
プロンプトエンジニアリングは終わった。
AI開発の最前線では、指示を長くするアプローチはすでに捨てられている。
1.5万行のコード変更。
15〜25%の開発者時間。
AIが生成する大量のコードと資料を人間がさばくのは物理的に不可能だ。
今起きているのは、AIへの指示出しの工夫ではない。
AIが自律的に動くための環境設計へのシフトだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
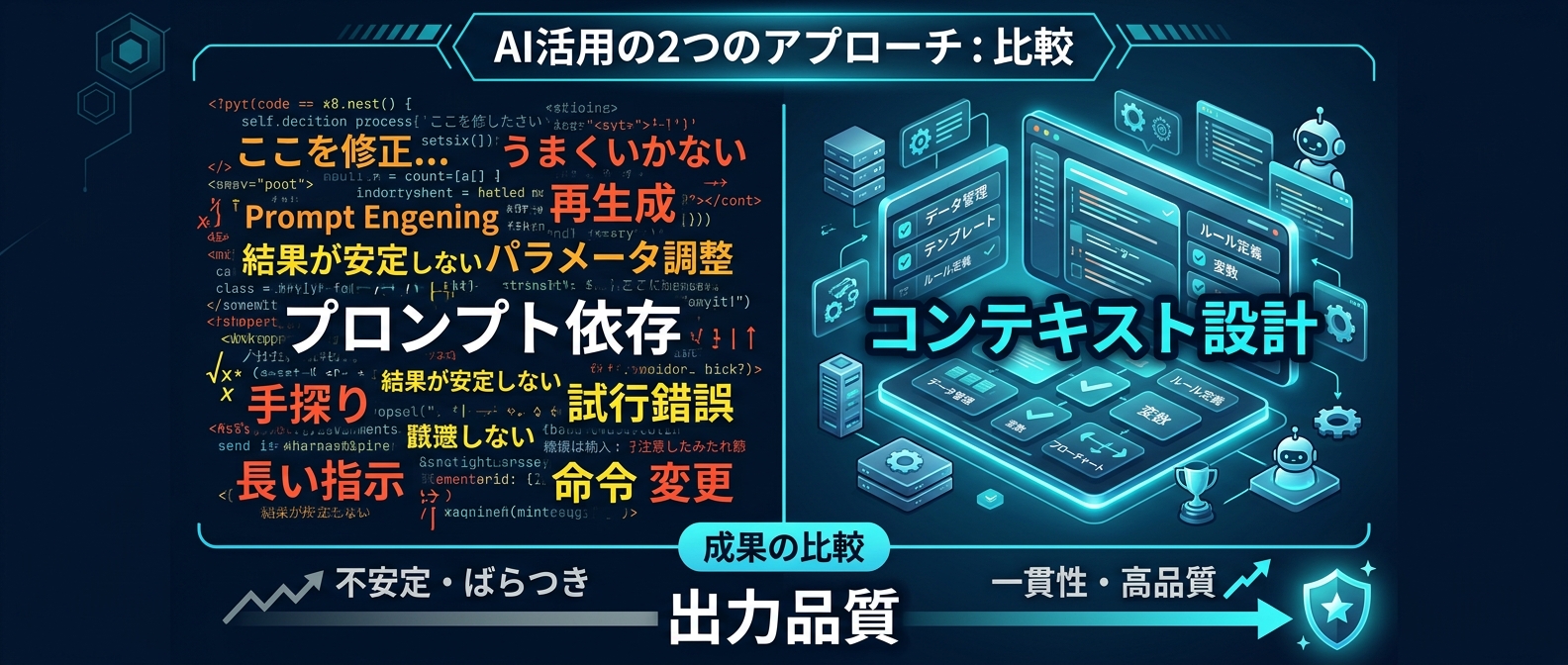
AIの出力品質を決めるのはコンテキストエンジニアリング
AIエージェントの活用が次のフェーズに入った。
スライド生成、コーディング、コードレビューのあらゆる領域で変化が起きている。
AIのアウトプット品質を決めるのはプロンプトではなくなっている。
AIが読み書きしやすい環境を事前に整えるコンテキストエンジニアリングが成否を分ける。
生成AIでスライドを作ると作成時間は10倍速くなる。
しかし、そのまま会議で使える品質になるかは別の話だ。
事実誤認、情報漏えい、権利処理のミスが社内外向け公開資料での事故の主因になる。
AIは見栄えだけ整えても、中身が薄いスライドを返す。
品質を安定させるには、出力形式を固定化する。
Marp markdownやPPTXGenJSのような構造化フォーマットを指定する。
1ページあたり1メッセージを徹底する。
図は1つ、要点は2〜3行に絞る。
15分で説明する資料を作る場合、要点は120字以内に収める。
根拠となる数字を入れる。
これらを固定化することが、ブレを防ぐ手段だ。
見た目の最終調整やアニメーションは、人間が後でやればいい。
Microsoft 365 CopilotやGoogle スライド、CanvaのMagic Presentationsでも同じだ。
どの道具も素材の選別と人の判断を置き換えられない。
Codex、Claude Code、Gemini CLIのようなCLI型エージェントはソースを作る方が安定する。
AIコーディングの現場でも全く同じことが起きている。
モデルの性能比較はもう意味がない。
どれが強い、どれが速い、長文脈に強いのはどれかという議論は現場で差を生まない。
開発環境がエージェントに何を見せているかが全てだ。
コードベースの入口が整理されているか。
読むべき文書が揃っているか。
ブラウザ操作がスクリーンショット頼みではなく、道具として公開されているか。
変更後の確認手順が再利用できる形で残っているか。
ここが雑なままだと、どんなに強いモデルを使っても結果は安定しない。
逆にここが整うと、同じモデルでも急に仕事がまともになる。
フレームワーク側も動き始めている。
Next.jsはAGENTS.mdをリポジトリに配置する。
バージョンと対応したドキュメントをまとめる。
エージェント向けの評価ツールまで出す。
人間向けのDXから、エージェントが誤読しにくい開発面の設計へと軸足が移っている。
コードレビューの負荷は爆発的に上がっている。
AI支援やエージェント駆動の開発が広がった結果だ。
コードは大量に生成されるようになり、レビューと検証が追いつかなくなった。
実装速度は一気に上がるが、アウトプットを人が読んで検証する工程だけが昔のまま残る。
ここに大きな非対称性が生まれる。
1.5万行のプルリクエストを人間だけで読み切るのは無理だ。
従来でもコードレビューには開発者時間の15〜25%が使われていた。
AI時代にはその負荷がさらに重くなる。
PR数が増え、不具合候補も増えるなら、レビューは遅いだけでなく取りこぼしやすくなる。
AIに差分だけを読ませても、表面的な指摘しか返ってこない。
Issue、周辺コード、コードグラフ、過去のPR、社内ガイドラインを絞り込んでAIに渡す仕組みが必須だ。
レビュー品質はモデルの賢さではなく、文脈の最適化で決まる。
生成の高速化に見合うレビュー基盤が必要だ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
環境設計がAIの自律性を引き出す
プロンプトで全てを解決しようとするアプローチは限界を迎えている。
指示を長くする、注意事項を足す、失敗したらさらに追記するループは必ず途中で破綻する。
AIが失敗する理由は、知能の不足ではない。
観測面と操作面の不足であることがほとんどだ。
この状態でプロンプトだけ磨いても、改善はすぐ頭打ちになる。
先に地形を作るアプローチが求められる。
モデルを替える前に、読めるようにする。
触れるようにする、引き継げるようにする。
Claude Codeで毎日コードを書いていると、この変化を痛いほど感じる。
AIに賢く働いてほしいなら、AI向けのインターフェースを用意するしかない。
従来の開発環境は、人間の暗黙知にかなり依存していた。
どのファイルから読むか、どのディレクトリが本筋か、命名にどういう文脈があるか。
チームにいる人間なら何となく分かるが、AIには分からない。
空気は読めない。
スライド生成でもコーディングでも、アプローチは全く同じだ。
制約と文脈を外部化する。
プロンプト内に「不明点があれば先に3つ質問して」と組み込む。
過度な断定や未確認の数値を禁止する。
これで初稿の事故率は下がる。
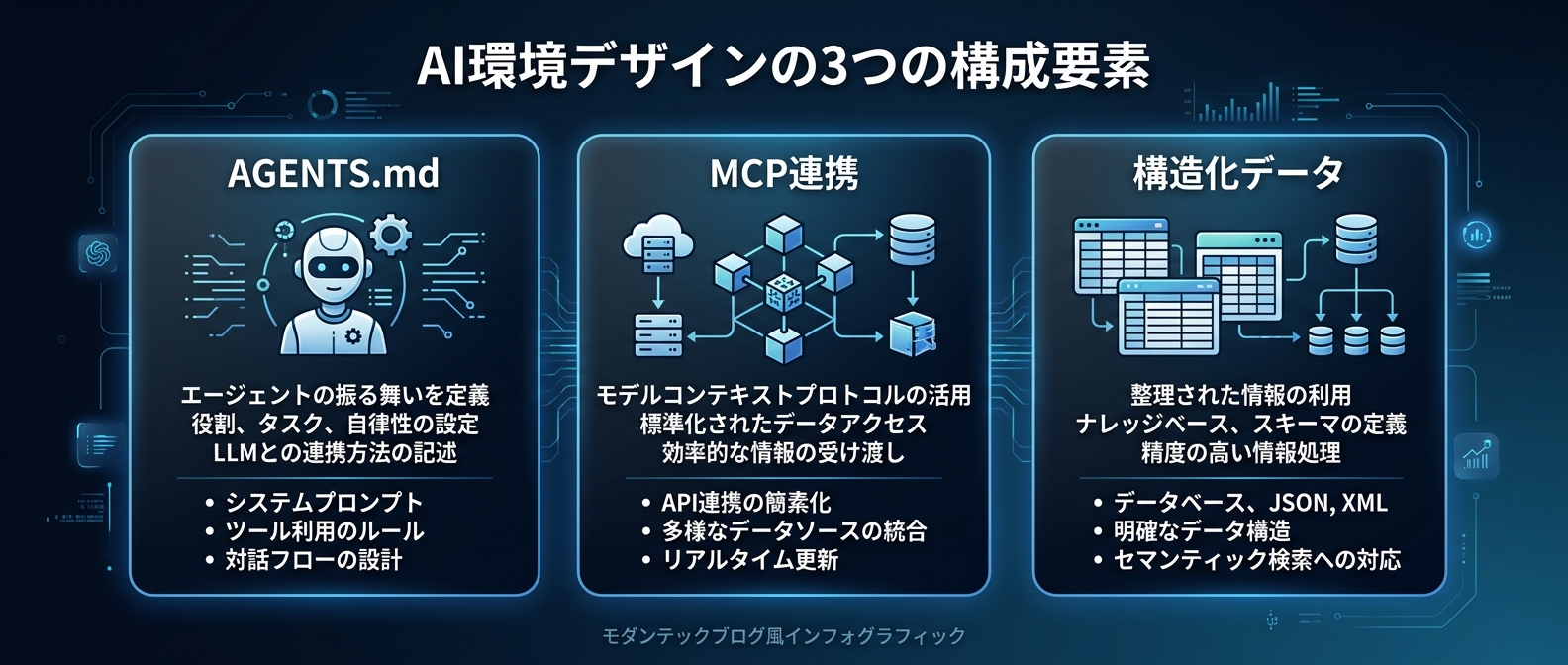
AGENTS.mdにディレクトリ構成の意図やコーディング規約を書く。
これでAIの誤読は消える。
賢いモデルを待つことではない。
読ませ方を整えることだ。
入口を作る。
前提を外に出す。
参照順をはっきりさせる。
ブラウザ操作の自動化も変わった。
これまではスクリーンショットを渡してAIに推測させていた。
DOMを少し渡し、あとはエージェントに任せる。
動くことはあるが、トークンは重いし、操作の意味もブレやすい。
今はWebMCPやagent-browserを使ってUIを使える道具として公開する流れだ。
どのボタンが何をするのか。
フォームのどこに何を入れるのか。
確認すべき状態はどこに出るのか。
操作契約を外に出せば、ブラウザは読解が必要な画面から扱えるインターフェースになる。
APIを設計するだけでは足りない。
AIに使わせるUI面まで設計対象に入ってくる。
しんたろー:
Claude Codeに複雑なリファクタリングを頼むと、たまに迷子になる。
プロジェクトのルートにルールを書いたマークダウンを置くアプローチが気になっている。
迷子になったClaude Codeを慰める時間が一番無駄だった。
実行基盤の設計も求められる。
最近の開発環境は、補完を返すだけの箱ではない。
計画を立てる。
複数ファイルを触る、テストを回す。
MCPを呼ぶ。
途中の判断を保持する。
そういう一連の流れを引き受けるランタイムに近づいている。
ここで効くのも、やはりモデル単体の性能ではない。
どのツールを呼べるか。
失敗したとき、どこまで戻れるか。
判断の根拠がどこに残るか。
人間がどこで止めるか。
基盤が弱いと、エージェントは毎回その場しのぎになる。
たまたま当たることはあっても、再現しない。
コードレビューの文脈最適化はさらにシビアだ。
関連情報を何でも詰め込めばいいわけではない。
MCPや各種ナレッジソースをつなぐと、関連しそうな情報は大量に取れる。
意味的に近いことと、そのタスクに本当に必要であることは別だ。
情報量が多すぎると、モデルは途中の指示や重要な前提を落とし始める。
コンテキストエンジニアリングは検索問題であると同時に、最適化問題だ。
接続関係を見極めたうえで、少量の追加情報を足す。
これが最も効率よく同じ問題を検出できる方法だ。
良いレビューとは、情報量の勝負ではない。
必要な文脈を正しい密度で渡せているかどうかで決まる。
チームごとのルール、過去の指摘、受け入れられたコメントの違いを学習する。
TypeScriptファイルはこう見る。
ワイルドカードimportは避ける。
以前の方針を撤回した、といった変化を取り込み続ける。
これでレビューはようやく現場に馴染む。
人間のフィードバックを通じて継続的に育つ運用ループが求められる。
出したコメントに対して人が反応し、そこから使えるルールを抽出する。
AIのレビューシステムは、一発で当てる賢さではない。
学習可能な仕組みが勝負を決める。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
エージェント向けDXの整備
AIエージェントをチームに入れる際、単にツールを入れてプロンプトを共有するだけでは終わらない。
AIのための開発環境を整備するスキルが求められる。
モデル名だけ見て最近のAIはいまいちと言っていると、問題のかなり大きな部分を見落とす。
まず、リポジトリにエージェント向けのガイドラインを置く。
ファイル名はAGENTS.mdでもCLAUDE.mdでもGEMINI.mdでもいい。
そこに前提条件をすべて書き出す。
使用技術のバージョンと制約。
ディレクトリ構成の明確な意図、プロジェクト固有の命名規則。
避けるべきアンチパターンと過去の失敗。
外部APIの呼び出しルール。
テストの実行手順と期待されるカバレッジ。
デプロイ前の必須確認項目。
用語集による表記ゆれの防止。
これだけで、AIのアウトプットは安定する。
次に入出力を構造化データで設計する。
人間に読ませる差分ではなく、AIが処理しやすいフォーマットを用意する。
スライドならマークダウン。
データならJSON。
見た目の最終調整やブランド監修は人間が後でやればいい。
リスクチェックの体制も自動化に組み込む。
社外公開前提なら、内部情報や顧客名を完全に除去する。
引用元があるなら、必ずリンクを脚注として明示する。
図表や画像の利用規約を事前に確認する。
未確認の数値は出力させず、TODOと明記させる。
配布前にレビュー担当を必ず2名置く。
Claude Codeが勝手にドキュメント読んで正解のAPI叩いてくれた時の快感は忘れられない。
なお、その直後に別のバグを埋め込まれて真顔になった。
人間が読むための美しいコードより、AIが迷わないベタなコードの価値が気になっている。
レビュー体制も根本から変える。
AIに差分だけを投げるのはやめる。
関連するIssue、アーキテクチャ文書、依存ライブラリの情報をセットにする。
ただし、必要十分な量に絞る。
コンテキストエンジニアリングの設計が、システムの品質を直撃する。
フロントエンドの設計思想も変わる。
APIを設計するだけでは足りない。
AIに使わせるUI面まで設計対象に入ってくる。
ここを意識しているチームと、まだスクリーンショット前提で考えているチームでは差がつく。
実行基盤の質を見極める。
どのツールを呼べるか。
失敗したときにどこまで戻れるか。
判断の根拠がどこに残るか。
基盤が弱いと、エージェントは毎回その場しのぎになる。
モデルのランキングを眺めるのはやめて、環境の構築に手をつける。
毎回の長い指示を繰り返さなくて済むようにする。
手順、テンプレート、補助スクリプト、MCP連携をまとめて再利用する仕組みを作る。
AIに何を見せ、何を触らせ、どこまで判断できるようにしているか。
これを設計しない限り、AIコーディングはいつまでも不安定なままだ。
よくある質問
AIエージェントにプロジェクトの文脈を理解させるには、具体的にどうすればよいですか?
リポジトリのルートにAGENTS.mdやCLAUDE.mdといったエージェント向けのガイドラインファイルを配置する。
ここにディレクトリ構成の意図、コーディング規約、使用技術のバージョン、避けるべきアンチパターンを記述する。
AIは空気を読めない。
暗黙知をすべて言語化して外部に出す。
これでAIが毎回前提条件を誤読するのを防ぎ、出力のブレを減らすことができる。
AIに資料やコードを生成させる際、プロンプトがどんどん長くなってしまいます。どう改善しますか?
プロンプトで全てを制御しようとするのは限界だ。
指示を長くする代わりに地形を整えるアプローチに切り替える。
出力形式をマークダウンのような構造化フォーマットに固定する。
必要な背景情報をMCP経由で外部から取得させる。
あるいはプロンプト内に「不明点があれば先に3つ質問して」といった確認プロセスを組み込む。
これで指示をシンプルに保ったまま、事故を防ぐことができる。
AIを使ったコードレビューで、表面的な指摘ばかりでバグを見つけてくれません。原因は何ですか?
変更された差分だけをAIに読ませていることが原因だ。
実務のバグは、周辺コードやIssueの要件、過去のPRの文脈との不整合から生まれる。
AIレビューの品質を上げるには、差分だけでは足りない。
関連するIssue、アーキテクチャ文書、依存ライブラリの情報などを集める。
そして、それを必要十分な量に絞ってAIに渡す仕組みが求められる。
レビューAIにリポジトリ全部食わせたら、関係ない設定ファイルに文句を言い始めた。
AIに説教される筋合いはない。
必要な情報だけをピンポイントで渡す検索精度がどう進化するのか気になっている。
プロンプトから環境設計へのパラダイムシフト
プロンプトの工夫はもう限界だ。
AIが最大限のパフォーマンスを発揮できる環境設計こそが、次の開発者の主戦場になる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ

なぜClaude Codeはプロンプト一発回答をやめたのか。開発者が対話で思考を深めるべき訳を徹底解説
