
AIエージェントの運用フェーズが変わった。
プロンプトを調整するだけでは不十分だ。
これからはAIの「記憶」をコードとして運用する時代だ。
設定ファイルを放置すると、2週間後にはAIの精度が低下する。
最新のアップデートと開発コミュニティの動向から、明確なトレンドが見えてきた。
開発者は、AIに指示を出すユーザーから、AIのコンテキストを維持するSREの役割を担う。
AIが自律的に動くほど、裏側の記憶管理がプロダクトの品質に直結する。
この変化を捉えることが、開発効率を維持する鍵だ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIの「記憶」がインフラになる日
Claude Codeに大規模なアップデートが適用された。
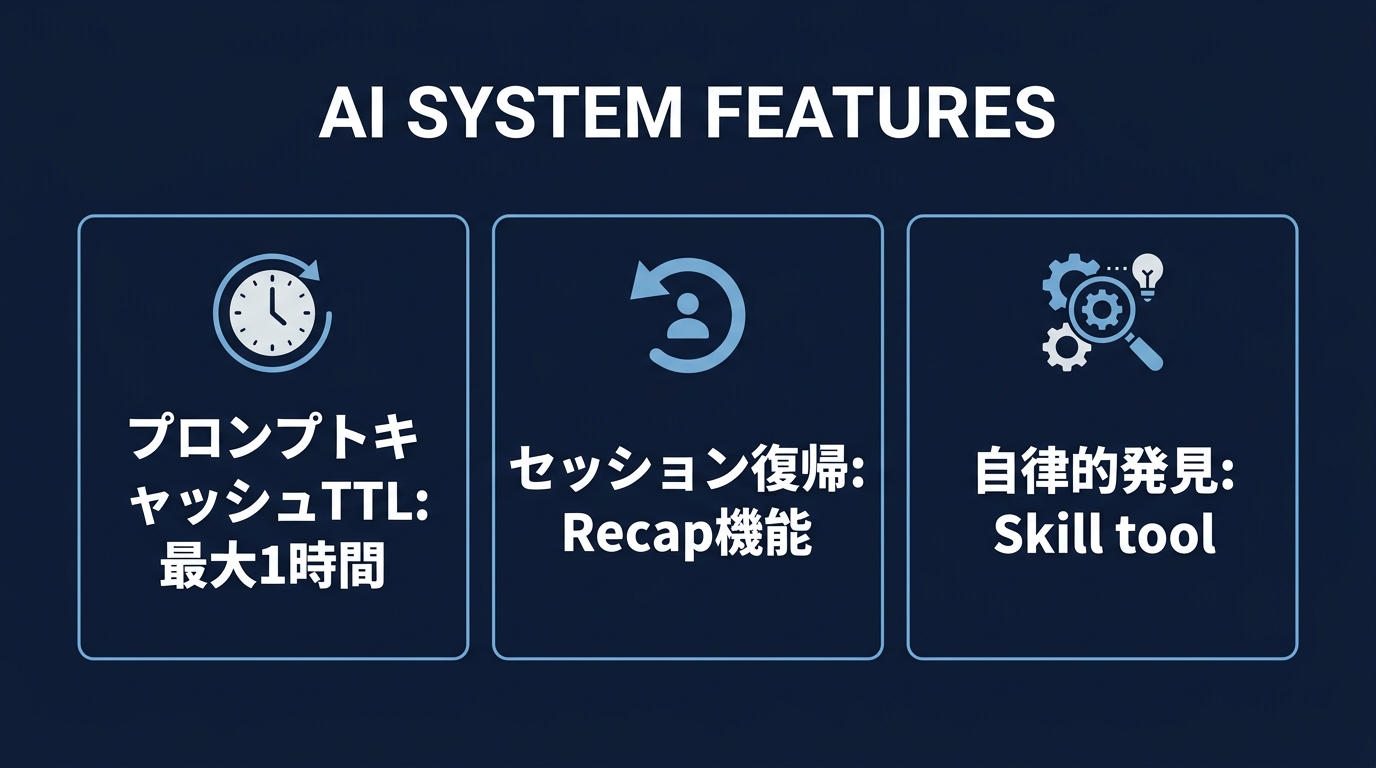
注目すべきは、セッション復帰時のコンテキストを提供するrecap機能の追加だ。
セッションを離れて戻ってきた際、AIは文脈を見失うことがあった。
この機能により、コマンドを呼び出して文脈を瞬時に復元できる。
テレメトリを無効にしている環境でも、環境変数で強制的に有効化が可能だ。
さらに、AIモデル自身が組み込みコマンドを発見して実行できるSkill toolも導入された。
AIが自らの能力を把握し、必要なツールを自律的に選択する。
これはAIが自身のコンテキストを管理するためのインフラ整備だ。
プロンプトキャッシュのTTLも環境変数で1時間に設定できるようになった。
強制的に5分のTTLを設定するオプションも追加されている。
APIコストを抑えつつ、長時間のセッションでもコンテキストを維持しやすくなった。
エラーメッセージの改善も進んだ。
サーバーのレート制限とプランの利用枠制限が明確に区別されるようになった。
5xx系のエラーが発生した際は、ステータスページへのリンクが直接表示される。
未知のコマンドを入力した場合には、最も近いコマンドが提案される。
ファイルの読み込みや編集、構文ハイライト時のメモリフットプリントも削減された。
言語の文法定義をオンデマンドで読み込むことで、リソース消費を抑えている。
これらはすべて、AIエージェントを長時間、安定して稼働させるための布石だ。
一方で、開発コミュニティでは「AIの記憶」に対する根本的な見直しが進んでいる。
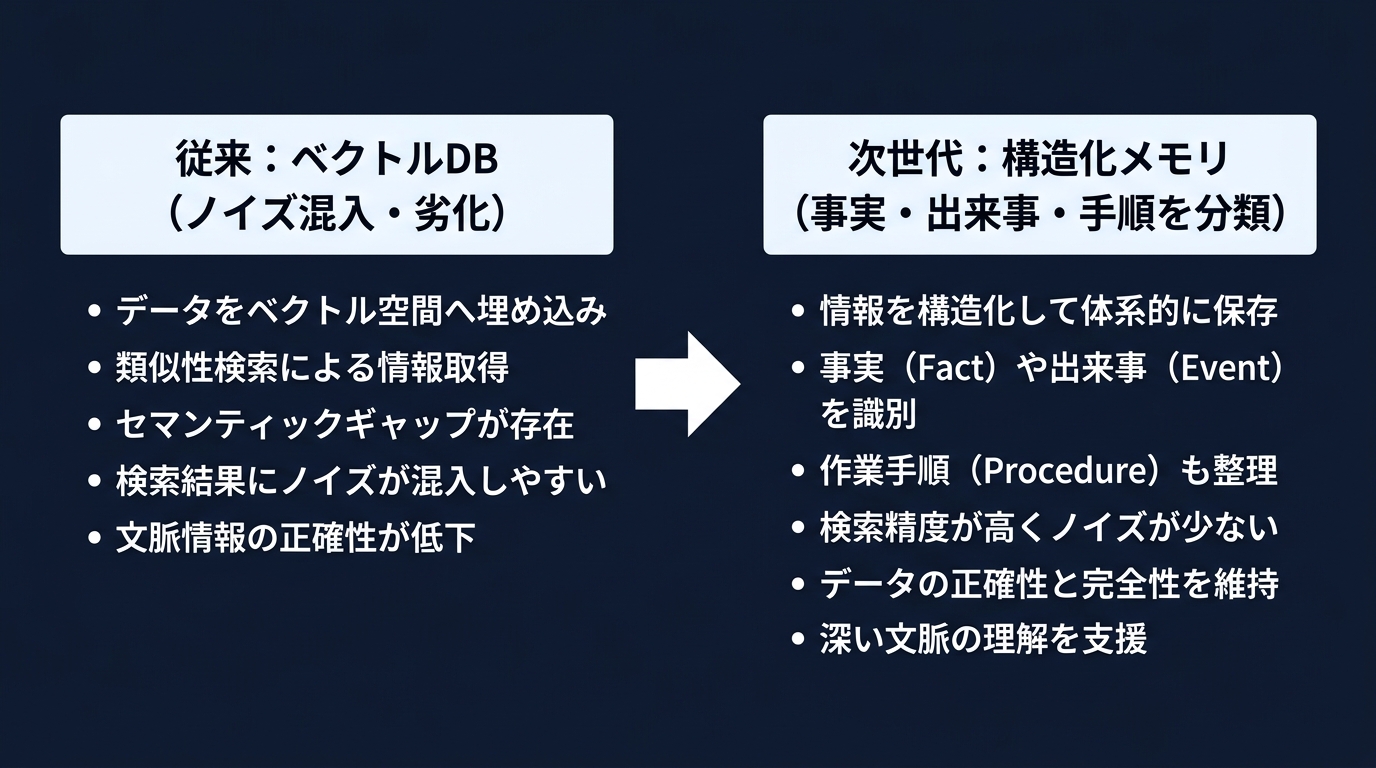
過去のチャットログをベクトルDBに格納し、RAGで参照する手法の限界が指摘されている。
現在の主流であるこの手法は、高機能な会話履歴に過ぎない。
ユーザーの指示、AIの思考プロセス、ツールの実行結果、挨拶がすべてテキストの塊として同列に扱われている。
何が重要な事実で、何が一時的なイベントなのかが構造化されていない。
結果として、検索時に大量のノイズが混入する。
セッションの要約を繰り返すと、情報が劣化する。
AIは覚えているように見えて、実は劣化し続けるテキストを毎回読み込まされているだけだ。
解決策として、記憶を構造化するアプローチが注目されている。
情報を普遍的な事実、過去の出来事、獲得した手順などに分類する。
特定のアプリやモデルに依存しない、プラットフォーム中立な記憶インフラの構築が進行している。
同時に、設定ファイルの運用方法も進化している。
「CLAUDE.md」のような設定ファイルは、一度書いたら終わりではない。
機能の追加や廃止に合わせて、設定ファイルも更新し続ける必要がある。
使われていない設定が残ると、AIの判断基準がブレる。
整理されていない部屋にルンバを置いても、障害物を避けるだけで掃除にならない。
設定ファイルと実際の機能の整合性を自動検証する仕組みが導入されている。
AIエージェントの運用は、SREの領域に突入した。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
AI SREという新しい職務
しんたろー:
recap機能の追加が気になる。セッション再開するたびにコンテキストを再構築する手間が省けるのは助かる。キャッシュのTTLが1時間に延びたのも、APIのコスト的にありがたい。
Claude Codeが公式にコンテキスト管理をサポートし始めた意味は重い。
これまで開発者が手動で行っていた記憶のやりくりを、ツール側が巻き取り始めている。
しかし、ツールに任せきりではいけない。
開発者は、AIが参照する設定ファイルや記憶領域を保守・運用する責任がある。
AIエージェントに対するSRE的アプローチが必要だ。
設定ファイルは設計するものではなく、運用するものだ。
コードと同じで、設定ファイルも書いた瞬間から腐り始める。
機能が消えたのに設定だけ残っている状態は、AIのコンテキストを汚染する。
AIは「このルールはまだ有効なのか?」を自力では判断できない。
不要なルールを避けながら動くAIは、本来のパフォーマンスを発揮できない。
これを防ぐには、機能と設定ファイルの対応表を作ることが有効だ。
そして、その対応表と実際のファイルの整合性を自動検証する仕組みを導入する。
RAGを使った記憶管理の限界も認識すべきだ。
現在のRAGは、揮発性メモリの補完としては優秀だ。
しかし、長期運用するエージェントの永続ストレージとしては不十分だ。
真のAIメモリには、記憶の構造化が不可欠だ。
背景情報、普遍的な事実、過去の出来事、会話ログ、AI自身の反省、獲得した手順を分類し、メタデータを付与して保存する。
いつ、誰が、どのコンテキストでこの記憶を生成したのか。
複数の記憶が矛盾した場合、どちらを優先するのか。
不要になった記憶をどうやって消去するのか。
これらを管理するガバナンス機能が求められている。
ベクトルDBに全部突っ込むアプローチは、ノイズだらけになってAIが的外れな回答をし始めることがある。記憶の構造化は、システムで真剣に考えないといけないフェーズだと思った。
プラットフォーム中立な記憶インフラの台頭も見逃せない。
特定のAIツールにロックインされた記憶は、他のツールで再利用できない。
ターミナルで動くAIが学習したコーディングスタイルを、ブラウザのAIが知らない。
これは長期的な運用においてボトルネックになる。
ユーザーに紐づく記憶のパスポートのような仕組みが求められている。
記憶のオーナーシップは、AI企業ではなくユーザー自身が持つべきだ。
Claude Codeのアップデートは、この未来に向けた第一歩だ。
自律的なコンテキスト管理と、外部の記憶インフラが統合される日は近い。
開発者は今、AIの記憶をどう設計し、どう運用するかという分岐点に立っている。
AIの判断基準をコードとして明文化する。
定期的にクリーンアップする仕組みを構築する。
これが、エージェントの性能を維持する鍵だ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
設定ファイルを「運用」する
日々の開発にどう落とし込むべきか。
まずは、設定ファイルに対するAIの権限設計を見直す必要がある。
AIに自律性を与えつつ、暴走を確実に防ぐ仕組みだ。
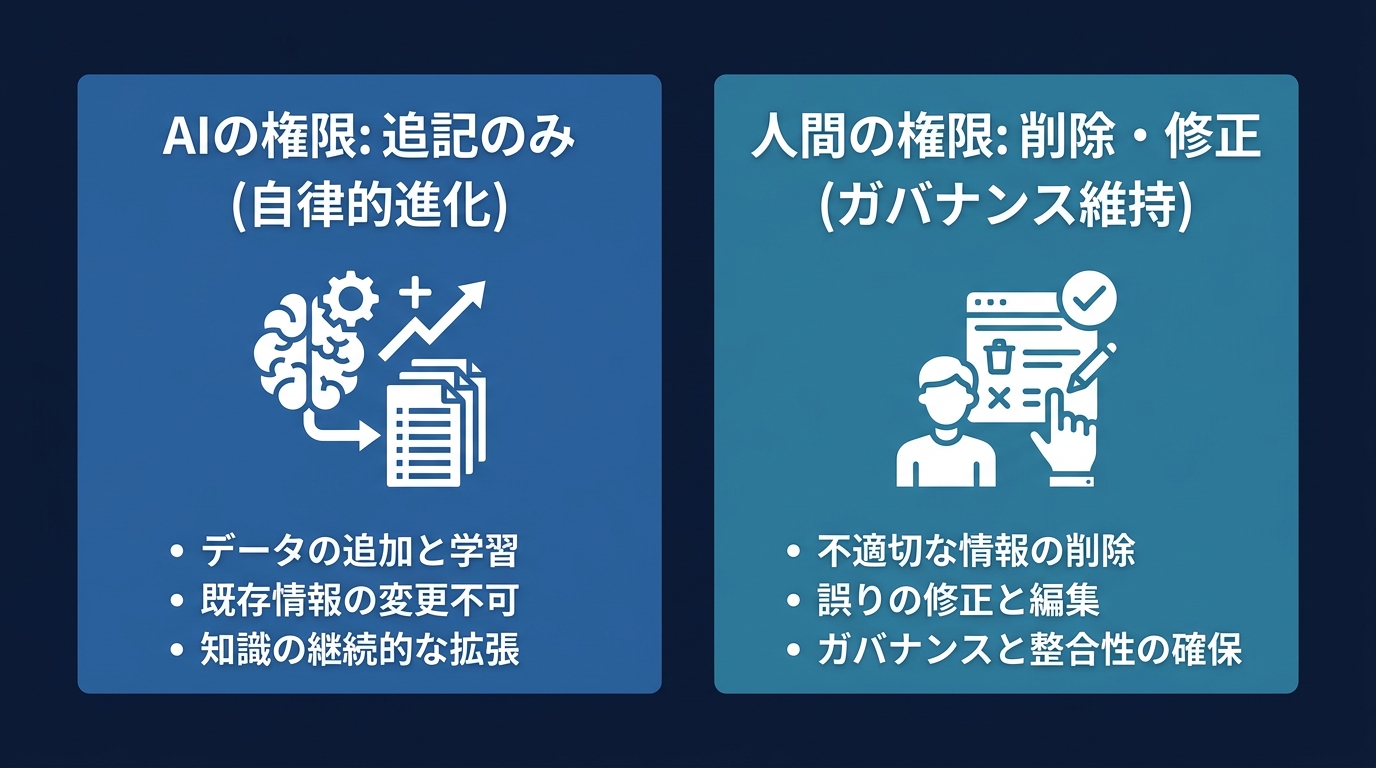
「追記はOK、削除はNG」の非対称な権限設計が有効だ。
新しい失敗パターンやコーディング規約の追加は、AIに事前承認を与える。
AIがセッション中に気づいた改善点を、その場で設定ファイルに反映させる。
一方で、ルールの削除や緩和は人間が判断する。
ルールを厳しくする方向は安全だが、緩める方向はリスクが高い。
不要だと思ったルールが、実は重要なセキュリティ要件だったという事故を防ぐ。
この権限設計により、AIは自律的に進化し続けることができる。
「次のセッションで対応しよう」という先送りがなくなる。
AIが自ら学習し、自らのルールをアップデートしていく環境が整う。
コンテキストの分離も原則だ。
同じデータ収集でも、技術ニュースとセキュリティ情報では扱いが異なる。
技術ニュースは週に一度、人間が眺めれば十分だ。
しかし、重大なセキュリティ情報は毎日AIがトリアージし、即座に通知する必要がある。
頻度、コスト、判断の重みが違う処理を、1つのスクリプトに混ぜてはいけない。
分離することで、影響範囲を絞り、AIの判断をシンプルにする。
本番環境の保護も徹底する。
外部APIや公開リポジトリへの変更は、必ずドライランで先行確認する。
ドライランできないスクリプトは本番投入しない。
この原則を明文化し、AIに厳格に遵守させる。
AIに設定ファイルの追記権限を渡すのは理にかなっている。人間が毎回レビューしてたら、それが最大のボトルネックになる。削除だけ人間がやるっていう非対称性、絶妙なバランスだと思った。
ヘルスチェックの自動化も行う。
設定ファイルと実際のコードの乖離を、スクリプトで定期的に検出する。
使われていない設定を見つけたら、アラートを出して人間が判断して削除する。
この検知と修復のサイクルを回すことが、AI SREの基本だ。
設定ファイルは放置すれば散らかる。
維持する仕組みを作って初めて、AIの自動化は完成する。
AIの記憶をRAGに頼り切っている場合は、アーキテクチャの見直しを検討する。
すぐに完全な記憶インフラを構築するのは難しいが、少なくとも事実と出来事を分けて保存する仕組みから始める。
APIキーの場所やコーディング規約は普遍的な事実だ。
昨日のデプロイが失敗した理由は過去の出来事だ。
これらを同じデータベースにフラットに保存するのは避ける。
AIエージェントは、与えるコンテキストの質に依存している。
質の高いコンテキストを継続的に提供し続けること。
それが、これからの開発者に求められるスキルだ。
開発者が知っておくべきAI記憶管理のFAQ
Q1: Claude Codeで設定ファイルがすぐに散らかるのを防ぐには?
設定ファイルを一度書いたら終わりのドキュメントではなく、コードと同様に運用するものと捉えてください。機能の対応表を作成し、ヘルスチェック用のスクリプトで使われていない設定を自動検知する仕組みを導入するのが有効です。また、AIにはルールの追記権限を与えつつ、ルールの削除は人間が判断するという非対称な権限設計を行うことで、安全かつ自律的な進化が可能になります。
Q2: AIの「記憶」をRAGで実装するのは古いのでしょうか?
古いわけではありませんが、単なるベクトルDBへの保存は高機能な会話履歴に留まります。長期運用するエージェントには、情報を事実、出来事、手順のように構造化して保存する仕組みが必要です。現在のRAGは揮発性メモリの補完としては優秀ですが、エージェントが成長し続けるためには、モデルやアプリケーションから独立した記憶インフラとして設計し直すフェーズに来ています。
Q3: 記憶のプラットフォーム中立性とはどういうことですか?
特定のAIツールやモデルに依存せず、記憶データを独立して管理・利用できる状態のことです。例えば、ターミナルで動くAIが学習した好みのコーディングスタイルを、ブラウザで動く別のリサーチAIも参照できるのが理想です。記憶が特定のアプリにロックインされると、複数のAIエージェントを協調させる際にボトルネックになります。ユーザー自身が記憶のオーナーシップを持つアーキテクチャが求められています。
設定の運用がAIの知能を決める
AIに賢いプロンプトを投げる時代から、AIが賢く居続けられる環境を構築する時代になった。
記憶の構造化と設定ファイルの継続的な運用が、今後の開発効率を左右する。
AIのコンテキスト管理は、そのままプロダクトの品質に直結する。
SREの視点を持って、AIの運用基盤を整える。
記憶を制する者が、これからのAI開発を制する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
