
Claude CodeやOpenClawを「ただのAIチャット」として使っているなら、正直もったいない。本当の価値は、自分の業務に特化したSkillを積み上げて「専用アシスタント」を構築することにある。この記事では、Skillの作成から本番運用・観測・改善・ファインチューニングまでを5ステップで解説する。プログラミング知識がなくても始められる設計だ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
この記事を読む前に用意するもの
- AIエージェントが動く環境(OpenClawやClaude Codeの導入済み環境)
- テキストエディタ(VSCodeでもメモ帳でも可)
- 自動化したい定型作業のアイデアが1つあること
ステップ1:OpenClawでのSkillの基本設計と作成
まず「Skillとは何か」を押さえる。
Skillとは、AIエージェントに特定の業務を覚えさせるための拡張機能だ。OpenClawの場合、構造はシンプルで、「1フォルダ=1スキル」という設計になっている。フォルダの中核は「SKILL.md」というMarkdownファイル1つだけだ。
SKILL.mdの書き方はこうだ。ファイルの先頭にYAMLフロントマターでメタ情報(名前・説明・依存環境など)を定義し、その下の本文にLLMへの指示を自然言語で書く。
たとえば日次レポートを自動生成するSkillなら、手順として「ユーザーに今日の作業内容を質問する」「回答をもとにテンプレートでレポートを生成する」「指定フォルダに保存する」と日本語で書くだけでいい。
コードを1行も書く必要がないのがこの設計の最大の強みだ。エンジニアでなくても書けるし、Gitでバージョンを管理しやすい。営業やバックオフィスの人でも、自分の業務フローをそのまま文章にすれば立派なSkillになる。
まずは日常の定型作業を1つ選んでSkill化するところから始めるのが最適だ。「毎週月曜に同じフォーマットで進捗報告を書いている」「問い合わせへの返信文を毎回似たパターンで書いている」——そういう作業が最初のSkillに向いている。
ステップ2:本番環境でのセキュリティ対策
ローカルで動くSkillを本番環境に持っていく段階で、多くの人がつまずく。
一番重要なのはSkillディレクトリの読み取り専用マウントだ。Dockerでデプロイする場合、Skillsのボリュームマウントには必ず「:ro」(読み取り専用)を付ける。理由は明確で、LLMがSkillの定義ファイル自体を書き換えるリスクを排除するためだ。サードパーティ製のSkillを導入する場合はなおさら重要になる。
書き込みが必要なディレクトリ(ログ保存先など)だけを個別に「:rw」でマウントし、それ以外は全て読み取り専用にする設計が正しい。
次に重要なのがホワイトリスト設計だ。設定ファイルには「allowBundled」という項目があり、ここに使用を許可するバンドルスキルを明示的に列挙できる。デフォルトで全部有効にするのではなく、業務で本当に必要なものだけを許可する。これだけで不要な権限を大幅に削れる。
もう一つ、フォールバックチェーンの設定も必須だ。Skillが処理の途中で止まると中途半端な出力になってしまう。メインのAIモデルが応答しない場合に備えて、異なるプロバイダーのモデルへ自動で切り替える設定を入れておくと安心だ。同じプロバイダーの別モデルをフォールバックに設定しても、プロバイダー障害時には意味がない。異なるプロバイダーを混ぜることがコツだ。
しんたろー:
毎日コードを書いてる身からすると、セキュリティ設定は「後でやろう」にしがちだ。でも本番に持っていく前に読み取り専用マウントだけは絶対やっておくべきだ。
Skillのファイルが書き換えられるリスクは、実際に起きてから気づいても遅い。最初から防ぐ設計にしておくのが一番コストが低い。
ステップ3:運用状況の観測(Observability)の導入
Skillが3つ4つと増えてくると、「どのSkillが実際に使われているか」が見えなくなってくる。
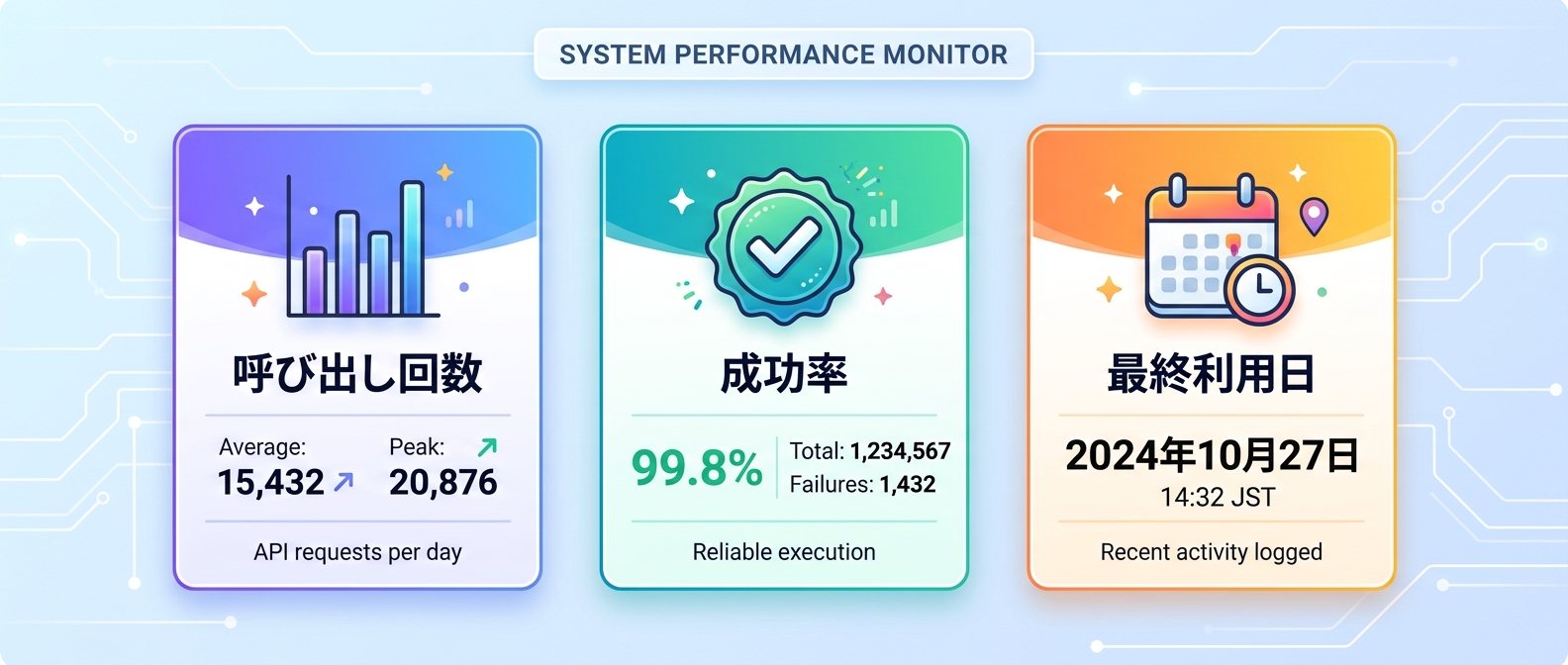
この問題を解決するのがObservabilityプラグインの導入だ。Claude Codeの場合、「claude-skill-analytics」のようなプラグインを使うと、Skillの呼び出し回数・成功率・最終利用日といった最小限の運用メトリクスをJSONL形式で記録・可視化できる。
記録する内容は絞った方がいい。「何をしていたか」を全部ログに残そうとすると管理が重くなる。本当に必要なのは「どのSkillがどれくらい呼ばれ、どれくらい成功しているか」だけだ。最初の段階では欲張らない方が扱いやすい。
このプラグインの価値は利用ランキングを出すことではない。次に何を疑うかが見えることにある。
観測を始めたら、以下の指標を定点観測する。
- 呼び出し回数:どのSkillが実際に活用されているか
- 成功率:エラーが多発しているSkillはどれか
- 最終利用日:長期間呼ばれていないSkillはどれか
ステップ4:Skillの棚卸しとエラー改善
観測データが溜まってきたら、定期的な棚卸しを行う。
棚卸しの判断基準として、以下の2つを使うといい。
| ステータス | 条件 | 意味 |
|---|---|---|
| DORMANT | 30日以上呼び出しなし | 現在のワークフローから外れている可能性 |
| INVESTIGATE | 失敗率25%以上(最低3回呼び出し後) | プロンプトや環境に継続的な問題がある可能性 |
ここで重要な注意点がある。DORMANT=不要、ではない。
使われていないSkillがあったとき、原因は複数考えられる。Skillそのものが不要になったのか、ユーザーへの導線が悪いのか、ワークフローが変わってSkillの存在が忘れられているのか——観測データはその「どこかにズレがある」というシグナルを出しているだけだ。
削除の判断は原因分析の後にする。プロンプトの修正で復活するケースも多い。失敗率が高いSkillは、指示が曖昧すぎる可能性が高いので、手順をより具体的に書き直す必要がある。
1人開発してると、Skillが増えるほど「あのSkill、ちゃんと動いてるっけ」って不安になる瞬間がある。観測の仕組みを入れると、その不安がデータに変わるのが気持ちいい。
気になってるのは、DORMANTシグナルを使ったSkillのライフサイクル管理だ。単純に削除するんじゃなくて、「なぜ使われなくなったか」を分析する習慣が、長期的な運用品質につながるはずだ。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
ステップ5:Skillを活用した対話型ファインチューニング
既存のSkillだけでは対応が難しい特定タスクがある場合、モデル自体のファインチューニングという選択肢がある。
「HuggingFace Skills」は、Claude CodeやCodexなどのコーディングエージェントに「HuggingFaceでモデルを学習する方法」を教えるプラグインだ。このプラグインを導入すると、「このモデルをこのデータで学習して」と自然言語で指示するだけで、学習スクリプトの生成からジョブの実行まで一気通貫で完結する。
実際の流れはこうだ。
- ベースモデルの選定:タスクに合った軽量モデル(LFM2.5-1.2B-JPなど)を選ぶ
- データ準備:学習に使うデータセットを用意し、入出力の向きを確認する
- エージェントへの指示:「このモデルをこのデータで学習して」と自然言語で伝える
- スクリプト生成・ジョブ投入:エージェントが自動でスクリプトを生成し実行する
- エラー修正:エラーが出たらログをチャットに貼るだけでAIが修正・再実行する
非エンジニアでも高度なカスタマイズができるというのがこのアプローチの価値だ。ただし、HuggingFace JobsでGPUジョブを実行するにはProプランへの加入が必要な点は事前に確認しておく必要がある。
HuggingFace Skillsは僕自身はまだ試していないが、「対話だけでファインチューニングを完結させる」というコンセプトは非常に気になっている。
5ステップの全体像まとめ
以下の表で5ステップを一覧で確認する。
| ステップ | 内容 | 難易度 | 優先度 |
|---|---|---|---|
| ステップ1 | SKILL.mdで最初のSkillを作成 | ★☆☆ | 最高 |
| ステップ2 | 本番環境のセキュリティ設定(:ro マウント) | ★★☆ | 高 |
| ステップ3 | Observabilityプラグインの導入 | ★★☆ | 高 |
| ステップ4 | 観測データをもとに棚卸し・改善 | ★★☆ | 中 |
| ステップ5 | 対話型ファインチューニング | ★★★ | 中(特定ニーズ向け) |
初心者はステップ1→2→3の順番で進めるのが確実だ。ステップ4と5はSkillが増えてから考えればいい。
初心者がハマりやすい3つのポイント
つまずき1:SKILL.mdの指示が曖昧すぎる
「レポートを作って」だけでは動かない。「1. ユーザーに○○を質問する」「2. 回答をもとに△△の形式で出力する」のようにステップを番号付きで具体的に書くことが重要だ。
つまずき2:本番でSkillが書き換えられる
「ローカルでは動いたのに本番でおかしくなった」という場合、Dockerのマウント設定を確認する。読み取り専用(:ro)になっていないと、LLMがSkill定義を意図せず変更するリスクがある。
つまずき3:Skillが増えすぎて管理不能になる
Observabilityを入れないまま10個以上Skillを作ると、どれが動いているかわからなくなる。5個を超えたら観測の仕組みを入れるタイミングだと思っておくといい。
よくある質問
Q1. プログラミングの知識がなくてもSkillは作れるか
作れる。OpenClawのSkillの中核となるSKILL.mdはMarkdown形式で書く。設定情報を少し記述した後は、LLMにやってほしいことを「1. ユーザーに作業内容を質問する」「2. 回答をもとにレポートを生成する」のように自然言語(日本語)で指示するだけだ。複雑なプログラミング言語を習得する必要がないため、営業やバックオフィスの非エンジニアでも、自分の業務に合わせた専用Skillを作れる。まずは普段やっている定型作業を1つ選んで文章にするところから始めるといい。
Q2. 作成したSkillがエラーになった場合の対処法は何か
まずObservabilityプラグインを導入してログと失敗率を確認するところから始める。特定のステップで頻繁に失敗している場合は、SKILL.mdのプロンプト指示が曖昧すぎる可能性が高い。手順をより具体的に書き直すと改善するケースが多い。また、APIプロバイダー障害に備えてフォールバックチェーンを設定しておくと、処理が途中で止まるリスクを下げられる。フォールバック先には異なるプロバイダーのモデルを指定するのがポイントだ。
Q3. サードパーティ製Skillを導入する際のセキュリティ上の注意点は何か
外部Skillを導入する場合、LLMが意図せずSkillの定義自体を書き換えるリスクがある。これを防ぐため、DockerコンテナではSkillディレクトリを必ず読み取り専用(:ro)でマウントすることが最重要だ。加えて、設定ファイルの「allowBundled」で業務に必要なSkillだけを明示的に許可するホワイトリスト設計を採用する。デフォルトで全機能を有効にする運用は、不要な権限を与えることになるので避けた方がいい。
Q4. 使わなくなったSkillはどう管理すべきか
Skillが増えたら定期的な棚卸しが不可欠だ。Observabilityプラグインで利用状況を記録し、「30日以上呼び出されていない(DORMANT)」を基準に使われていないSkillを特定する。ただしDORMANT=即削除ではない。使われていない原因が「ユーザーへの導線の問題」や「ワークフローの変化」にある場合、プロンプトを修正するだけで復活することもある。削除の判断は原因分析の後にするのが正しい順番だ。
Q5. コーディングエージェントとの対話だけでモデルのファインチューニングは本当にできるか
できる。「HuggingFace Skills」などの専用プラグインを導入することで、Claude CodeやCodexに「このモデルをこのデータで学習して」と自然言語で指示するだけで、学習スクリプトの生成からジョブ実行まで一気通貫で行われる。スクリプトにエラーが出た場合も、エラーログをチャットに貼り付けるだけでAIが原因を特定・修正・再実行してくれる。ただし、GPUジョブの実行にはHuggingFaceのProプランへの加入が必要なので、事前にプランを確認しておくことが重要だ。
まとめ
AIエージェントの真の価値は、汎用AIチャットとして使うことではなく、業務特化のSkillを積み上げた専用アシスタントを構築することにある。
5ステップをもう一度整理する。
- SKILL.mdで最初のSkillを作る(コード不要、日本語で書くだけ)
- 本番環境のセキュリティを整える(:roマウント+ホワイトリスト)
- Observabilityを導入して運用を可視化する
- 観測データをもとに棚卸し・改善を繰り返す
- 特定タスクにはファインチューニングも活用する
まず今日やることは一つだけだ。自分の定型作業を1つ選んで、SKILL.mdに日本語で手順を書いてみる。それだけで「専用アシスタント」への第一歩を踏み出せる。
SNS運用の定型作業もSkillで自動化したいなら、ThreadPostが役に立つはずだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
