
人気AIプロキシの特定バージョンにマルウェアが混入した。SSHキーやKubernetes設定が根こそぎ盗まれる事態が発生している。
一方で、ローカル完結型のキャッシュツール「llm-devproxy」がv0.2.0へアップデートされた。384次元のベクトルを用いたセマンティックキャッシュを、外部APIに依存せずローカルで処理する。
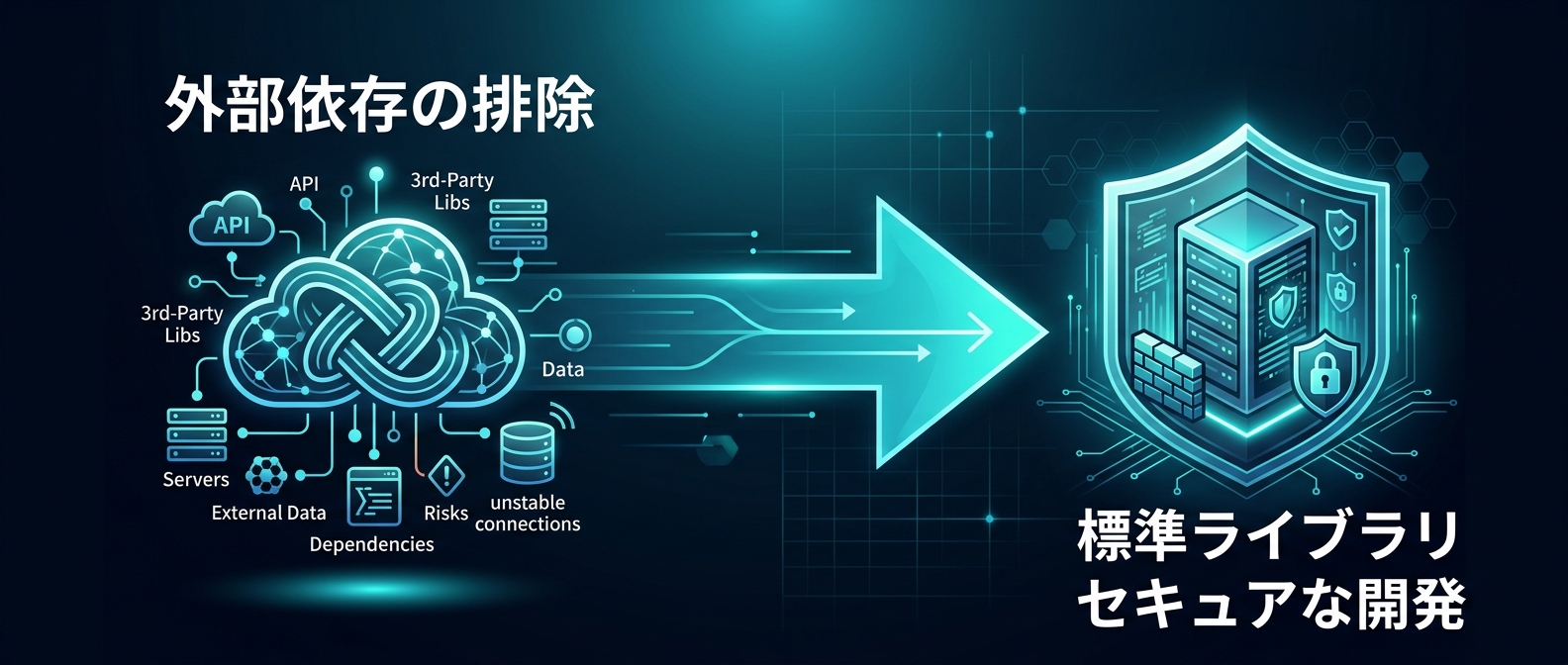
サードパーティへの依存は、1つの脆弱性がシステム全体を破壊するリスクを伴う。依存関係を最小限に抑えたセキュアな開発アプローチが、今後のシステム運用を左右する。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
依存と破壊。AI開発インフラを揺るがす3つの事象
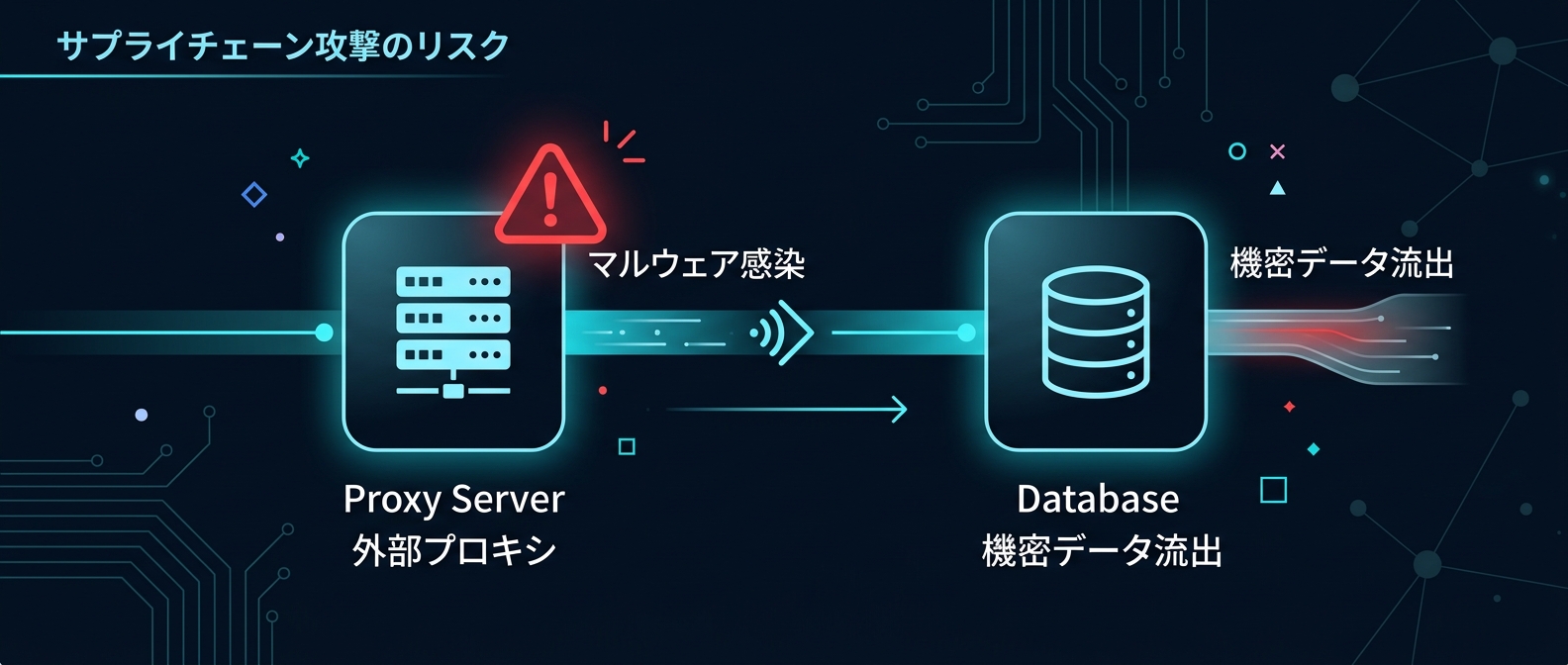
オープンソースのAI言語モデル用プロキシライブラリが、サプライチェーン攻撃の標的になった。特定のバージョン(1.82.7および1.82.8)に、公式リポジトリには存在しない悪意のあるコードが混入された。
このマルウェアは、開発環境からSSHキー、クラウドのクレデンシャル、データベースのパスワードを盗み出す。
さらにKubernetesの構成ファイルまで標的にし、取得したデータを暗号化して第三者のサーバーに送信する。
Kubernetesクラスター全体に自己増殖し、恒久的なバックドアを設置する。コードエディタ内でパッケージがクラッシュしたことで、この巧妙な攻撃が表面化した。
影響を受けた開発者は、直ちに100%の認証情報をローテーションする対応に追われている。多機能な外部プロキシへの過度な依存が、巨大なセキュリティリスクを孕んでいる事実が浮き彫りになった。
時を同じくして、ローカル完結を思想に掲げるLLM開発用プロキシ「llm-devproxy」がv0.2.0をリリースした。最大の目玉は、外部の埋め込みAPIに依存しないローカルでのセマンティックキャッシュ機能だ。
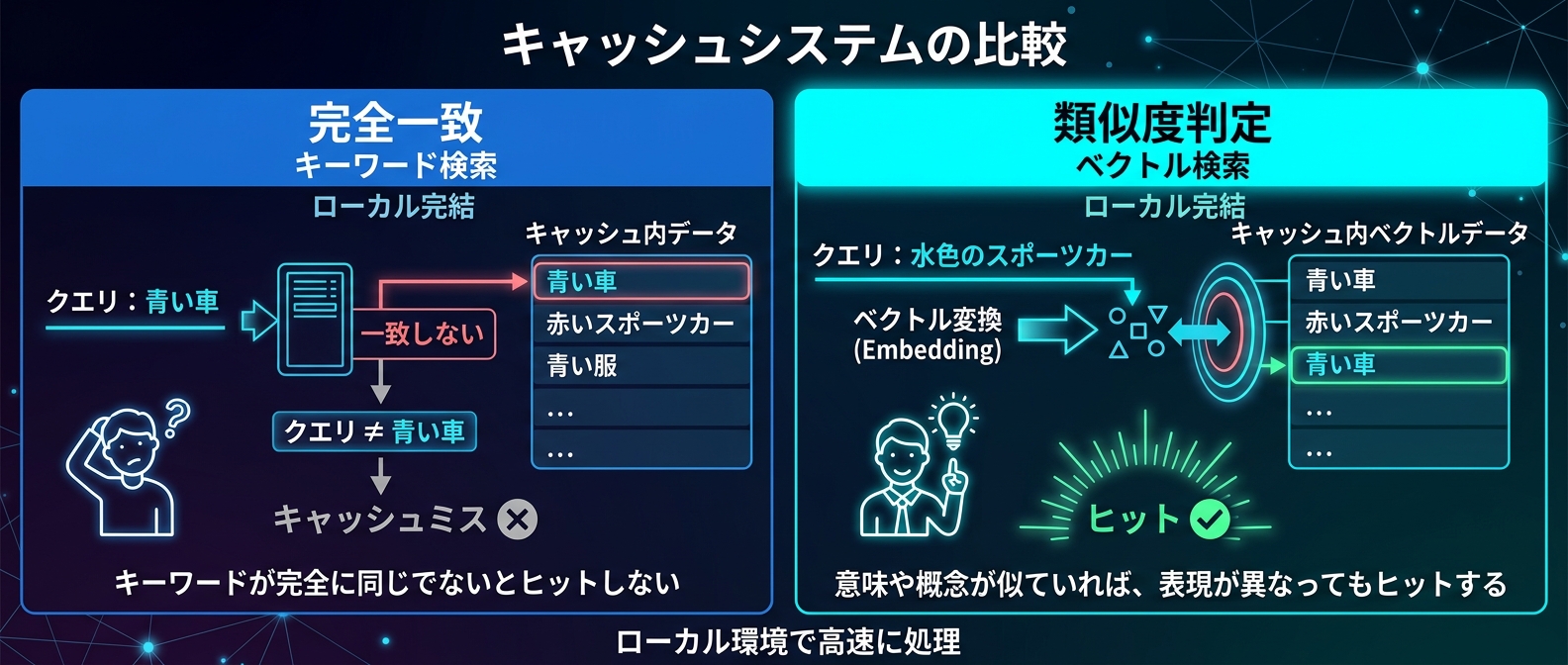
従来の完全一致キャッシュでは、プロンプトの言い回しが少し変わるだけでキャッシュミスとなり、無駄なAPI課金が発生していた。新バージョンでは、プロンプトを384次元のベクトル表現に変換し、意味的な類似度でキャッシュのヒットを判定する。
このベクトル変換と類似度計算を、外部サービスにデータを送ることなくローカル環境で完結させている。機密データを扱う開発において、データ流出のリスクを物理的に遮断できるアプローチだ。
さらに、Pythonの標準ライブラリである「asyncio」を用いた自前での並列化手法が、再び注目を集めている。外部の多機能プロキシに頼らずとも、標準機能だけで十分なパフォーマンスを引き出せる。
100件のテキストを処理する際、同期処理では200秒かかるタスクが、非同期処理なら最遅リクエストの時間である数秒で完了する。依存関係を増やさずに処理速度を95%以上向上させる、堅実な手法だ。
複数の情報源を統合した知見(crossSourceFindings)として、これら3つの事象は一つの明確なトレンドを示している。「外部の多機能ツールに依存するリスク」と「ローカル完結・標準機能による自衛」という、AI開発におけるパラダイムシフトだ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
エージェント時代のサプライチェーン攻撃と防衛線
AIエージェントを活用した開発において、マルウェア感染は従来とは次元の違う脅威をもたらす。Claude Codeのような自律型エージェントは、ワークスペース内のあらゆるテキストファイルをコンテキストとして読み込む。
もし依存ライブラリの中に悪意のあるコードや難読化されたスクリプトが混入していたらどうなるか。エージェントがそれを読み込んだ瞬間、コンテキスト全体が攻撃ベクターへと変貌する。
これは単なる情報漏洩ではない。エージェントがマルウェアの意図を解釈し、開発者の権限を使ってクラウド環境や連携アカウント全体を操作してしまう。
無数のサードパーティ製ツールを導入することは、自室の鍵を無数の見知らぬ人間に預けることに等しい。特にLLMのAPI呼び出しを最適化するプロキシツールは、すべてのプロンプトとレスポンスを通過させる関所だ。
この関所が乗っ取られれば、開発中の機密情報、顧客データ、そしてインフラの制御権までが一度に奪われる。今回のマルウェア感染事件は、その危険性が理論上の話ではなく、現実の脅威であることを証明した。
しんたろー:
Claude Codeにプロジェクト全体を読み込ませる日常だからこそ、このニュースは背筋が凍る。
エージェントがマルウェアのコードを仕様として解釈して自律的に動き出したら、もう人間には止められない。
便利な外部ツールを安易にインストールする癖、本気で見直さないと痛い目を見そうだ。
防衛線は「監査可能な退屈なソフトウェア」への回帰にある。
ブラックボックス化された多機能な外部ツールを捨てる。代わりに、コードの挙動を完全に把握できる軽量なツールや、標準ライブラリを組み合わせたカスタムソリューションを構築する。
AIという最先端の不確実な技術を扱うからこそ、それを支えるインフラは枯れた安全な技術で固める。エージェントの暴走を防ぐための、堅牢な檻を用意する。
ローカル完結のセマンティックキャッシュがもたらすコスト削減
APIコストの削減は、すべてのAI開発者が直面する切実な課題だ。しかし、コスト削減のためにセキュリティを犠牲にしては本末転倒である。
llm-devproxy v0.2.0のセマンティックキャッシュは、このジレンマを見事に解決している。プロンプトの意味を理解してキャッシュを返す仕組みを、完全にローカル環境で実現した。
「Pythonでリストをソートする方法」と「Pythonで配列を並び替える方法」。人間が見れば同じ質問だが、従来のハッシュベースのキャッシュでは全くの別物として扱われる。
結果として、試行錯誤のたびに高額なAPI料金が飛んでいく。llm-devproxyは、このプロンプトを多言語対応の埋め込みモデルを使って384次元のベクトルに変換する。
そして、過去のキャッシュデータのベクトルとコサイン類似度を計算する。類似度が閾値(デフォルトは0.85)を超えれば、外部APIを叩かずにローカルのキャッシュを返す。
この高度な処理を外部の埋め込みAPIを使わずに実行している。ローカルのCPUメモリ上で軽量なモデルを動かすため、データが外部に送信されることは一切ない。
API代を80%削減できたと喜んだ直後、ローカルのCPUファンが爆音で回り始めて焦ったのは内緒だ。
プロンプトの語尾を「〜して」から「〜してください」に変えただけで課金されるの、ずっと気になっていた。
ローカルでベクトル化して類似度判定するアプローチ、データ流出の心配がないのが最高にクール。
うちの環境でも、英語特化の軽量モデルならメモリ圧迫せずにサクサク動かせそうだ。
主要な3つのプロバイダーで全く異なるリクエスト形式も、ツール内部で自動的に正規化される。
開発者は既存のコードを一切変更することなく、プロキシの向き先を変えるだけでこの恩恵を受けられる。完全一致キャッシュとセマンティックキャッシュを組み合わせるフォールバック機能も備わっており、処理速度とヒット率のバランスも絶妙だ。
Web UIによるダッシュボード機能も強力だ。ブラウザ上で直近7日間のAPI使用量や、プロンプトごとのコスト差分を視覚的に確認できる。
どのプロンプトにいくらかかったか。昨日と今日でコストはどう変化したか。プロバイダーの使いにくい管理画面を見に行く必要はもうない。
軽量、ローカル完結、そして監査可能。llm-devproxyのアプローチは、これからのAI開発ツールが目指すべき一つの理想形を示している。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
標準ライブラリによる並列化という最強の武器
外部ツールに頼らずにパフォーマンスを向上させるもう一つの鍵が、Python標準ライブラリ「asyncio」の活用だ。API呼び出しの並列化は、開発効率を大きく左右する。
1件あたり2秒かかるAPI呼び出しを、100件連続で実行する。同期処理のループを回せば、単純計算で200秒(約3.3分)の待ち時間が発生する。
これをasyncioのイベントループで並列化すれば、理論上は最も時間のかかる1回のリクエストと同じ時間で全処理が完了する。数秒の世界だ。
スレッドを使った並列化とは異なり、asyncioはシングルスレッドで動作する。I/O待ちの時間に別の処理を進めるため、コンテキストスイッチのオーバーヘッドがなく、競合状態も起きにくい。
特にLLMのAPI呼び出しのような、ネットワークの待ち時間が大半を占めるI/Oバウンドな処理において、この特性は圧倒的な威力を発揮する。外部の複雑な非同期処理ライブラリを導入する必要はない。
標準機能であるgather関数を使うだけで、複数のコルーチンを同時に実行し、結果をリストとして受け取ることができる。ただし、実務で運用するにはエラーハンドリングの工夫が不可欠だ。
デフォルトの挙動では、100件のうち1件でもエラーが発生すると、処理全体が失敗として扱われてしまう。レートリミットや一時的なネットワークエラーが頻発するLLMのAPIにおいては、これは致命的だ。
例外を結果としてキャッチする設定を行う。エラーが発生したリクエストだけを分離し、成功したデータは確実に保存する。
後から失敗したリクエストだけを再実行する仕組みを作れば、堅牢なデータ処理パイプラインが完成する。依存関係を増やさず、標準の機能だけでここまで堅牢なシステムを構築できる。
監査可能なカスタムソリューションへの移行
これらの事象から、外部依存を極限まで減らし、自分のコントロール下に置ける環境を構築する動きが加速している。
現在使用している外部プロキシや便利ツールの依存関係を見直す。ブラックボックス化されたツールに、強力な権限を持つクレデンシャルを渡していないか確認する。
もし該当するツールを使用していた履歴があるなら、直ちにすべての認証情報をローテーションする。クラウドプロバイダーのアクセスキー、データベースのパスワード、そしてSSHキー。
すべてを無効化し、新しいキーを発行する。少しでも疑わしい挙動があれば、環境全体をクリーンインストールする。
認証情報のローテーション、言葉にするのは簡単だけど実務でやると地獄の作業なんだよな。
でも、これをサボって本番環境のデータベース抜かれたら、一人SaaSなんて一瞬で吹き飛ぶ。
便利だからって中身の分からないライブラリにAPIキーを食わせるのは、もうやめておこう。
コスト削減や速度向上のためのツール選定基準をアップデートする。「多機能で便利」よりも「軽量で監査可能」を最優先する。
llm-devproxyのように、コアな処理をローカルで完結させるツールは非常に有力な選択肢だ。ソースコードの規模が小さく、自分自身で中身を読んで挙動を理解できる。
並列処理やリトライロジックも、可能な限り標準ライブラリを使って自前で実装する。asyncioの基礎を固め、レートリミットを制御するセマフォの仕組みを理解する。
一見すると遠回りに思える。しかし、AIエージェントがコードを読み書きし、複雑なシステムを自律的に構築していくこれからの環境において、インフラの透明性は最後の命綱になる。
自分の手で書き、自分の目で監査できるコードだけを信頼する。それが、サプライチェーン攻撃からプロジェクトを守り、安全にAI開発を進めるための道だ。
開発現場のリアルな疑問に答えるFAQ
Q1: セマンティックキャッシュとは何ですか?通常のキャッシュとの違いは?
通常のキャッシュは、リクエストのハッシュ値が「完全一致」した場合のみ機能します。一文字でも違えば別物扱いです。一方、セマンティックキャッシュはプロンプトを多次元のベクトルに変換し、意味的な類似度で比較します。微妙な言い回しの違いがあっても「同じ意味」と判定してキャッシュを返すため、試行錯誤中のAPIコストを90%以上削減できます。
Q2: asyncioを使ったAPIの並列呼び出しで、一部のエラーで全体が止まるのを防ぐには?
標準の機能で並列実行する際、引数に例外を許容するフラグを指定します。これにより、一部の処理でエラーが発生しても全体がクラッシュすることはありません。エラーオブジェクトが結果のリストにそのまま格納されるため、後から成功したデータと失敗したデータを個別に振り分け、エラー分だけを再処理する堅牢なフローを構築できます。
Q3: 開発ツールのマルウェア感染事件を受けて、どのような対策を取るべきですか?
該当するツールを使用していた場合は、直ちにすべての認証情報をローテーションします。今後の根本的な対策として、不要な外部依存を減らすことが必須です。ローカル完結型の軽量ツールを選定するか、標準ライブラリを用いた自前実装など、コードの中身を自分で監査できるカスタムソリューションへの移行が有効な手段となります。
まとめ
便利すぎる外部ツールは、プロジェクトの心臓を握る時限爆弾だ。ローカル完結のツールと標準ライブラリの力を信じ、依存関係の少ない堅牢なインフラを自分の手で構築する。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
