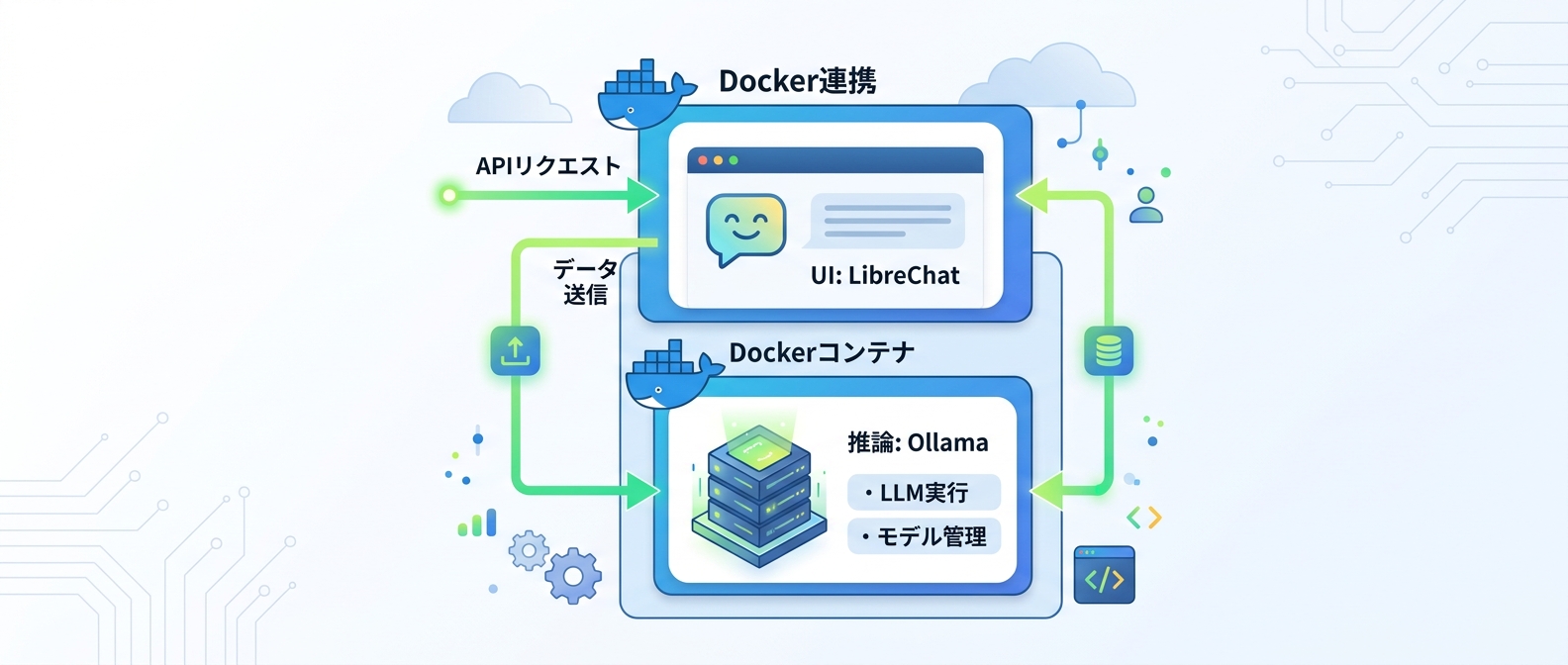
Tips 9:LibreChatでChatGPT風のUIを構築する
ローカルLLMをChatGPT風のUIで使いたいなら、LibreChatが有力な選択肢だ。
LibreChatはローカルでLLMを動作させるツールと組み合わせることで、快適な操作環境を構築できる。
構築の基本手順:
- LibreChatのリポジトリをクローン(`git clone https://github.com/danny-avila/LibreChat`)
- ディレクトリに移動(`cd LibreChat`)
- `.env.example`をコピーして`.env`を作成(`cp .env.example .env`)
これらをベースにローカルAIを動作させる環境を整えることが可能だ。
Tips 10:Appleドキュメントはローカルキャッシュ経由で参照させる
LLMエージェントにApple関連のコードを書かせる際、直接Webスクレイピングさせるのは避けたほうがいい。
理由はシンプルで、レートリミットに引っかかったり、パース失敗でエラーになるリスクがあるからだ。エージェントが途中で止まる原因になる。
「cupertino」などのSQLite DBキャッシュを使ってローカル検索させるのが確実だ。
- ドキュメントをSQLiteにキャッシュしておく
- エージェントはローカルDBに対してクエリを投げる
- ネットワーク依存がなくなり、パース失敗も起きない
Claude Codeでエージェント開発をしている場合、このパターンは特に効果的だ。外部依存を減らすことでエージェントの安定性が大幅に上がる。
しんたろー:
Claude Codeで1人SaaSを開発している身からすると、Tips 10のローカルキャッシュのアプローチは本当に理にかなっていると断言できる。
エージェントが外部リソースに依存するほど、予期しない場所で止まるリスクが増える。ローカルに完結させる設計は、Claude Codeでコードを書かせる際にも同じ考え方が使えるはずだ。
推論エンジン・ツール比較表
| ツール | セットアップ難易度 | ngl制御 | VRAM 8GBでの32B動作 | おすすめ度 |
|---|---|---|---|---|
| llama.cpp | 中(ビルド必要) | 1刻みで自由 | 動く(ハイブリッド) | ★★★★★ |
| Ollama | 低(コマンド一発) | 自動のみ | 制限あり | ★★★☆☆ |
| vLLM | 高 | 詳細設定可 | 8GBでは起動困難 | ★★☆☆☆ |
| Apple Foundation Models + Fameuse | 低(Mac限定) | 不要 | Mac専用 | ★★★★☆ |
| LibreChat | 中 | 連携ツール依存 | UIとして優秀 | ★★★★☆ |
普段Claude Codeでコードを書いている僕からすると、ローカルLLMはオフライン環境や費用を抑えたい場面での選択肢として気になる存在だ。
llama.cppのCUDA Graphs最適化やthinkingモードの制御は、知っているか知らないかで体験が大きく変わる類のテクニックだと断言できる。特にVRAM 8GBという制約の中でここまで引き出せるなら、導入する価値は十分にある。
よくある質問
Q1:VRAM 8GBのPCでもローカルLLMは動かせる?
動かせる。7BクラスのモデルであればOllamaなどで手軽に動作する。さらに32Bクラスの大型モデルでも、llama.cppを使って適切な量子化モデル(IQ4_XSなど)を選び、GPUとCPUにレイヤーを分割するハイブリッド推論で動作可能だ。ただしメモリ帯域幅が推論速度に直結するため、ビルド時のCUDA Graph最適化やVRAM消費量の事前計算が重要になる。ギリギリのスペックでも工夫次第で実用的な環境が作れる。
Q2:OllamaとLlama.cppはどちらを選ぶべき?
目的とスペックによって変わる。VRAMに余裕がある場合や7Bクラスの小さいモデルを手軽に動かしたいなら、コマンド一つで環境が整うOllamaが適している。一方、VRAM 8GBなどの制限された環境で大型モデルをギリギリまで最適化して動かしたいなら、GPUレイヤー割り当て(ngl)を細かく制御でき、コンパイル時の最適化オプションが豊富なllama.cppを選ぶべきだ。セットアップの手間を取るか、制御の自由度を取るかのトレードオフになる。
Q3:Qwen3.5モデルで回答が空になってしまうのはなぜ?
Qwen3.5系のモデルは推論プロセスを出力する「thinkingモード」がデフォルトでONになっている。設定された最大出力トークン数を「考える」プロセスだけで使い切ってしまい、最終的な回答が出力される前に処理が終了して空回答になるのが原因だ。防ぐにはAPIリクエスト時に「think: false」を指定する必要がある。OllamaのOpenAI互換エンドポイントではこのパラメータが無視されるため、Ollamaネイティブの「/api/chat」エンドポイントを使う点に注意が必要だ。
Q4:MacでAppleのローカルLLMを使うにはどうすればいい?
macOS 26.0以降などの対応端末であれば、Apple Foundation Modelsを利用できる。まず端末の言語とSiriの言語を同じ対応言語(日本語など)に揃えてApple Intelligenceを有効化する。その後「Fameuse」というCLIツールをHomebrewでインストールして起動すると、OpenAI API互換の形式でモデルを呼び出せるようになる。Open WebUIなどのツールにURLを設定すればブラウザからチャットが可能だ。文章要約や整理が得意なモデルなので、その用途で使うのが実用的だ。
Q5:ローカルLLMにChatGPTのような使いやすい画面をつけるには?
「LibreChat」といったオープンソースのUIツールを導入するのが一般的だ。LibreChatはChatGPTに非常に近い洗練されたUIを提供している。リポジトリをクローンし、`.env`ファイルを作成して設定を行うことで構築できる。ローカルでLLMを動作させるツールと組み合わせることで、ブラウザから快適にローカルLLMを利用できるようになる。
まとめ
VRAM 8GBでローカルLLMを動かすための10のテクニックをまとめた。
特に重要な3つを挙げるとすれば:
- 推論エンジンはllama.cpp一択(nglの細かい制御が必要な場合)
- ビルド時に-DGGML_CUDA_GRAPHS=ONを追加(8〜12%のスループット向上)
- Qwen3.5系はthinkingモードを明示的に制御(空回答を防ぐ)
環境構築の知識は一度身につければ長く使える。まずはLibreChatなどのUIツールとローカルLLMの組み合わせから始めて、慣れてきたらllama.cppのビルドに挑戦するのが現実的な順序だ。
ローカルLLMで得た知見をSNSでシェアしたい場合、ThreadPostを使えばスレッド形式で効率よく発信できる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ

なぜClaude Codeはプロンプト一発回答をやめたのか。開発者が対話で思考を深めるべき訳を徹底解説

Claude Codeで開発を自動化する鍵は検証ゲートの設計にある

【速報】CursorがSDKとJSONL保存を正式発表。AIエージェントの検証を自動化する開発手法
