
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
表現力が上がっても嘘はつく
GoogleがGemini 3.1 Flash TTSを正式リリースした。70以上の言語に対応し、オーディオタグで声のトーンやスピードを自然言語で制御できる。
音声品質のブラインドテストでEloスコア1,211を記録した。低コストで高品質な音声生成が可能になる。
開発者は手放しで喜んではいけない。モデルが賢くなるほど、もっともらしい嘘に騙されやすくなる。
表現力の向上は、ハルシネーションのリスクと表裏一体だ。
Gemini 3.1 Flash TTSの実力と構造
Gemini 3.1 Flash TTSは、オーディオタグによる細かな制御機能を持つ。テキスト入力の中に自然言語のコマンドを直接埋め込むことができる。
AIが声のスタイルや話すペースを文脈に合わせて自動調整する。対応言語は70以上にのぼる。
生成された音声にはSynthIDという電子透かしがネイティブで埋め込まれる。人間の耳には聞こえないレベルで、波形に直接情報を書き込む技術だ。
AI生成音声であることを識別し、フェイク音声の拡散を防ぐ。

サードパーティの評価機関による数千人規模のブラインドテストで、Eloスコア1,211を記録した。高品質かつ低コストの領域に位置するモデルだ。
マルチスピーカーによる対話のネイティブサポートも備える。複数の異なるキャラクターが掛け合う音声を、1つのモデルで生成できる。
専用のスタジオ環境を使えば、声のトーンやパラメータをGUIでチューニングできる。設定をエクスポートしてAPI経由で呼び出すことで、一貫した音声体験を提供可能だ。
表現力が豊かになることと、出力がシステム的に正確であることは別の問題だ。ここを混同すると、実務の開発現場でバグを生む。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発者が直面するAIの「もっともらしい嘘」
AIモデルの進化は速い。しかし、基盤にあるLLMの推論能力には、ハルシネーションのリスクが潜んでいる。
画像内のテキストを翻訳するシステムを組む際、AIにAPIの実装方法を聞くと、存在しない架空のメソッドを提案してくることがある。公式ドキュメントに存在しないAPIエンドポイントを、実在するかのように出力する。
LLMは事実の記憶よりもパターンの補完を優先するアーキテクチャだ。次に来る確率が最も高い単語を予測し続ける仕組みが、この現象を引き起こす。
テキスト翻訳のメソッドが存在する。ドキュメント翻訳のメソッドも存在する。ならば、画像翻訳のメソッドも同じ命名規則で存在するはずだと、LLMは確率的に推論し、もっともらしい名前の関数を生成する。
しんたろー:
Claude Codeでコードを書いていると、この「存在しないメソッドの提案」に遭遇する。エラーが出てから修正ループに入るのは時間の無駄だ。最新モデルでも嘘をつくため、公式ドキュメントのRAG化は避けられないと感じる。
エラーを指摘しても、AIはSDKのバージョンや環境変数のミスだと言い訳を重ねる。根本的な「そのメソッド自体が存在しない」という事実をなかなか認めない。事実に基づかない推論を、論理的な言葉でコーティングして出力する。
音声認識の領域でも同じ問題が起きる。高精度な音声認識モデルは、聞こえた音をすべて忠実にテキスト化しようとする。「えー」「あの」といったフィラーワードも、そのまま文字起こしされる。
小数点を含む数値がスペースで区切られたり、日付のフォーマットが崩れたりする。出力されたテキストは、そのままではシステムに組み込めない未加工の素材だ。
ノイズだらけの生テキストをLLMに渡すと、崩れたテキストから無理やり文脈を読み取ろうとし、過剰な補正をかける。話し手が言っていないことを生成するハルシネーションを引き起こす。
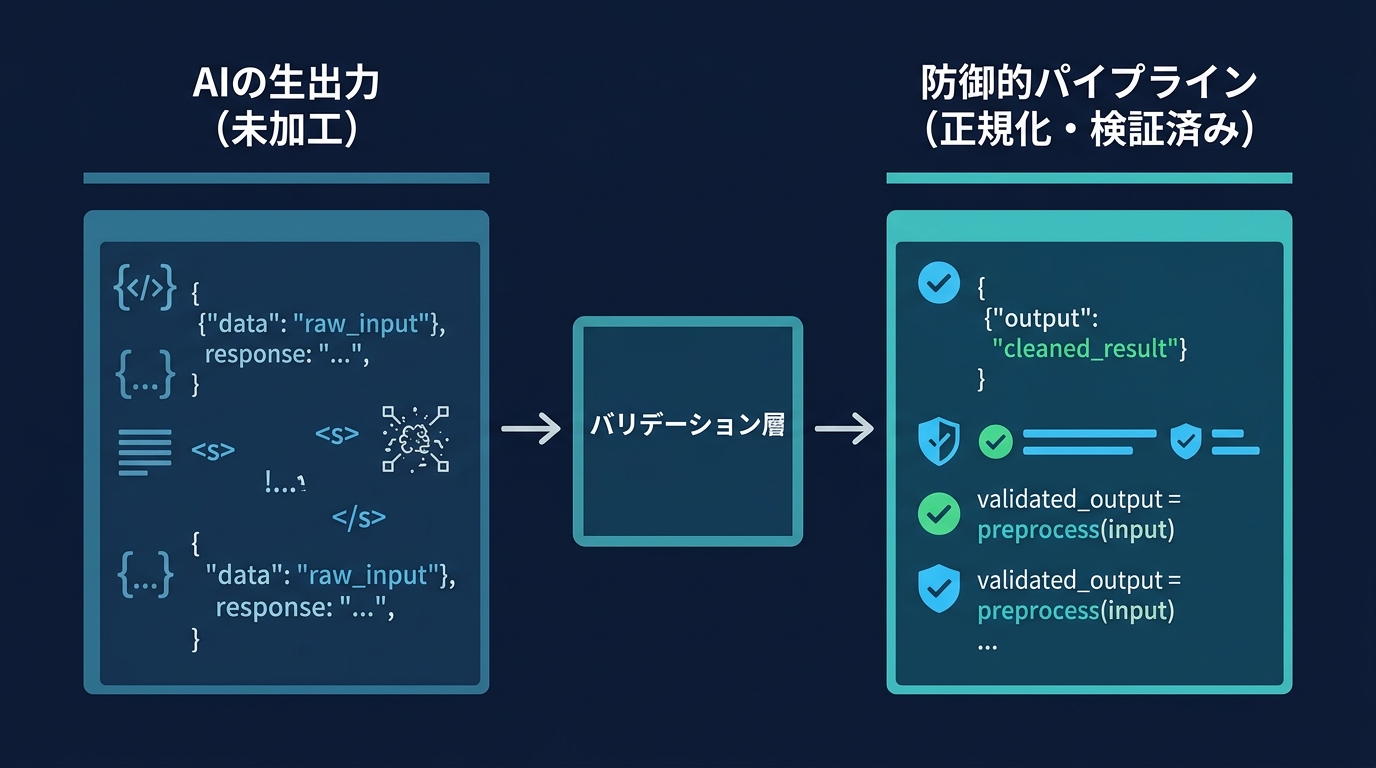
AIの出力は完成品ではない。開発者は、AIをパイプラインの不確実な部品として扱う視点が必要だ。
音声認識の精度を測る指標にCER(文字誤り率)やWER(単語誤り率)がある。これらの数値が改善されても、音を文字にする精度が上がっただけだ。意味のあるテキストデータとして使えるかは別の話だ。
AIが生成するコードも、テキストも、音声も同じだ。モデルの表現力に目を奪われ、出力の正確性の検証を怠れば、システムは破綻する。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
防御的AIアーキテクチャの構築
モデルの出力を信頼しすぎない設計が、開発現場には不可欠だ。AIの不確実性を前提としたシステム作りが求められている。
入出力の前後に強力なバリデーション層を設ける。LLMの嘘をシステム境界で遮断する、堅牢なパイプラインを構築する。これが防御的AIアーキテクチャの基本思想だ。
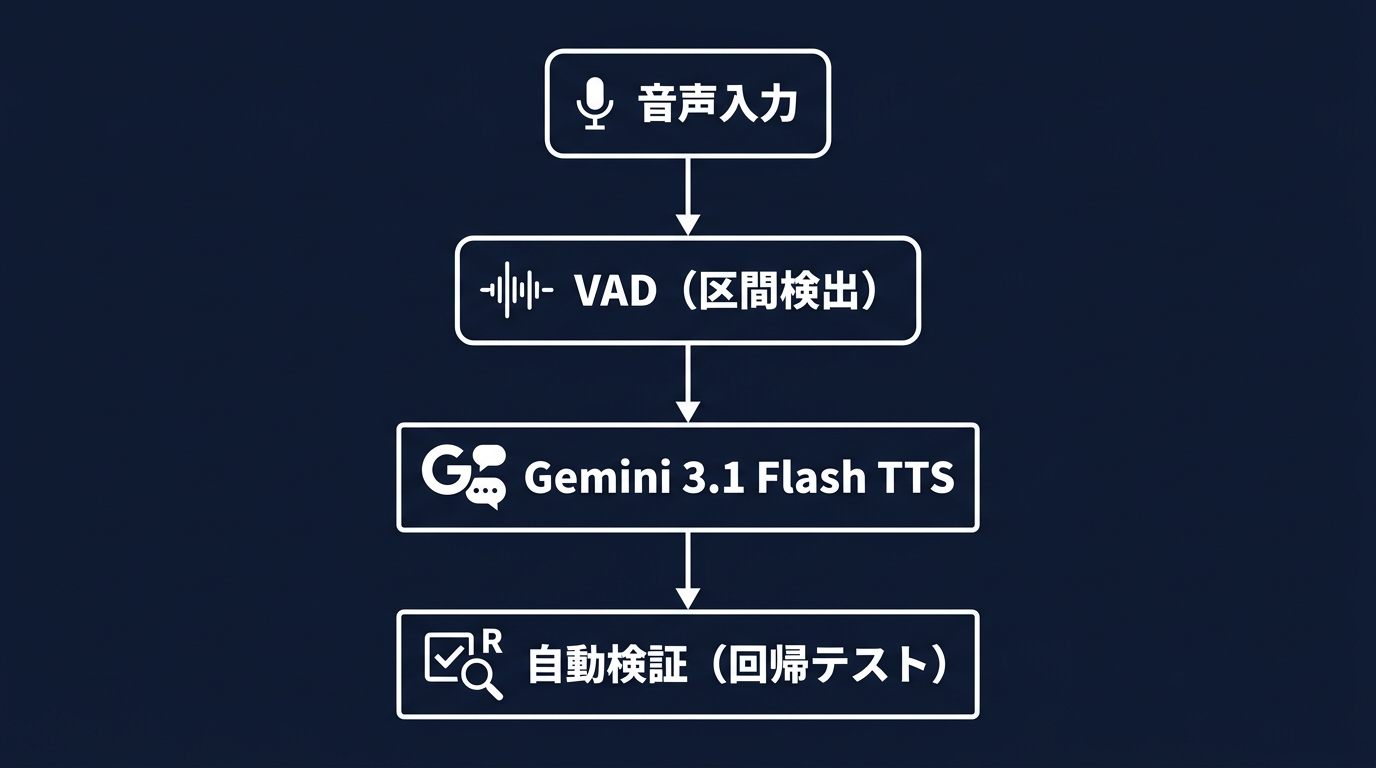
音声処理のパイプラインであれば、音声認識の前にVAD(音声区間検出)を挟む。VADは音声データの中から、人間が実際に話している区間だけを切り出す技術だ。無音区間や環境ノイズを事前に排除することで、後続のモデルが誤認識するリスクを減らせる。
VADなしで音声認識を回すと、無音区間で謎のハルシネーションテキストが生成されることがある。軽量なVADライブラリをパイプラインの先頭に置くだけで、後段のLLMの挙動が安定する。
ルールベースの処理と、LLMによる確率的な処理を分離する。フィラーワードの除去や数値フォーマットの正規化は、正規表現などのルールベースで行う。LLMは、文脈理解が必要な高度な処理にのみリソースを割く。
コード生成の自動化においても、アプローチは同じだ。AIエージェントが生成したコードを、そのまま実行環境に突っ込んではいけない。
静的解析ツールや型チェックを、デプロイパイプラインに組み込む。存在しないメソッドの呼び出しや型の不一致を、実行前のビルド段階で自動検知して弾く仕組みを作る。公式ドキュメントを管理し、AIには知らないことは知らないと答えさせるプロンプト制約をかける。
Gemini 3.1 Flash TTSのオーディオタグも例外ではない。自然言語での音声制御は便利だが、AIのプロンプト解釈には確率的なブレが伴う。
特定のタグの組み合わせに対する出力結果を、テストケースとして保存する。モデルのバージョンアップや環境変化によって期待通りの音声品質が損なわれていないか検証する回帰テストの仕組みが、音声AIの実務導入には必須となる。
表現力が上がることは、ブラックボックスが深くなることと同義だ。入力のサニタイズと出力の検証を自動化できるかが勝負になる。AIの出力をそのままユーザーに見せるルートは潰している。
AIの暴走をシステムレベルで封じ込め、安全に能力を抽出する仕組みを作る。魔法のようなAIツールが登場する時代だからこそ、泥臭い検証プロセスの価値が上がっている。
よくある質問
オーディオタグはハルシネーションを起こさないのか?
オーディオタグはスタイル制御というタスクですが、LLMが自然言語コマンドを解釈する以上、確率的な挙動は避けられません。意図しない感情表現や不自然な間が生成されるリスクは存在します。重要な音声を生成する場合は、特定のタグ設定に対する出力結果をテストケースとして保存してください。定期的な回帰テストを行う仕組みが必須です。
AIのハルシネーションを防ぐために今すぐできることは?
LLMにAPIの仕様やメソッド名を推測させないことが重要です。公式ドキュメントを検索ソースとして管理し、システムプロンプトで「知らない情報は出力しない」よう制約をかけます。コード生成においては、静的解析や型チェックをパイプラインに組み込んでください。存在しないメソッドの呼び出しを、実行前に自動検知して弾く仕組みを作ることが効果的です。
音声AIパイプラインでVADが必須なのはなぜか?
VADがないと、無音区間や環境ノイズをモデルが無理やりテキスト化しようとして、ハルシネーションを引き起こすからです。音声認識モデルは聞こえた音をすべて文字にする性質を持っています。VADを使って人間が話している区間だけを切り出すことで、後続のLLMに渡すテキストのノイズを削減できます。システム全体の精度と安定性が向上します。
AIの表現力に振り回されない開発を
Gemini 3.1 Flash TTSの進化は大きい。しかし、AIの出力は常に未加工の素材であるという前提を忘れてはいけない。堅牢なパイプライン設計こそが、次世代のAI開発の要になる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
