
APIコストが溶ける。AI開発者の共通の悩みだ。
20ターンのやり取りで消費トークンは20万を超える。
これを半減させる技術が普及している。
プロンプトキャッシュとハーネスエンジニアリングだ。
この2つを組み合わせる。AIの運用効率が変わる。
インフラとガードレールを統合するシステム設計の話だ。
AIエージェントを使いこなすためのパラダイムシフトが起きている。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AI開発のコストを支配する2つのフェーズと推論の仕組み
AI開発コミュニティで「ハーネスエンジニアリング」と「プロンプトキャッシュ」の組み合わせが話題だ。
AIにただ「お願い」する時代は終わった。
周辺の仕組みでAIを制約し、同時にキャッシュを効かせる。
これが実務レベルでのAI開発の最適解だ。
このトレンドを理解するには、LLMの仕組みを知る必要がある。
LLMの推論プロセスは2つの段階に分かれている。
前段の「prefillフェーズ」と、後段の「decodeフェーズ」だ。
prefillフェーズは、入力プロンプト全体を読み込む段階だ。
ここでTransformerの内部表現を作り上げる。
入力されたすべてのトークンについて、Query、Key、Valueという3種類のベクトルを計算する。
アテンション機構を用いて、すべてのトークン同士の関連性を一度に算出する。
この段階が、計算資源を激しく消費する。
AIに初回メッセージを送ったとき、応答まで数秒待たされる。
あの待ち時間の大部分は、prefillフェーズにおける行列計算に費やされている。
一方、decodeフェーズは返答を1トークンずつ生成する段階だ。
過去の状態を参照しながら、確率的に次の1文字を決める。
prefillに比べると軽い処理だ。
各トークンのKeyとValueというベクトルは、そのトークンより前にある内容だけで決定される。
後ろに新しいトークンが追加されても、前半部分の計算結果は変わらない。
この性質から、2回目以降のprefillは前半部分の計算をスキップできる。
一度計算したKeyとValueを、推論サーバーのメモリ上に保持する。
同じ内容のプレフィックスを含む次のリクエストが来たら、計算結果を使い回す。
これがKVキャッシュ、すなわちプロンプトキャッシュの仕組みだ。
キャッシュが短縮するのはprefillフェーズのみだ。
decodeフェーズの速度は向上しない。
2回目以降の応答が速く感じるのは、prefill時間が短縮されているからだ。
回答生成にかかる時間自体は、キャッシュの有無にかかわらず一定だ。
この仕組みを理解していないと、無駄なコストを支払い続ける。
プロンプトの構造を少し変えるだけで、キャッシュは壊れる。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
ステートレスなAPIの罠とキャッシュの絶対的価値
Claude Codeを実務で使う上で、知っておくべき仕様がある。
APIはステートレスだ。
サーバー側に会話状態を保持する仕組みは存在しない。
ユーザーが1つ質問を投げるたびに、過去の会話履歴をすべてパッケージ化して送信している。
システムプロンプトやツール定義のJSONデータだけで、合計2万トークンを超える。
会話が進めば、探索したソースコードの中身や実行したコマンドの標準出力が積み上がる。
過去のAIの応答も、すべて末尾に追記される。
20ターンも進めば10万トークンに達する。
30ターンで20万トークンを超えることは珍しくない。
これを毎回ゼロから処理すればコストは跳ね上がる。
応答も毎回遅くなり、開発のテンポが落ちる。
数時間のコーディングで数千円のAPI代が消費される。
個人開発者にとっては無視できない出費だ。
プロンプトキャッシュが生命線になる。
Claude Codeでは、このキャッシュ機能が自動で有効だ。
ユーザーが特別な設定をしなくても、変更がない履歴部分はキャッシュ対象として扱われる。
2ターン目以降は、前回と同じプレフィックス部分が丸ごとキャッシュから読み込まれる。
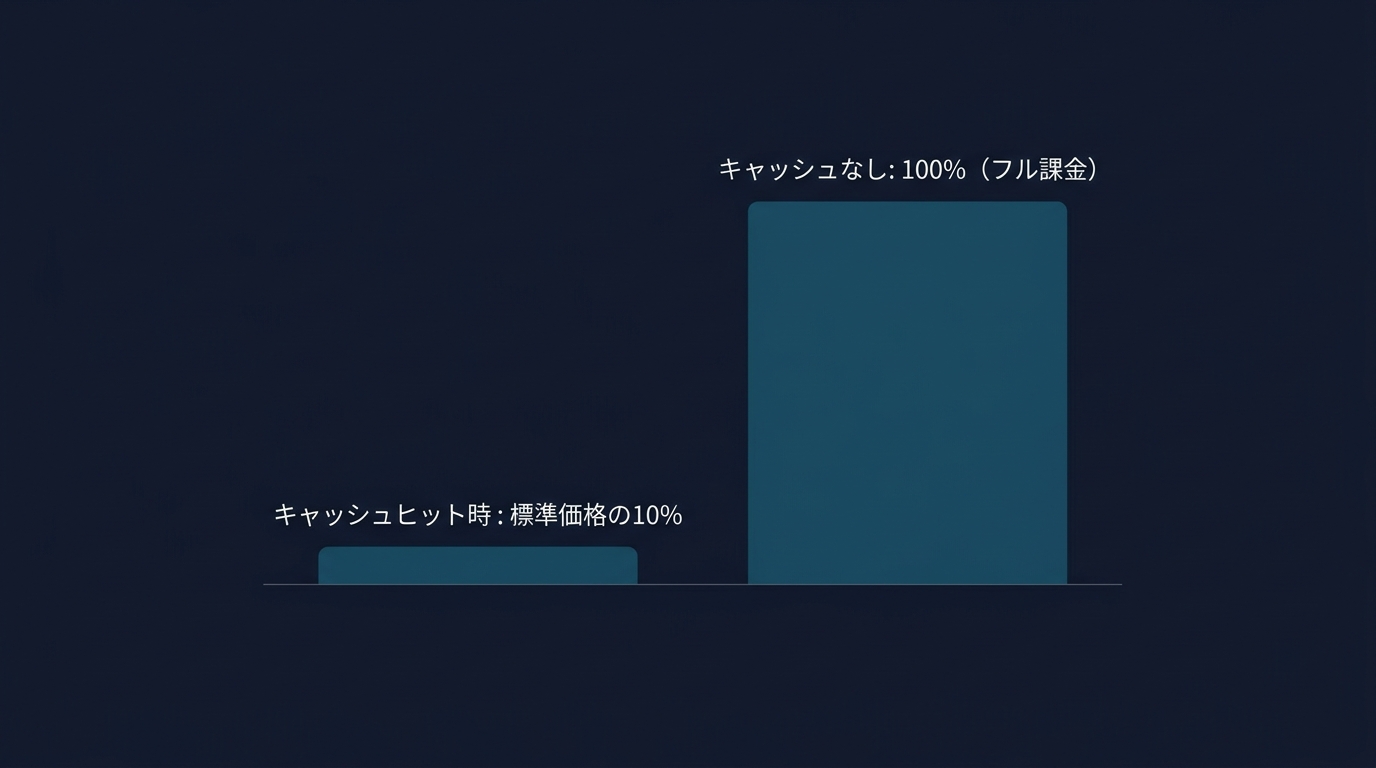
キャッシュヒット時のコストは、標準入力価格の10パーセントだ。
キャッシュを有効活用できれば、APIコストは10分の1に圧縮される。
5分間有効なキャッシュであれば、1回の読み出しで元が取れる。
キャッシュが効かない使い方をしていると、開発資金が底をつく。
しんたろー:
ログの出力とか全部AIに投げっぱなしにしてると、トークンが溶ける。
キャッシュ効いてると思って油断してたら、途中でコンテキスト途切れてフル課金されてた時の絶望感がある。
ステートレス通信の仕組み分かってないと、Claude Codeは高級おもちゃで終わる。
ここで「ハーネスエンジニアリング」という概念が重要な意味を持つ。
ハーネスとは元々、馬を制御する馬具のことだ。
馬具は馬の脚力を削ぐものではない。
全力で走れるように方向を制御するためのものだ。
方向の制御を馬具に任せることで、馬は「走る」ことだけに集中できる。
AIエージェントにも同じ発想が適用できる。
AIにすべてを考えさせるのではなく、周辺の仕組みで物理的な制約をかける。
これがハーネスエンジニアリングの核心だ。
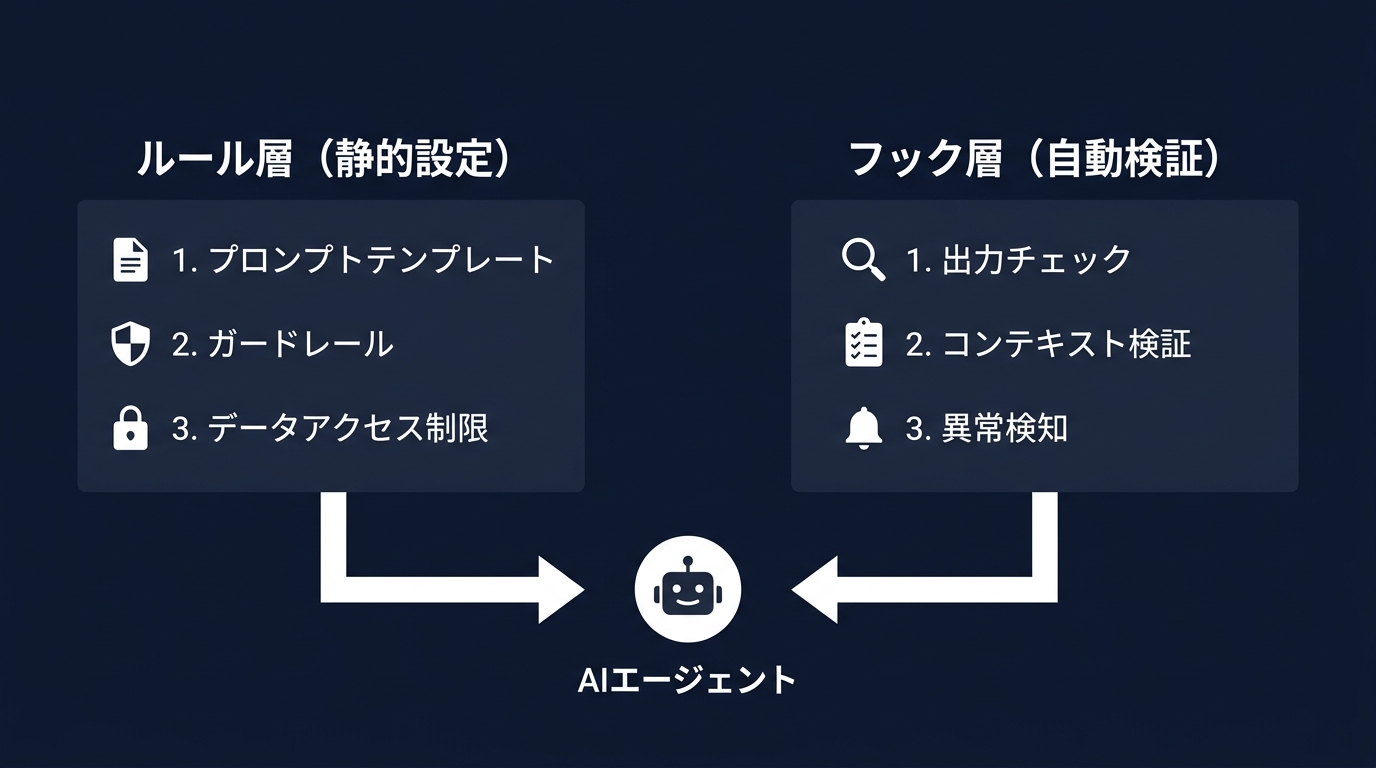
ハーネスは主にルール層とフック層で構成される。
ルール層は、プロジェクトのコーディング規約や前提条件を静的に定義する部分だ。
Claude Codeでは、プロジェクトルートに配置するマークダウンファイルがこれに当たる。
すべての関数にTypeScriptの型アノテーションを付ける。
特定の型は使用禁止にする。
ファイル操作は非同期のモジュールを使う。
これらを明確なルールとしてAIに提示する。
曖昧な指示は排除し、システム的に検証可能なルールだけを記述する。
フック層は、AIの行動に対して自動的に処理を挟み込む仕組みだ。
AIがファイルを編集したり新規作成したりした直後に、静的解析ツールを自動実行させる。
構文エラーや型エラーが出れば、そのログをAIに突き返して修正させる。
人間が介入する前に、AI自身に品質を担保させる。
この仕組みが機能すれば、人間がコードレビューをする時間は減る。
キャッシュとハーネスの美しい統合によるコスト破壊
ハーネスエンジニアリングとプロンプトキャッシュは、相性が良い。
両者を統合して初めて真の価値が生まれる。
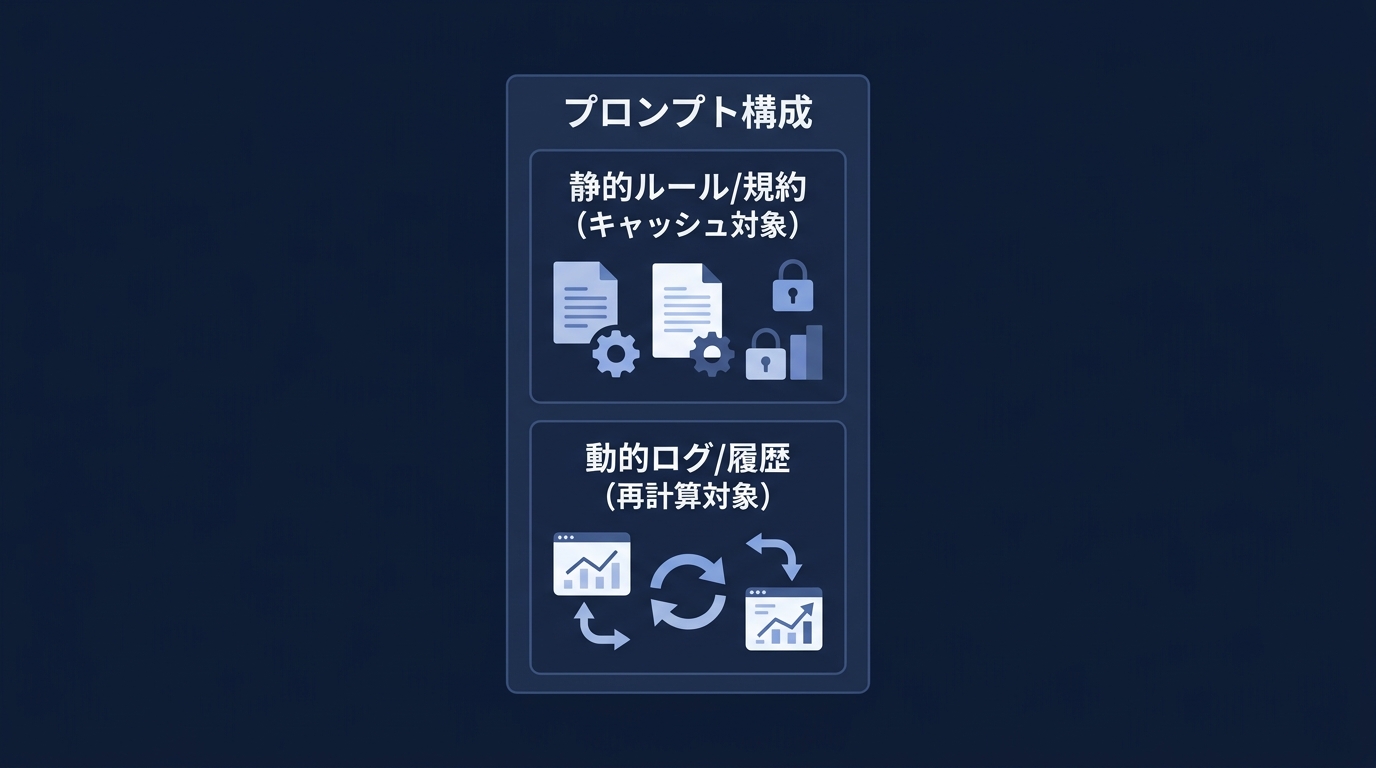
キャッシュは「前方一致」で効くという大原則がある。
変更されない静的な情報をプロンプトの先頭に固めて置くことが、キャッシュ効率を最大化する条件だ。
ルール層で定義した設定ファイルの内容は、「静的な情報」の塊だ。
システムプロンプトの直後に配置されるため、常にキャッシュの恩恵を受け続ける。
ルールを詳細に書いても、2回目以降の読み込みコストは10分の1のままだ。
詳細な制約を与えれば与えるほど、AIの出力は安定し、手戻りが減る。
コストは増えない。
これがキャッシュとハーネスを組み合わせるメリットだ。
頻繁に変わる情報はプロンプトの末尾に置く必要がある。
会話の途中で巨大なログファイルを読み込ませると、そこから後ろのキャッシュはすべて無効化される。
次に別の質問をしたとき、巨大なログファイルを含めた全履歴の再計算が発生する。
フック層の設計が重要になる。
フックで静的解析ツールを実行し、必要なエラーログだけを抽出してAIに渡す。
無駄な標準出力をすべてプロンプトに流し込むような真似は避けるべきだ。
必要な情報だけをコンパクトに末尾に積む。
これがキャッシュ効率を維持しながら品質を制御する技術だ。
フックでエラーログだけ抽出してAIに渡す仕組みは効率的だ。
昔はビルドエラーの全ログをコピペしてAIに投げてたけど、あれはキャッシュを壊す行為だった。
必要な情報だけ絞って渡すのが、AI時代の正しいエコシステム構築術だ。
フック層の実行結果もまたコンテキストの一部となる。
AIがコードを書き、フックがエラーを返し、AIが修正する。
この自己修復のループ自体が、ステートレスな履歴として末尾に積み上がる。
エラーメッセージは簡潔でなければならない。
冗長なスタックトレースはトークンを無駄に消費するだけでなく、AIの注意力を削ぐ。
エラーの核心部分だけを切り出して渡すシェルスクリプトをフックに仕込む。
JSON形式の出力をパースし、ファイルパスとエラー内容だけを抽出する。
無駄な情報を削ぎ落とすことが、AIの性能を引き出す。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
開発現場を変えるプロジェクト構成のベストプラクティス
この技術は日々の開発に影響を与える。
AIエージェントは単なるチャットツールではなくなる。
キャッシュとガードレールを備えた「自律型システム」として設計するスキルが求められる。
プロンプトの書き方よりもプロジェクト構成の設計が重要になる。
プロジェクトルートに設定ファイルを配置し、AIの行動指針を固定化する。
不要なファイルは除外設定で徹底的に弾く。
ビルド生成物や巨大なデータセットはAIに見せない。
これだけで、無駄なトークン消費は激減する。
AIが間違ったコードを生成する前提でシステムを組む。
AIに一発で完璧なコードを書かせようとするのは非効率だ。
間違えたら即座に検知し、AI自身に直させるループを作る。
フック層で静的解析やユニットテストを自動実行させる。
エラーが出れば、その結果をAIにフィードバックする。
このサイクルを人間が介在せずに高速で回す。
人間の時間は高コストだ。
AIの推論時間やAPIの呼び出しコストよりも、人間がコードを読んでデバッグする時間の方が高い。
ハーネスによってAIが最初から正しいルールを守るように強制する。
手戻りが減れば、プロジェクト全体の開発サイクルは高速化する。
AIにデバッグを任せることで、人間はアーキテクチャの設計に集中できる。
プロンプトキャッシュを活かすには、会話のライフサイクル管理も必要だ。
キャッシュは前方一致が基本であるため、会話が長くなりすぎると恩恵が薄れる。
初期の重要なコンテキストがキャッシュの対象外に押し出されるからだ。
1つのタスクが終わったらセッションをリセットする。
コンテキストを整理し、新しいセッションで次のタスクを始める。
これがコスト最適化の観点からは賢い選択だ。
会話の履歴をダラダラと引き継ぐのは、技術的負債を溜め込むのと同じだ。
「AIに任せる」という運用から卒業する時が来た。
キャッシュ効率を考慮したプロンプトの構造化と、ハーネスによる実行時の強制力。
この2つを組み合わせることで、コストと品質を制御する「AIエンジニアリングの型」が確立されつつある。
開発者は、コードを書く人から、AIのための環境を構築する人へと役割を変える。
ルールを定義し、フックを仕込み、キャッシュの挙動を監視する。
これが次世代の開発者の日常になる。
インフラストラクチャとしてのAIをどう制御するか。
その答えが、ここにある。
うちの開発環境も、この型に合わせて構成を全部見直した。
AIをどう縛るかが開発者の腕の見せ所だ。
自由に書かせたらダメだ。ガチガチにルール決めて、レールの上を爆走させるのが正解だ。
FAQ
Q1: Claude Codeでコストを抑えるために、ユーザーができる具体的な対策は?
A1: キャッシュ効率を意識したプロジェクト構成だ。Claude Codeは会話履歴を毎回全送信する。頻繁に変更されるファイルや巨大なログをプロンプトに含めすぎない。プロジェクトルートに設定ファイルを配置し、AIの行動指針を固定化する。システムプロンプトの再計算コストを抑えつつ、AIの挙動を安定させる。不要なファイルを除外設定で弾くことも有効だ。
Q2: ハーネスエンジニアリングを導入すると、AIの回答速度は遅くならない?
A2: フック処理が挟まる分、一見すると遅くなる。だが、これは人間が修正する時間を短縮するための投資だ。AIが最初から正しいルールを守るようになれば、手戻りは減る。結果としてプロジェクト全体の開発サイクルは高速化する。AIの思考時間よりも、人間によるデバッグ時間の方が遥かに高コストだ。
Q3: プロンプトキャッシュは、会話が長くなると効果が薄れる?
A3: 薄れる。キャッシュは前方一致が基本だ。会話が長くなり、初期のコンテキストがキャッシュ対象外になるほど恩恵は減る。Claude Codeは自動的にキャッシュ対象を管理している。ユーザーは会話の冒頭に重要な指示を置き、頻繁に変わる情報を末尾に寄せる。会話が長くなりすぎた場合は、一度セッションをリセットしてコンテキストを整理する。
まとめ
インフラとしてのキャッシュと、ガードレールとしてのハーネス。
この両輪を回すシステム設計が、今後のAI開発の常識になる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
