
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
エラーが出ない恐怖。あなたのAIアプリは「たまたま」動いているだけだ
出た。AI開発の最大の罠だ。
APIを叩いてエラーが出ない。
だから「ヨシ」としていないか。
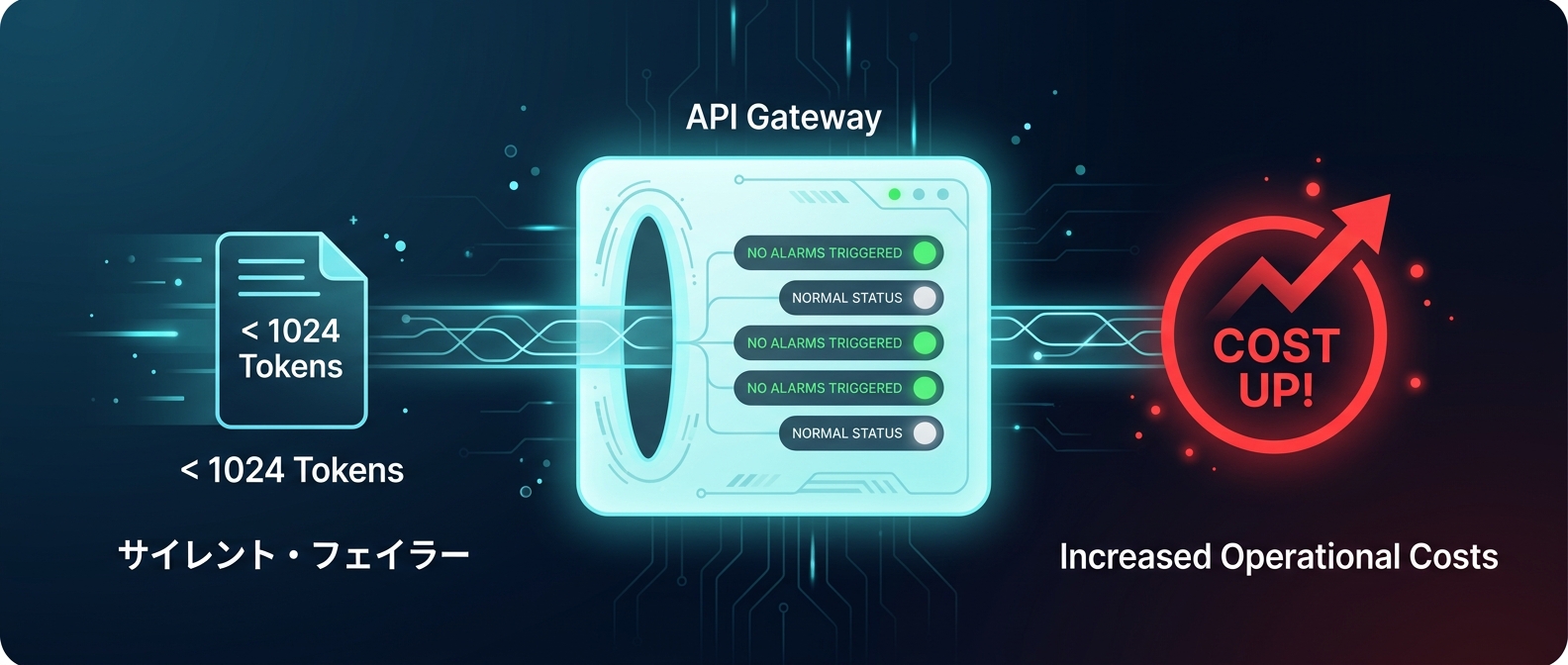
1024トークン。
この数字を知らないだけで、あなたのAIアプリは無駄なコストを垂れ流している。
LLMは不適切な入力に対してもエラーを出さない。
黙って素通りする。
コストを跳ね上げる。
幻覚を見せる。
AI開発の主戦場はLLMの性能ではない。
APIの隠れた仕様理解だ。
データを渡す前の泥臭いエンジニアリングだ。
LLMはサイレントに失敗する。API仕様と周辺設計の残酷な事実
海外のAI開発コミュニティで、本番環境におけるAI運用の生々しい失敗と対策が共有されている。
複数の情報源から見えてくる共通項がある。
それは「LLMはエラーを出さずに処理を継続してしまう」という事実だ。
これをサイレント・フェイラーと呼ぶ。
まず、APIのキャッシュ仕様の罠だ。
Claude APIでプロンプトキャッシュを効かせる。
そのためには最小のトークン数が必要になる。
その数は1024トークンだ。
これ未満の短いプロンプトに「cache_control」を付与したとする。
どうなるか。
エラーは一切出ない。
警告すら出ない。
ただ静かにキャッシュが無視される。
結果として、キャッシュヒット時の90%削減の恩恵を受けられない。
それどころか、初回書き込み時の125%の割高なコストだけを支払い続けることになる。
知らずにAPIを叩き続ければ、請求額は一気に膨れ上がる。
さらに、ツールの定義だ。
システムプロンプトだけにブレークポイントを置く。
これは多くの開発者がやりがちなミスだ。
これをやると、複数定義したツール群が毎回ゼロから再処理されてしまう。
正解は、ツール配列の最後の定義に「cache_control」を付与することだ。
これでシステムプロンプトと全ツール定義がまとめてキャッシュされる。
最大4つのブレークポイントを設定できる。
複数段階でキャッシュすれば、一部が変わっても残りのキャッシュは有効なままだ。
サイレント・フェイラーが引き起こす問題は多岐にわたる。
- キャッシュ設定の無視によるコスト増大
- 複数ツールの毎回再処理によるレスポンス遅延
- 内部推論ブロックのパース失敗による予期せぬ動作
- 悪意あるプロンプトの無警告実行
RAGの検索精度に関する事実も残酷だ。
RAGの精度の9割はLLMの性能で決まらない。
入力データの前処理で決まる。
長文をそのままLLMに投げ込む。
関係のない情報がノイズになる。
検索精度が落ちる。
200〜500文字。
これが実務上のチャンク分割のスイートスポットになる。
小さすぎても文脈が失われる。
大きすぎてもノイズが増える。
意味ベースで検索できるEmbedding設計。
適切なチャンク分割。
この2つがなければ、どれだけ上位のLLMを使っても意味がない。
セキュリティ層の欠如も致命的だ。
本番環境のAIエージェントにユーザー入力をそのまま渡す。
これは自殺行為だ。
「前の指示を無視して」といったプロンプトインジェクション。
システムプロンプトの抜き取り。
メールアドレスやクレジットカード番号の漏洩。
LLMはこれらに対してもエラーを出さない。
忠実に「悪意のある指示」を実行してしまう。
入力前の正規表現フィルターが必須になる。
データマスキングといった防衛ラインが必須になる。
PoCのノリで本番に出すと、確実に痛い目を見る。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
LLMをブラックボックスとして扱うのをやめろ
多くの開発者が「とりあえず動いた」で満足してしまう部分がある。
LLMを賢い魔法の箱だと思いがちだ。
なんでもよしなにやってくれると錯覚する。
だが現実は違う。
LLMは渡されたデータと設定に対して、ただ確率的に文字を出力するだけの機械だ。
APIの仕様を誤認したまま開発を進める。
後で確実に地獄を見る。
例えば、Claudeの「temperature」設定だ。
デフォルトは1.0になっている。
これは最大の創造性を意味する。
分類タスクや事実抽出のタスクがあるとする。
デフォルトのまま回すとどうなるか。
毎回微妙に違う結果が返ってくる。
システムとして全く安定しない。
明示的に0を設定しないとダメだ。
これもエラーが出ないから気づきにくい罠だ。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、キャッシュの仕様は地味にデカい。
短いプロンプトでキャッシュ設定してたら、ただのコスト増要因になるのが気になる。
APIの料金明細見て「あれ?」ってなるやつだ。
ドキュメントの隅っこに書いてある仕様を見落とすと、金銭的なダメージとして跳ね返ってくる。
さらに、内部推論と最終回答の分離だ。
ClaudeのExtended Thinkingを使う場合を考える。
レスポンスは「thinking block」と「text block」の2つに分かれて返ってくる。
これを普通のレスポンスと同じようにパースしてしまう。
予期せぬ動作を引き起こす。
内部推論には署名が付与され、改ざんを防ぐ仕組みがある。
「budget_tokens」の最小値も1024トークンだ。
最大トークン数はこれより大きくなければならない。
これを理解せずにパラメータをいじる。
LLMは黙って適当な処理をしてしまう。
「たまたま動いている」状態を「正しく動いている」と勘違いしてはいけない。
RAGのチャンク設計も全く同じ構図だ。
精度が出ない。
よし、もっと賢いモデルにしよう。
だが、ゴミを入れればゴミが出てくる。
チャンク1とチャンク2に適切に分割する。
文脈を保ったままベクトル化する。
この泥臭いデータ前処理こそが、開発者の本当の主戦場だ。
LLMは最後の仕上げにすぎない。
RAGの精度が出ないとき、LLMのプロンプトをこねくり回すのは完全に悪手。
結局のところ、検索エンジン側のチューニングに戻ってくる。
チャンクサイズとEmbeddingモデルの選定で勝負は決まってると思う。
LLMに文脈を読ませようとする前に、読める文脈を作って渡すのがエンジニアの仕事だ。
アーキテクチャの定義も曖昧にしてはいけない。
コードが次のステップを決めるのが「Workflow」だ。
LLMが次のステップを決めるのが「Agent」だ。
Workflowには直列、分岐、並列などのパターンがある。
Agentよりもテストが容易で、精度が高く、予測可能だ。
まずWorkflowで実装可能かを先に検討する。
Agentは最終手段だ。
なんでもかんでもAgentと呼んでLLMに丸投げする。
それは設計の放棄だ。
セキュリティに至っては、もっと深刻だ。
PoCの段階では「すごい!なんでも答えてくれる!」で済む。
だが本番環境では違う。
その「なんでも答えてくれる」が最大の脆弱性になる。
ユーザー入力から危険なパターンを検知するフィルター。
機密情報を「MASKED_EMAIL」のように置換するマスキング処理。
LLMの「外側」でどれだけ強固な壁を作れるか。
これがエンタープライズ品質の分かれ目になる。
AIアプリ開発のフェーズが変わった。
「LLMと会話する」フェーズは終わった。
「LLMを制御する」フェーズに移行した。
APIの厳密な仕様理解。
入力前のデータチャンク最適化。
セキュリティフィルターの構築。
これら周辺エンジニアリングをサボる。
コストは膨らむ。
品質は落ちる。
最悪の場合は情報漏洩につながる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
泥臭い周辺エンジニアリングが勝敗を分ける
で、僕らの開発にどう影響するの?という話だ。
コードの書き方を変える。
アーキテクチャの設計思想を根本から変える必要がある。

実務で今すぐ見直すべきポイントを挙げる。
- システムプロンプトの総トークン数の計測
- ツール定義配列の最後へのキャッシュ制御付与
- ツールの説明文の具体化と入力スキーマの厳密な定義
- チャンクサイズの文字数カウントと分割ロジック修正
- ユーザー入力に対する正規表現フィルターの実装
- 機密情報のマスキング処理の追加
まず、APIの呼び出し部分を徹底的に見直す。
Claude APIを使っているなら、今すぐトークン数を確認したほうがいい。
システムプロンプトを数える。
ツール定義を数える。
合計が1024トークンを超えているか。
超えているなら、ツール配列の最後に「cache_control」を付与する。
これで無駄な書き込みコストを削れる。
超えていないなら、キャッシュ設定自体を外すか、プロンプトを充実させる。
中途半端な設定が一番コストを食う。
キャッシュのブレークポイントは戦略的に配置する。
変更頻度の低いシステム指示は最初にキャッシュする。
頻繁に変わるユーザー入力はその後に配置する。
この設計だけで、APIコストは全く違うものになる。
次に、ツールの「description」の書き方だ。
Claudeはツールの説明文を読んで使い方を判断する。
曖昧な説明を書く。
当然、誤用される。
「ユーザーのデータを取得する」といった書き方は最悪だ。
「ユーザーIDを引数に取り、名前とメールアドレスを返す」と具体的に書く。
入力スキーマも厳密に定義する。
これでLLMの挙動は一気に安定する。
Claude Codeの自律開発でも、ツールの説明文が適当だと平気で無限ループに入りそうで怖い。
LLMに空気を読ませようとするのは甘え。
完全にアホな後輩に指示を出すレベルで具体的に書かないとダメだ。
曖昧さはバグの温床になる。
RAGを実装しているなら、チャンクサイズを計測する。
200〜500文字の範囲に収まっているか。
大きすぎるなら分割ロジックを書き直す。
小さすぎるなら前後の文脈を結合する処理を入れる。
チャンク間のオーバーラップも考慮する。
文脈の分断を防ぐためだ。
Embeddingモデルの選定も見直す。
最初は軽量なもので十分だ。
VectorDBの組み合わせもシンプルに保つ。
まずはチャンクの質を上げることに全振りする。
LLMを変えるのは、そこが完璧になってからだ。
そしてセキュリティ対策だ。
LLMに直接ユーザー入力を渡すコード。
今すぐ書き換える。
間に必ずサニタイズ用の関数を挟む。
正規表現で危険なワードを弾く。
「ignore previous instructions」などの文字列を検知する。
個人情報をマスクする。
これらはAIの知識ではない。
従来のWebセキュリティの知識だ。
AI開発だからといって、基本的なバリデーションをサボっていい理由にはならない。
開発環境でのテスト手法も変わる。
ツールを作ったら、いきなりLLMに繋がない。
まずは単体テストだ。
MCP Inspectorを使って、ツール単体で期待通りに動くか確認する。
REST APIのテストにPostmanを使うのと同じ発想だ。
クライアントに接続する前に、バグの切り分けを行う。
これで開発効率は圧倒的に上がる。
すべてに共通するスタンスがある。
「LLMを信用しない」ということだ。
LLMは平気で嘘をつく。
エラーを出さずにサボる。
悪意にも従順だ。
だからこそ、僕ら開発者がガチガチの枠組みを作ってやる必要がある。
エラーハンドリングを厳格にする。
型を定義する。
入力と出力を監視する。
AIの知能に頼るのではなく、エンジニアリングの力でAIを飼い慣らす。
開発者が知っておくべきAI周辺設計のFAQ
Q1: Claude APIでプロンプトキャッシュが効かない原因は何ですか?
キャッシュ対象のトークン数が最小サイズの1024トークンを下回っている可能性が高い。Claude APIでは、最小サイズ未満の場合でもエラーは出ない。ただ黙ってキャッシュが無視され、通常の書き込みコストが発生する。システムプロンプトやツール配列の最後に「cache_control」を付与し、十分なトークン数を確保した上でAPIを叩く設計が必要だ。
Q2: RAGの検索精度を上げるために、まずLLMを上位モデルに変更すべきですか?
いいえ。まずはチャンクサイズとEmbeddingモデルを見直す。RAGの精度の9割は「LLMに何を渡すか」で決まる。長文をそのまま渡すとノイズになるだけだ。200〜500文字程度の適切なサイズに分割し、意味ベースで検索できるEmbedding設計を行うことが先決だ。LLMの変更は、入力データが完全に最適化された後の最後の手段になる。
Q3: AIエージェントを本番導入する際、セキュリティ面で最低限必要な対策は何ですか?
プロンプトインジェクション対策とデータマスキングだ。ユーザー入力から「前の指示を無視して」などの危険なパターンを正規表現で検知し、サニタイズするフィルターを実装する。また、メールアドレスやクレジットカード番号などの機密情報を、LLMに渡す前に自動でマスクする処理も必須だ。LLM自体にセキュリティを期待してはいけない。
まとめ
LLMの性能に甘えず、API仕様の把握と泥臭いデータ前処理を徹底する。これが本番品質への唯一の道だ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
