
結論から言うと、2026年のAI開発は「いかに遅延をなくし、推論の深さをコントロールするか」が勝負だ。テキスト処理だけでなく、ネイティブな音声処理や高効率な推論モデルが次々と登場している。
今回は、1人SaaS開発者の僕が本気で選んだ最新AIモデルの活用術を10個紹介する。MistralやGeminiの最新モデルを中心に、実務で即使えるプロンプトや設定のコツをまとめた。初心者でも今日から実践できる内容ばかりだ。
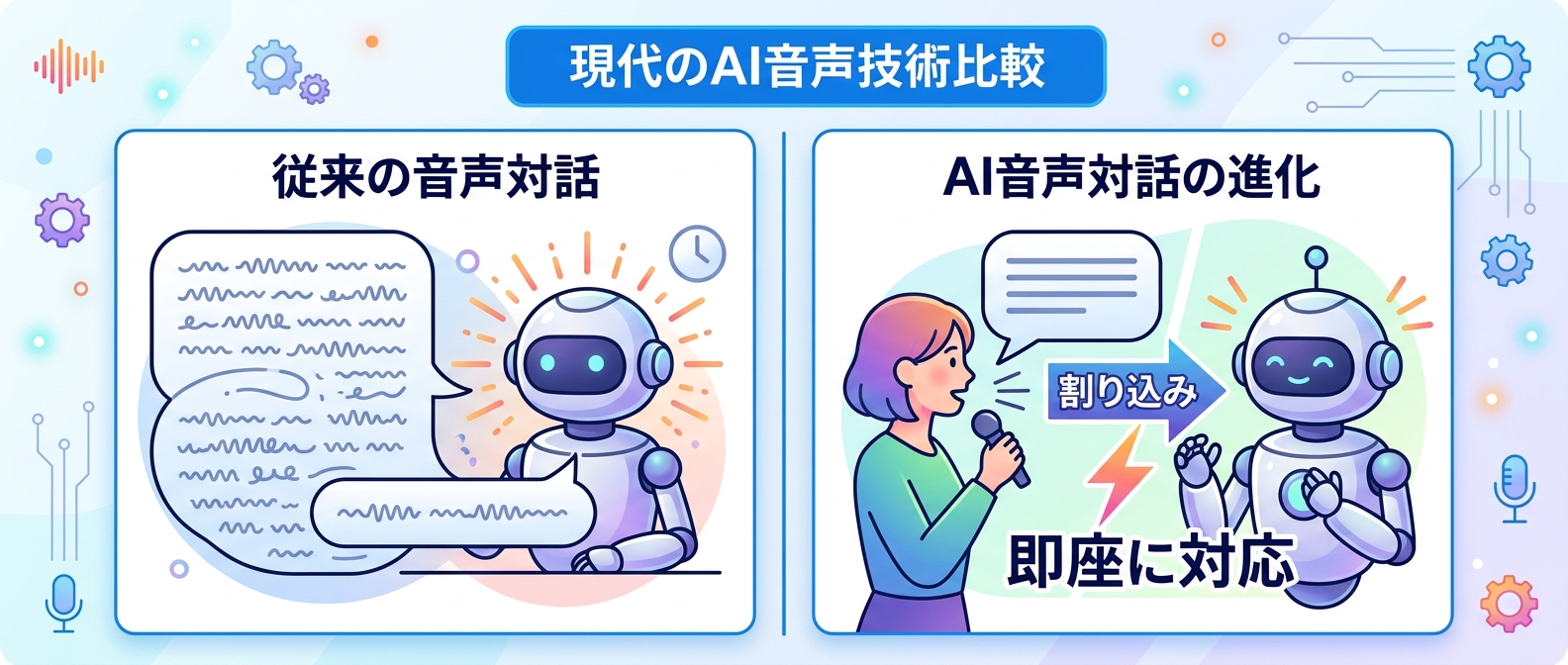
特に、音声AIの進化は目覚ましく、従来のテキストを介した処理から、音響を直接処理するネイティブモデルへの移行が進んでいる。これにより、人間と機械の対話はかつてないほど自然なものになった。
まずは今回紹介する主要モデルの特徴を整理しておこう。
| モデル名 | 得意分野 | 応答速度 | 主な特徴 |
| --- | --- | --- | --- |
| Gemini 3.1 Flash Live | リアルタイム音声対話 | 低遅延 | ネイティブ音声処理、思考レベル調整 |
| Mistral Voxtral TTS | 超低遅延の音声生成 | 70ms | 意味と質感の分離、9言語対応 |
| Mistral Small 4 | 高速テキスト・論理推論 | 従来比40%高速 | MoEアーキテクチャ、推論深さの制御 |
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
カテゴリ1:Mistral Voxtral TTSの音声生成ハック
1. 超低遅延でリアルタイム音声生成を実現する
音声AIの最大の敵は遅延だ。人間と機械の対話で不自然な間が空くと、一気に使いにくくなる。
そこで役立つのが、MistralのVoxtral TTSだ。このモデルは10秒の音声サンプルと500文字の入力をわずか70msという驚異的なレイテンシで生成できる。
たとえば、リアルタイム翻訳アプリや会話型エージェントの出力層として設定するといい。人間の会話テンポに限りなく近い、スムーズなやり取りが実現するはずだ。クローズドソースのAPIに依存せず、オープンウェイトのモデルでこの速度を出せるのは非常に優秀だ。
2. 意味と質感を分離して自然な声を保つ
長時間の音声を生成すると、途中で声のトーンが変わったり不自然になったりすることがある。これを防ぐには、ハイブリッドアーキテクチャの理解が不可欠だ。
Voxtral TTSは、音声の「意味(セマンティック)」と「質感(アコースティック)」を分離して処理する仕組みを持っている。プロンプトでこの特性を活かす設定を行えば、長文の読み上げでも一貫性が保たれる。
たとえば、オーディオブックの朗読や長時間のポッドキャスト生成で、人間らしい微細なニュアンスを持たせた自然な音声出力が可能になる。わずか3秒の参照音声で新しい声に適応できるゼロショットのクローン機能も強力だ。
3. 多言語対応アプリを低コストで構築する
グローバル向けのアプリを作る際、言語ごとの音声処理コストは大きな壁になる。しかし、最新モデルを使えばこの問題も解決できる。
Voxtral TTSは英語やフランス語、ドイツ語、スペイン語など9言語にネイティブ対応している。さらに、リアルタイムファクター9.7倍という高速処理が特徴だ。
これを活かせば、計算コストを抑えながら高並行処理が求められる多言語音声アプリを構築できる。サーバー代を節約しつつ、世界中のユーザーに快適な音声体験を提供できるのは大きなメリットだ。地域ごとの方言や抑揚の違いまで正確に再現できる点も素晴らしい。
しんたろー:
Voxtral TTSの70msというレイテンシは驚異的だ。Claude Codeで開発している音声アプリの出力層に組み込むのが良さそうだ。多言語対応も強力で、グローバル展開を見据えたSaaS開発の強力な武器になるはずだ。
カテゴリ2:Gemini 3.1 Flash Liveのリアルタイム対話術
4. 待機時間を排除して音声ファーストな体験を作る
従来の音声AIは「音声認識→テキスト化→AI思考→音声合成」という待機時間の積み重ねがネックだった。これを根本から解決するのがネイティブ音声処理だ。
Gemini 3.1 Flash Liveは、音響のニュアンスを直接読み取り、テキストを介さずに処理を行う。これにより、待機時間スタックを完全に排除できる。
たとえば、カスタマーサポートのAIにこの設定を組み込めば、顧客の言葉のトーンや感情を即座に汲み取り、自然な相槌を打つようなエージェントが開発できる。ピッチやペースの認識精度も従来モデルから大幅に向上している。
5. 割り込み機能を実装して自然な会話リズムを生む
人間同士の会話では、相手の話を途中で遮って別の話題に移ることがよくある。AIにもこの柔軟性を持たせるのが、割り込み機能だ。
Gemini 3.1 Flash Liveでは、ユーザーがAIの会話を途中で遮ることができるBarge-in機能を有効にできる。AIは即座に音声生成のバッファを停止し、新しい入力を処理し始める。
たとえば、AIが長々と説明している途中で「要点だけ教えて」と話しかけるだけで、瞬時に対応を切り替えてくれる。これで対話のストレスは激減するはずだ。
6. 双方向ストリーミングでリアルタイム性を極める
通常のAPI通信は、リクエストを送ってレスポンスを待つ一方通行の繰り返しだ。しかし、リアルタイムな音声対話にはこれでは不十分だ。
そこで、Multimodal Live APIを利用したステートフルな双方向ストリーミングインターフェースを設定しよう。WebSocketsを利用して、クライアントとモデル間で継続的なデータストリームを維持できる。
たとえば、オンライン英会話のAI講師アプリなどで、ユーザーの発音をリアルタイムで聞き取りながら即座にフィードバックを返すような高度な機能が実装可能になる。
7. 思考レベルを最適化してUXを向上させる
AIの応答速度と賢さはトレードオフの関係にある。用途に合わせてこれを動的に切り替えるのが、プロンプト設計の腕の見せ所だ。
Gemini 3.1 Flash Liveでは、思考レベルを設定できる。即時性が求められる日常会話には「Minimal」を選び、複雑なタスクには「High」を選択するといい。
たとえば、天気を聞かれたら即答モードで返し、複雑なスケジュールの調整を頼まれたら深考モードに切り替える。ComplexFuncBench Audioというベンチマークで90.8%のスコアを記録したように、音声入力だけで複雑な論理推論が可能だ。
8. ノイズ環境下でも高精度な音声認識を維持する
静かな部屋でしか使えない音声AIは、実用的とは言えない。屋外や店舗など、騒がしい環境での動作テストは必須だ。
Gemini 3.1 Flash Liveは、交通騒音や背景の話し声がある環境でも、関連する音声を正確に識別できる特性を持っている。これをモバイルアシスタントの設定に組み込もう。
たとえば、工事現場で使う業務アプリや、駅のホームで案内をするデジタルサイネージなど、過酷な環境下でも確実にユーザーの声を拾える堅牢なシステムが構築できる。Audio MultiChallengeでも高い性能を示しており、実環境での信頼性は抜群だ。
カテゴリ3:Mistral Small 4の高効率テキスト処理
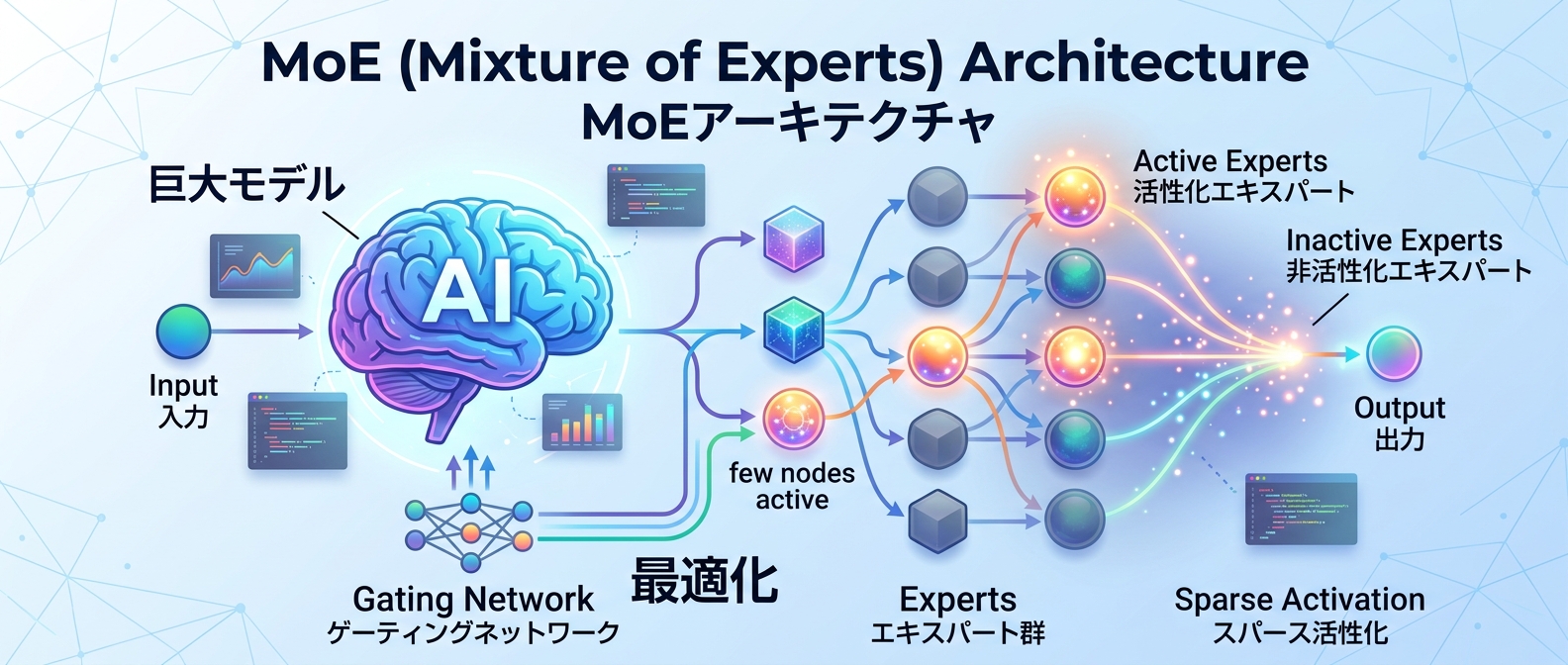
9. MoEアーキテクチャを活かしてテキスト処理を高速化する
巨大なAIモデルは賢いが、動作が重くてコストがかかる。このジレンマを解決するのが、必要な部分だけを動かす仕組みだ。
Mistral Small 4は、1190億のパラメータのうち、クエリごとに最適な約60億だけをアクティブにする仕組みを採用している。128の専門家モジュールのうち4つだけを稼働させることで、前モデル比で40%の高速化を実現した。
たとえば、大量のドキュメントを要約するタスクや、リアルタイムのチャットボットの裏側でこのモデルを指定すれば、高い精度を保ちながらサーバーの負荷を大幅に下げることができる。1秒間に処理できるクエリ数も3倍に増加している。
10. 推論の深さと速度を動的にコントロールする
すべての質問に全力で答える必要はない。簡単な質問にはサクッと答え、複雑な問題にはじっくり取り組むのが理想のAIだ。
Mistral Small 4では、ユーザー側でモデルの応答速度と推論の深さを制御できる機能を活用しよう。プロンプトで「即答モード」と「分析モード」を定義するのだ。
たとえば、挨拶や簡単なQAには素早い回答を返し、複雑な論理推論や画像処理を伴うデータ分析には徹底的な思考を促す。この動的コントロールが、実務でのパフォーマンス最大化の鍵となる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
しんたろーのイチ推しTips
毎日Claude Codeで1人SaaS開発をしている身からすると、用途に合わせてAIの「思考の深さ」を切り替えるアプローチが一番刺さった。
理由はシンプルで、開発中のエラー解決は「とにかく早くヒントが欲しい時」と「アーキテクチャ全体を深く考察してほしい時」が明確に分かれるからだ。
普段はClaude Codeにコードを任せつつ、今回紹介したGemini 3.1 Flash Liveの音声対話をアイデア出しの壁打ち相手として使うのもかなり良さそうだ。
よくある質問(FAQ)
Q1: ネイティブ音声処理とは従来の音声AIと何が違う?
従来の音声AIは「音声をテキストに変換→AIでテキスト生成→テキストを音声に変換」という複数の手順を踏むため、応答に遅延が生じていた。ネイティブ音声処理モデルは、音響のニュアンスを直接読み取り、テキストを介さずに音声を生成する。これにより遅延が劇的に減り、声のトーンや感情まで自然に処理できるのが最大の違いだ。
Q2: Gemini 3.1 Flash Liveの「思考レベル」はどう使い分ける?
タスクの複雑さと求められる応答速度に応じて使い分けるのが正解だ。テンポの良さが重要な日常会話や初期対応には、高速な「Minimal」が適している。一方で、複雑な条件分岐や正確な情報提供が必要な場合は、精度が非常に高い「High」を設定するといい。
Q3: Mistral Voxtral TTSは商用利用できる?
非営利目的であれば無償で自由に利用できるが、商用利用には制限がある。このモデルは非営利ライセンスで公開されているため、自社の商用サービスや利益を生むアプリにそのまま組み込むとライセンス違反になる。商用利用を検討する場合は、公式APIやエンタープライズ向けプランを別途確認し、適切な契約を結ぶ必要がある。
Q4: 割り込み機能はどんなアプリで役立つ?
人間同士のような自然でテンポの良い対話が求められるすべてのアプリで役立つ。たとえば、AIが長文を読み上げている途中で「そこはもういいから次へ進んで」と指示する音声アシスタントや、ユーザーの感情の変化に即座に対応するAIカウンセラーなどに最適だ。双方向のコミュニケーション品質が劇的に向上する。
Q5: Mistral Small 4の「128の専門家モジュール」とは何?
巨大なAIモデルを複数の「専門家」に分割し、効率的に処理する仕組みのことだ。全体で1190億のパラメータを持っているが、1回の質問に対して最適な4つの専門家(約60億パラメータ)だけを稼働させる。これにより、高い推論能力を維持しながら計算コストを抑え、従来より40%高速な応答を実現している。
まとめ
今回は、2026年最新のAIモデル活用術を10個紹介した。まとめると以下の通りだ。
- 音声生成の遅延をなくすならMistral Voxtral TTSが最適だ
- リアルタイムな音声対話にはGemini 3.1 Flash Liveの割り込み機能が効く
- テキスト処理の効率化にはMistral Small 4の動的コントロールを活用しよう
最新モデルの特性を理解し、用途に応じて「思考レベル」や「推論の深さ」を制御することが、実務でのパフォーマンス最大化の鍵となる。
まずは応答速度の速いモデルを試し、圧倒的なスピードを体感するところから始めよう。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
